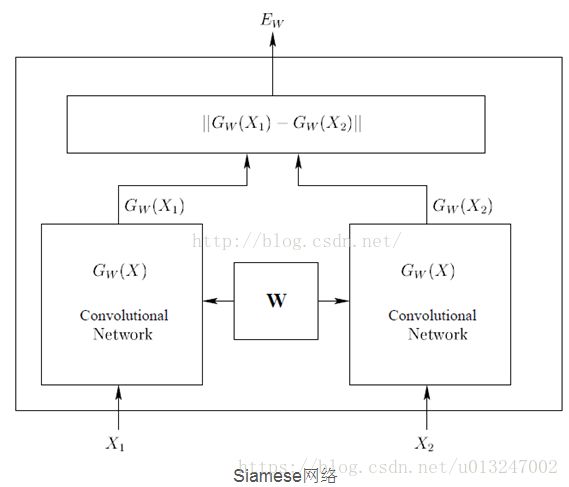
图像相似度
近来(2015-2017年),利用深度学习计算图像相似度(也可理解为图像匹配)的思想非常相似,皆源于Siamese Networks(经典老文献《Signature Verification Using a Siamese Time Delay Neural Network》)。目的就是比较两幅图片是否相似,或者说相似度是多少,因此构建的卷积神经网络模型的输入就是:两幅图片,然后网络的输出是一个相似度数值(0-1范围内)。
以下三篇论文是近一周读的,且均跑了源码,特此记录下:
注意:以下三篇论文均用到liberty、yosemite 和notredame数据集,下载网址http://matthewalunbrown.com/patchdata/patchdata.html
关于数据集的描述可参考另一篇笔记(Liberty_NotreDame_Yosemite数据集)。
一、《Learning to Compare Image Patches via Convolutional Neural Networks》 cvpr2015
源码在:https://github.com/szagoruyko/cvpr15deepcompare,需要依赖torch
实验记录:作者说提供了训练好的网络资源,且提供了Torch, MATLAB and with OpenCV的demo。
目前仅在Linux下跑了opencv的demo,但根据查看opencv的demo源码(opencv/example.cpp),貌似仅仅利用opencv计算了特征点和欧氏距离进行匹配,源码主要依赖extractPatches和extractDescriptors这两个函数。
遗留问题:c++ api和MATLAB的demo具体如何,以及opencv的demo源码未理解和解读。
paper主要创新点:
(1)把patch1、patch2合在一起,把这两张图片,看成是一张双通道的图像。也就是把两个(1,64,64)单通道的数据,放在一起,成为了(2,64,64)的双通道矩阵,然后把这个矩阵数据作为网络的输入;
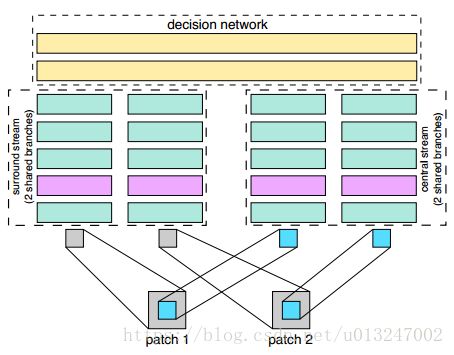
(2)结合Central-surround two-stream network,将一张图片处理成两张图片,详细操作可查看原文或者http://blog.csdn.net/hjimce/article/details/50098483;如下图所示
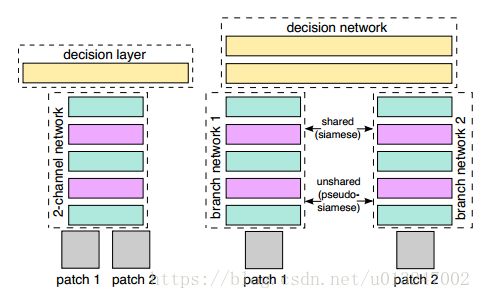
(3)paper采用了如下损失函数进行训练:
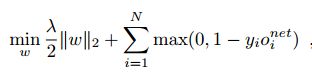
公式第一部分就是正则项,采用L2正则项。第二部分误差损失部分
![]()
是网络第i对训练图片的输出神经元,yi的取值是-1或1,当输入图片是matching的时候,为1,当non-matching的时候是-1。参数训练更新方法采用ASGD,其学习率恒为1.0,动量参数选择0.9,训练的min-batch大小选择128。权重采用随机初始化方法。然后权重衰减大小选择:
![]()
二、《MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching》 CVPR2015
