Spark源码学习: stage的划分方式
注: 本文的思考和理解可能还不够完善, 毕竟知识水平有限, 还是作学习记录和思路参考吧, 随时可能修改和更新. 如有错误, 恳请更正
之前学习Spark的时候, 关于宽窄依赖以及stage划分, 一直都知道几句话:
- 宽依赖和窄依赖的一个重要区别是有无shuffle
- 根据宽依赖来进行stage划分
- 在DAG中进行反向解析, 遇到宽依赖就断开, 遇到窄依赖就把当前的RDD加入到当前的阶段中
- 以及一幅经典的图
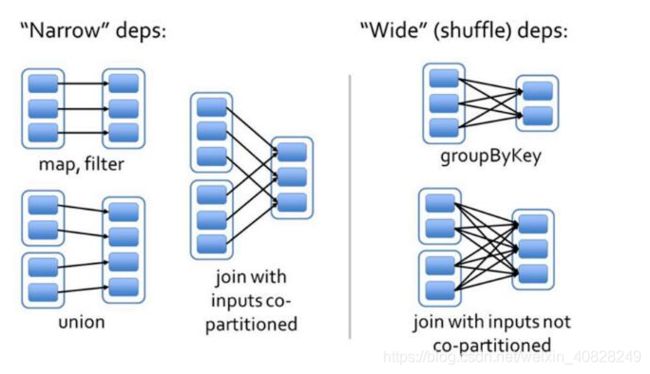
虽然知道了, 但还是尽量要知其所以然的. 学习源码的设计思想也是学习中挺好的过程
接下来, 直接看涉及stage划分的这个方法吧
这个方法定位起来也很简单, 写一个Action操作, 比如foreach(println), 然后按照调用的一个个方法去找就行了
先说一说我在这段stage划分源码中看到的设计吧:
1. 用HashSet对stage和RDD去重, 防止重复计算, 并且HashSet提高了性能
2. 构建一个stack来进行递归寻找父stage, 代替递归方法的调用, 免除了寻找父stage的长过程中, JVM发生StackOverflowError的可能性
3. 用DFS遍历的方式来寻找父stage
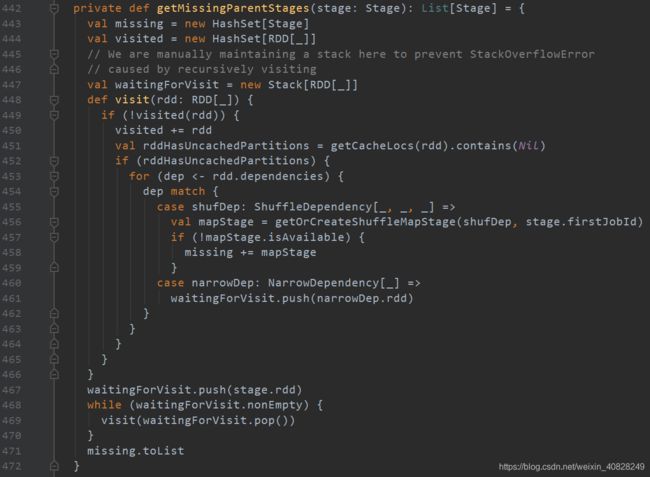
先看第一行. 传入的参数是Stage, 调用这个方法的时候传入的stage叫做finalStage. 什么意思呢? 顾名思义, 最后一个stage. 也就是说, 传入最末端的那个stage, 从它开始寻找父级stage(人家方法名字就叫getMissingParentStages, 也很好理解). 返回的值是List[Stage], 看来是一堆stage
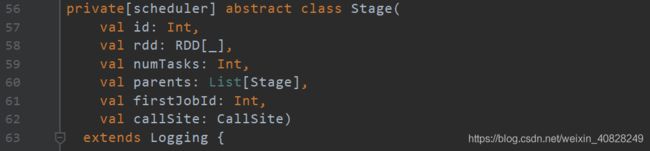
此时有必要看一下Stage的构造器, 比较重要的是它包括了一个RDD集合 & 一个parents集合(指的是父级和父级的父级们, 不是父母的意思) & 一个firstJobId, 后面都会用到
这里, 有必要结合这幅图理一下几个概念:
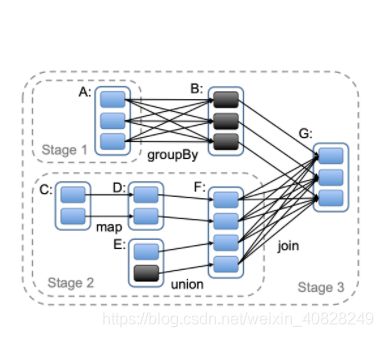
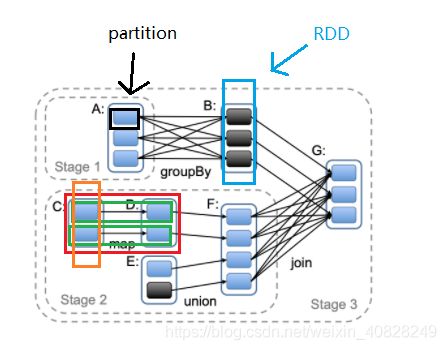
- task. 就是右图中两个绿色框内的部分, 表示partition到partition的过程
- taskSet. 就是右图中红色框内的部分, 由一系列的task组成, 表示从RDD到RDD的过程
- taskSet = job
- stage中可以有不止一个RDD, 它们之间的转换过程就是job
- first job. 在stage2中, 从C到D的过程就是first job, 而D到F就不是
接着往下看, 方法的第二行和第三行定义了两个HashSet, 一个叫missing, 一个叫visited
![]()
根据它们的变量名和集合属性类型一看, 就大概可以猜一下:
7. missing: 丢失中. 顾名思义, 存入的应该是一个个丢失的stage(被找回来那就加进来)
8. visited: 遍历过. 顾名思义, 存入的应该是遍历到的stage, 以RDD集的形式存储, 那也就是一个stage下的所有RDD了
为什么用Set而不是List? 因为Set是去重的. 去重的原因就是, 一个RDD可能被多个子RDD依赖(说的就是宽依赖), 这时候如果已经加入过这个父RDD, 第二个以及之后的子RDD不需要再走一遍这个父RDD, 还是结合图举例来说:
- 在窄依赖的这些场景下, 一个父RDD只会指向一个子RDD. 那么从子RDD反推的时候, 不会把一个父RDD推导多次. 这时候用List也可以满足需求
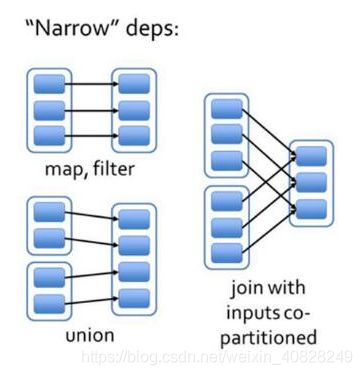
- 在宽依赖的这些场景下, 一个父RDD会指向多个子RDD. 那么从子RDD反推的时候, 是有可能把一个父RDD多次推导的(通过不同子RDD的Lineage血缘关系推导过来). 这时候就必须要去重了, 因为对一个RDD进行重复的血缘关系计算是完全没必要的, 浪费时间也浪费性能. 这可是实时计算, 时间和内存性能都是很宝贵的
(重复计算RDD血缘关系有可能还有其他很重要的弊端, 不过我暂时还没有思考到)
再想一个问题, 为什么是HashSet而不是别的Set呢? Set都是去重的呀
我认为应该是出于性能效率考虑. 毕竟理想情况下, HashSet的复杂度是O(1), 足够快, 满足Spark实时计算对时效性的需求
接着往下看, 源码第四行定义了一个Stack

