图像分割之(三)从Graph Cut到Grab Cut
图像分割之(三)从Graph Cut到Grab Cut
http://blog.csdn.net/zouxy09
上一文对GraphCut做了一个了解,而现在我们聊到的GrabCut是对其的改进版,是迭代的Graph Cut。OpenCV中的GrabCut算法是依据《"GrabCut" - Interactive Foreground Extraction using Iterated Graph Cuts》这篇文章来实现的。该算法利用了图像中的纹理(颜色)信息和边界(反差)信息,只要少量的用户交互操作即可得到比较好的分割结果。那下面我们来了解这个论文的一些细节。另外OpenCV实现的GrabCut的源码解读见下一个博文。接触时间有限,若有错误,还望各位前辈指正,谢谢。
GrabCut是微软研究院的一个课题,主要功能是分割和抠图。个人理解它的卖点在于:
(1)你只需要在目标外面画一个框,把目标框住,它就可以完成良好的分割:

(2)如果增加额外的用户交互(由用户指定一些像素属于目标),那么效果就可以更完美:

(3)它的Border Matting技术会使目标分割边界更加自然和perfect:
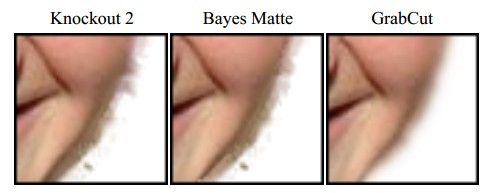
当然了,它也有不完美的地方,一是没有任何一个算法可以放之四海而皆准,它也不例外,如果背景比较复杂或者背景和目标相似度很大,那分割就不太好了;二是速度有点慢。当然了,现在也有不少关于提速的改进。
OK,那看了效果,我们会想,上面这些效果是怎么达到的呢?它和Graph Cut有何不同?
(1)Graph Cut的目标和背景的模型是灰度直方图,Grab Cut取代为RGB三通道的混合高斯模型GMM;
(2)Graph Cut的能量最小化(分割)是一次达到的,而Grab Cut取代为一个不断进行分割估计和模型参数学习的交互迭代过程;
(3)Graph Cut需要用户指定目标和背景的一些种子点,但是Grab Cut只需要提供背景区域的像素集就可以了。也就是说你只需要框选目标,那么在方框外的像素全部当成背景,这时候就可以对GMM进行建模和完成良好的分割了。即Grab Cut允许不完全的标注(incomplete labelling)。
1、颜色模型
我们采用RGB颜色空间,分别用一个K个高斯分量(一取般K=5)的全协方差GMM(混合高斯模型)来对目标和背景进行建模。于是就存在一个额外的向量k = {k1, . . ., kn, . . ., kN},其中kn就是第n个像素对应于哪个高斯分量,kn∈ {1, . . . K}。对于每个像素,要不来自于目标GMM的某个高斯分量,要不就来自于背景GMM的某个高斯分量。
所以用于整个图像的Gibbs能量为(式7):
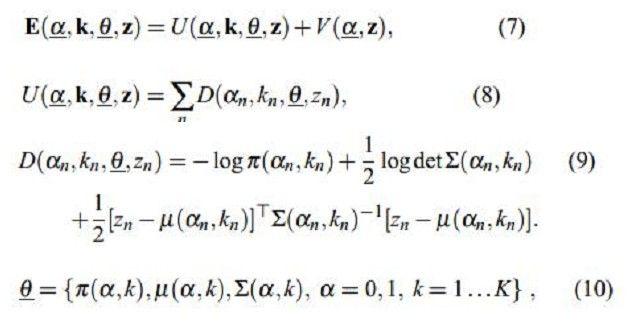
其中,U就是区域项,和上一文说的一样,你表示一个像素被归类为目标或者背景的惩罚,也就是某个像素属于目标或者背景的概率的负对数。我们知道混合高斯密度模型是如下形式:
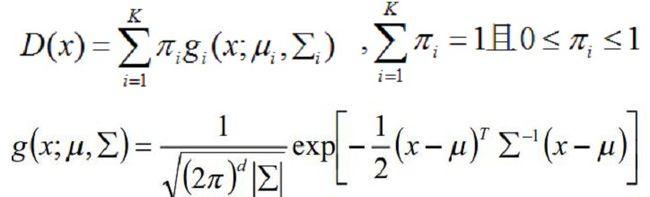
所以取负对数之后就变成式(9)那样的形式了,其中GMM的参数θ就有三个:每一个高斯分量的权重π、每个高斯分量的均值向量u(因为有RGB三个通道,故为三个元素向量)和协方差矩阵∑(因为有RGB三个通道,故为3x3矩阵)。如式(10)。也就是说描述目标的GMM和描述背景的GMM的这三个参数都需要学习确定。一旦确定了这三个参数,那么我们知道一个像素的RGB颜色值之后,就可以代入目标的GMM和背景的GMM,就可以得到该像素分别属于目标和背景的概率了,也就是Gibbs能量的区域能量项就可以确定了,即图的t-link的权值我们就可以求出。那么n-link的权值怎么求呢?也就是边界能量项V怎么求?
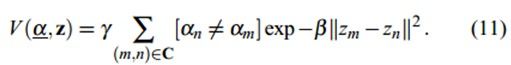