源码在:https://github.com/hanxf/matchnet 需要依赖caffe
实验记录:首先该源码基于caffe和pycaffe已经完全配置好,需要注意的一点是最好在caffe-master的文件下clone该源码且运行,否则会报错(该错误是网上一位小伙伴的记录,具体是否真实不详,但是按照这样做的确没有问题)。源码分为两大块:run_gen_data.sh 和 run_eval.sh,run_gen_data.sh是调用generate_patch_db.py来生成patch的db文件(该文件时caffe特定的图像文件格式);run_eval.sh是调用evaluate_matchnet.py计算结果的。eval_metrics.py 用来计算两个patch的相似度值(输出0-1范围内值)。
遗留问题:如何将自己的图片转为db文件,并计算相似度值。
/*修改于2018.01.18
针对遗留问题,做出回答:
1)利用caffe的数据datanum来存储图像数据,将图像转为db文件,generate_patch_db.py源码中图像为1024*1024的bmp灰度图像,由16*16个patch(64*64)组成,数据以patch为单位顺序存储,因此若想自己输入一对图想计算相似度,可以自己制作info.txt等输入进行计算,需要注意的依照源码制作m50_n1_n2_0.txt。
*/
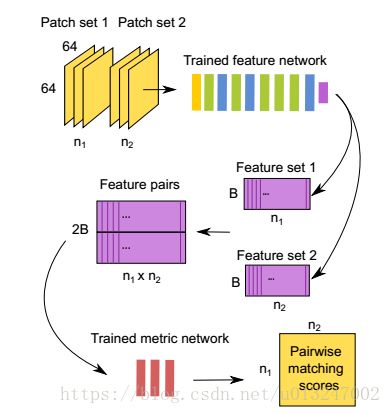
paper知识点:A. Feature Network:主要用于提取输入patch的特征,主要根据AlexNet改变而来,有些许变化。主要的卷积和pool层的两段分别有 preprocess layer 和 bottlebeck layer,各自起到归一化数据和降维,防止过拟合的作用;
B: Metric Network:主要用于feature Comparison,3层fc 加上 softmax;
C: 在训练阶段,特征网络用作“双塔”,共享参数。双塔的输出串联在一起作为度量网络的输入。Feature 和 metric networks两个网络一起训练,其cross-entropy error为
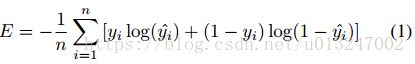
其中n为patch pairs的数量。
yi为输入pairs xi的标签(0/1),1代表匹配。
v0(xi)和v1(xi)是FC3输出的两个值。
yi^和1−yi^是FC3输出的两个值经过Softmax计算后的结果,公式如下:
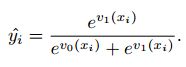
目的是minimize上式,训练方法是batch size为32的SGD。 在预测的时候,这两个子网络A 和 B 方便的用在 two-stage pipeline. 如下图所示:
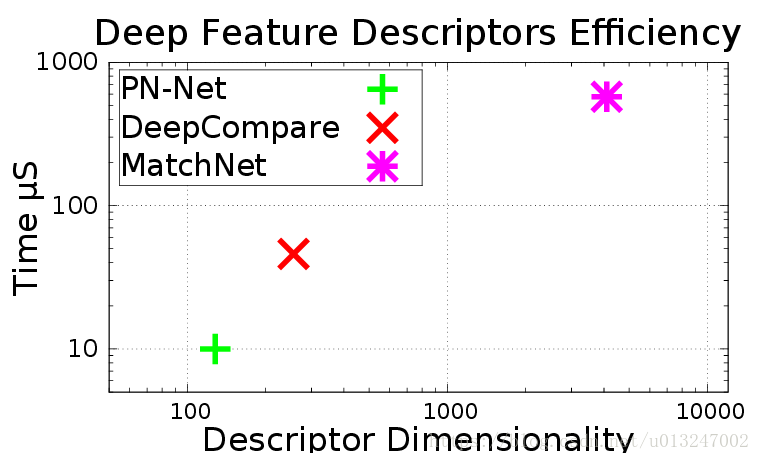
三、《PN-Net: Conjoined Triple Deep Network for Learning Local Image Descriptors》 CVPR2016 与前两篇论文进行了对比
源码在https://github.com/vbalnt/pnnet
目前还未实验