根据名字可以猜测它会存储已经到达的Stage中的RDD. 用的是Stack而不是Queue, 那就是应该把最新遇到的加进去, 类似于DFS(Depth First Search), 深度遍历. 确实, 根据RDD血缘关系去寻找所有父RDD很像一个DFS的过程
但是, 这里需要格外注意它的注释!它的设计思想非常值得深入思考
它说, 手动地维护一个栈, 以防止递归调用导致StackOverflowError
为什么这么做呢? 这里有几个知识点和思路:
- 因为Scala和Java一样, 都是JVM系的语言, 所以Scala也是构建于JVM之上, 编译执行依靠JVM是必然的
- JVM中, 方法的执行是依靠虚拟机栈和栈帧来实现的, 方法执行会有栈帧入栈, 方法执行完毕会将对应的栈帧出栈, 这样就实现了"最新调用的方法最先结束"这样一个流程
- JVM给虚拟机栈分配的空间是有限的, 一次次递归调用方法, 将方法的栈帧加入虚拟机栈却迟迟没有出栈的操作的话, 栈溢出是必然会出现的(这也是递归函数写错时经常发生的)
- Spark Streaming中RDD的Lineage可能非常长. 根据checkpoint的设计思想来说, RDD的Lineage可能是非常非常长的, 所以需要checkpoint来及时"切断"对吧(我另一篇文章也有解析官网的checkpoint机制介绍). 所以说, 正常的寻找父RDD过程, 可能都会引起栈溢出
- 栈溢出的直接后果就是程序终止, 也就是Spark Streaming的Application停了! 但是数据流并不会停下, Kafka也依然在传输数据. 如果Application重启回来, 可能还需要处理Kafka的offset等一系列操作, 非常麻烦
- 虽然可以通过-Xss这个参数去调节(要在程序运行前配置), 但是如何在程序运行前就事先知道一个Spark Streaming中RDD的Lineage有多长?数据流可是未知长度的. 如果调节得非常大, 以至于几乎不可能栈溢出的话, 那么不必要的内存空间占用可太多了(因为其他线程的虚拟机栈也将耗费这样大小的内存资源). 内存这种珍贵的资源, 不应该这样使用
- 相比于栈内存, JVM的堆内存是更好管理和优化的. new出来的对象都会存放在堆内存
综上所述, 是不是就能很直观地看出来, 这一步"new一个堆内存的stack来进行递归函数的实现"设计有多厉害? 对我来说, 读懂这行代码之后属实有点惊讶
然后就是核心的函数了, 第五行的visit函数
![]()
这就和Java中的增强型for循环一样, 遍历RDD集中的每个rdd(为了避免误解, 下面用大小写来区分, 就根据这个变量声明). 可以看出它是基于RDD集的寻找, 如果当前遍历的rdd已经在visited这个HashSet中加入过了, 那就跳过
如果rdd没有遍历过, 那就走这个函数里的内容. 先将这个新rdd加入到visited中, 表示已经遍历过了, 后面无论多少次掏出这个rdd, 都跳过. 然后看到调用了一个getCacheLocs()方法, 应该是查看缓存的位置
![]()
看一下怎么用的
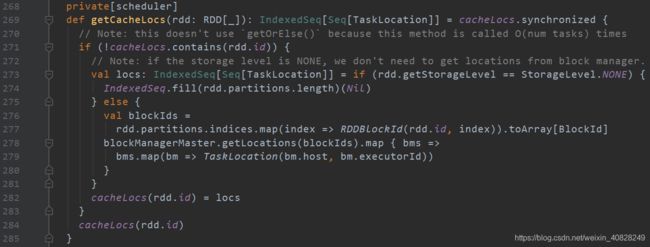
对于这个getCacheLocs()方法, 大概就是: 如果这个rdd存在于cacheLocs这个HashMap(相当于一个缓存)中, 那就直接返回这个值. 如果没有, 先看存储等级是不是NONE, 如果是那就不需要去block manager找到对应的位置; 如果不是NONE, 那就根据rdd和partition所组成的blockId, 去block manager上定位到它, 然后分配好处理它的host以及executor, 最后把这个rdd存进缓存里, 再把这个缓存作为返回值输出(有点绕, 但是核心思想就是把它读进缓存并准备操作它)
频繁用到了一个cacheLocs, 看看它是什么