边界项和之前说的Graph Cut的差不多,体现邻域像素m和n之间不连续的惩罚,如果两邻域像素差别很小,那么它属于同一个目标或者同一背景的可能性就很大,如果他们的差别很大,那说明这两个像素很有可能处于目标和背景的边缘部分,则被分割开的可能性比较大,所以当两邻域像素差别越大,能量越小。而在RGB空间中,衡量两像素的相似性,我们采用欧式距离(二范数)。这里面的参数β由图像的对比度决定,可以想象,如果图像的对比度较低,也就是说本身有差别的像素m和n,它们的差||zm-zn||还是比较低,那么我们需要乘以一个比较大的β来放大这种差别,而对于对比度高的图像,那么也许本身属于同一目标的像素m和n的差||zm-zn||还是比较高,那么我们就需要乘以一个比较小的β来缩小这种差别,使得V项能在对比度高或者低的情况下都可以正常工作。常数γ为50(经过作者用15张图像训练得到的比较好的值)。OK,那这时候,n-link的权值就可以通过式(11)来确定了,这时候我们想要的图就可以得到了,我们就可以对其进行分割了。
2、迭代能量最小化分割算法
Graph Cut的算法是一次性最小化的,而Grab Cut是迭代最小的,每次迭代过程都使得对目标和背景建模的GMM的参数更优,使得图像分割更优。我们直接通过算法来说明:
2.1、初始化
(1)用户通过直接框选目标来得到一个初始的trimap T,即方框外的像素全部作为背景像素TB,而方框内TU的像素全部作为“可能是目标”的像素。
(2)对TB内的每一像素n,初始化像素n的标签αn=0,即为背景像素;而对TU内的每个像素n,初始化像素n的标签αn=1,即作为“可能是目标”的像素。
(3)经过上面两个步骤,我们就可以分别得到属于目标(αn=1)的一些像素,剩下的为属于背景(αn=0)的像素,这时候,我们就可以通过这个像素来估计目标和背景的GMM了。我们可以通过k-mean算法分别把属于目标和背景的像素聚类为K类,即GMM中的K个高斯模型,这时候GMM中每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过他们的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。
2.2、迭代最小化
(1)对每个像素分配GMM中的高斯分量(例如像素n是目标像素,那么把像素n的RGB值代入目标GMM中的每一个高斯分量中,概率最大的那个就是最有可能生成n的,也即像素n的第kn个高斯分量):
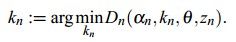
(2)对于给定的图像数据Z,学习优化GMM的参数(因为在步骤(1)中我们已经为每个像素归为哪个高斯分量做了归类,那么每个高斯模型就具有了一些像素样本集,这时候它的参数均值和协方差就可以通过这些像素样本的RGB值估计得到,而该高斯分量的权值可以通过属于该高斯分量的像素个数与总的像素个数的比值来确定。):

(3)分割估计(通过1中分析的Gibbs能量项,建立一个图,并求出权值t-link和n-link,然后通过max flow/min cut算法来进行分割):

(4)重复步骤(1)到(3),直到收敛。经过(3)的分割后,每个像素属于目标GMM还是背景GMM就变了,所以每个像素的kn就变了,故GMM也变了,所以每次的迭代会交互地优化GMM模型和分割结果。另外,因为步骤(1)到(3)的过程都是能量递减的过程,所以可以保证迭代过程会收敛。
(5)采用border matting对分割的边界进行平滑等等后期处理。
2.3、用户编辑(交互)
(1)编辑:人为地固定一些像素是目标或者背景像素,然后再执行一次2.2中步骤(3);
(2)重操作:重复整个迭代算法。(可选,实际上这里是程序或者软件抠图的撤销作用)
总的来说,其中关键在于目标和背景的概率密度函数模型和图像分割可以交替迭代优化的过程。更多的细节请参考原文。
《“GrabCut” — Interactive Foreground Extraction using Iterated Graph Cuts》
http://research.microsoft.com/en-us/um/people/ablake/papers/ablake/siggraph04.pdf
OpenCV实现了这个算法(没有后面的border matting过程),下一文我们再解读下它的源代码。