是一个HashMap, key是rdd的id. value是一个数组, 数组的下标是这个rdd下的所有partition编号, 每个下标存储的内容是对应partition的缓存地址, 以一个TaskLocation类定义. 它还说对这个map的所有操作都需要是同步的(应该是因为HashMap线程不安全的问题, 但是为什么不用ConcurrentHashMap就不知道了. 在调用的时候有加synchronized, 但似乎直接用ConcurrentHashMap就可以解决, 这里我不是很懂)
看一下这个TaskLocation类

翻译一下就是, 这个类记录着一个task的运行位置(其他的注释暂时忽略, 大概说的是未来新版本可能的改进方向), 这个运行位置用host来标识
有个概念: task是parititon之间的转换的过程, 一次转换就是一个task
BlockId这个类是这样的: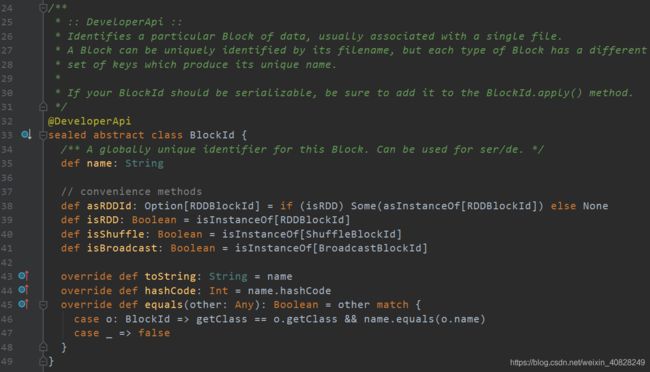
可以看到有RDD和Shuffle的概念, 还重写了hashCode(), 那刚刚缓存是HashMap, 这两者一定有关了
回到那行源码
![]()
代码的末尾还有一个contains(Nil), 看一下
![]()
![]()
乍一看好像什么信息都得不到. 好吧, 搜一下Nil是什么意思

那正常来说, if语句里的内容都可以走下去的
接着看if语句里面是什么
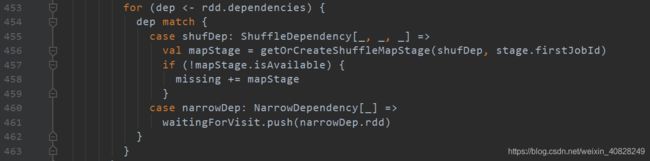
对rdd的每个dependency, 根据不同情况判断:
-
如果是ShuffleDependency(也就是宽依赖, 在源码中都叫ShuffleDependency), 那就获取它的map stage, 如果它没有map stage那就根据当前stage的第一个jobId以及对应的这个ShuffleDependency, 去建立出这个map stage
什么意思呢?- map stage就是shuffle之前的那块, 一个stage可以由shuffle划分为map stage和reduce stage
- 后一个stage的第一个job(job就是task的合集), 就是与前一个stage的ShuffleDependency直接连接的位置
然后有个isAvailable的判断

那么这个map stage就是从丢失状态变成了找回的状态了, 于是把它加入missing这个HashSet中
-
如果是NarrowDependency(也就是窄依赖, 在源码中一共有三种窄依赖的体现方式, 可以去看看)
将这个依赖关系对应的RDD加入到waitingForVisit这个Stack中
不过怎么好像没调用这个visit()方法呢??? 是的, 还没调用
(我个人觉得, 源码这里是不是先后顺序放反了… 感觉把visit()函数放下面好像更顺畅点)
看visit()下面紧跟着的代码:
先把这个RDD入栈

当这个栈不为空时, 对每个元素调用上面的visit()方法. 这是不是很经典的DFS操作? 所以我觉得是不是先后顺序放反了… 不过在前在后的结果都一样, 而且这由提交源码的人说了算, 他肯定比我厉害多了. 我只是根据自己的知识范围合理考虑一下
最后, 把missing这个HashSet转换成List, 返回给调用的函数
![]()
这么一看, 是不是好像只找了一个Stage? 是的. 那么看看调用它的函数做了什么
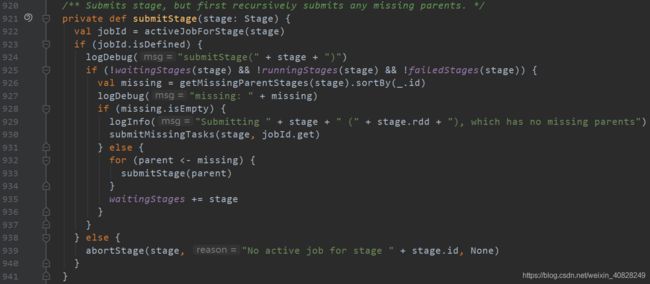
注意它在第926行调用了. 然后会进行判断missing是不是为空
- 如果为空
- 则标志着"它已经没有丢失的父stage了", 也就是说它就是RDD的Lineage血缘关系中, 最根源的那个(相当于大祖宗, 大祖宗不能再往前追溯了)
- 然后直接提交task. 只有当所有的血缘关系都就绪的时候才能调这个方法, 此时, 这个task现在就可以进行(不深入了, 要讲的话又是特别长的一大段)

- 如果不为空
- 对missing里面的所有父stage, 递归地调用submitStage()这个函数, 那么也就是会找出所有的stage, 根据ShuffleDependency / NarrowDependency这个RDD之间的Lineage血缘关系, 直到没有与父RDD的Dependency为止(即没有父RDD了, 也就是最根源的那个RDD)
- 将这个stage加入到waitingStages这个HashSet中. 注释也告诉我们了, 里面存放的是需要运行但它的父stage还没有完成的stage, 相当于等着了

至于什么时候会移除waitingStages里面的stage呢? 我猜应该是任务提交后, 在开始运行这个stage之后就可以释放. 至于具体是什么, 有精力的话请自行研究吧… 本文的主题结束了