有时候转过头看回一些基础知识,才发现原来当时候自己觉得很难的东西都是从基础知识衍生而来的,突然会有点豁然开朗的感觉。譬如说我们今天要讲的知识点———注解。
初识,无处不在的注解
从Java1.5就开始引入,在注解中,我们很容易就看到了Java的理念,"Write Once,Run Anywhere"。平时开发的时候我们看到最多的注解莫过于是Java三种内建注解之一的@Override。
@Override——当我们想要复写父类中的方法时,我们需要使用该注解去告知编译器我们想要复写这个方法。这样一来当父类中的方法移除或者发生更改时编译器将提示错误信息。
其实在Android开发中,我们在很多第三方库中会经常看到注解,下面我就列举介绍一下在《Android高级进阶》中看到的一些关于运用到注解的例子:
1.标准注解:
Java API中默认定义的注解我们称之为标准注解,他们定义在java.lang,java.lang.annotation和javax.annotation包中,按照不同场景分为三类:
- 编译时相关注解:编译相关的注解是给编译器使用,如
@Override、@Deprecated、SuppressWarnings、@SafeVarags、@Generated、@FunctionalInterface... - 资源相关注解:一般用在JavaEE领域,Android开发中应该不会使用到,如@PostConstruct、@PreDestroy、@Resource、@Resources...
- 元注解:用来定义和实现注解的注解,如@Target、@Retention、@Documented、@Inherited、@Repeatable
2.Support Annotation Library:
Support Annotation Library是从Android Support Library19.1开始引入的一个全新的函数包,它包含了一系列有用的元注解,用来帮助开发者在编译期间发现可能存在的Bug。
- Nullness注解:如@Nullable、@NonNull
- 资源类型注解:如@AnimatorRes、@AttrRes、@LayoutRes...
- 类型定义注解:如@IntDef...
- 线程注解:如@UiThread、@MainThread、@WorkerThread、@BinderThread...
- RGB颜色值注解:如@ColorRes
- 值范围注解:如@Size、@IntRange、@FloatRange...
- 权限注解:如@RequirdsPermission
- 重写函数注解:如@CallSuper
- 返回值注解:如@CheckResult
- @VisibleForTesting
- @Keep
3.一些著名的第三方库:
如Butterknife、Dagger2、DBFlow、Retrofit、JUnit
以上都是总结了大部分在《Android高级进阶》中出现的注解的地方,很多注解没一个个解释,有兴趣的同学可以自己去搜索一下自己想知道的注解的具体用途。我们可以看到注解无论在java和Android中都是使用很广泛的,而且慢慢变得必不可少。下面我们就进入我们的主题,分别用两种方式去自定义注解。
那么我们先列出一个简单的题目,然后用两种不同的方式去实现:
题目:用注解实现两数相加的运算
一、运行时自定义注解:
运行时注解一般和反射机制配合使用,相比编译时注解性能比较低,但灵活性好,实现起来比较简单,所以我们先来用这个去实现。
1. 我们先去创建文件和写一个注解
/* 用来指明注解的访问范围
* 1.源码级注解SOURCE,该类型的注解信息会留在.java源码中,
* 源码编译后,注解信息会被丢弃,不会保留在编译好的.class文件中;
* 2.编译时注解CLASS,注解信息会保留在.java源码里和.class文件中,
* 在执行的时候,会被Java虚拟机丢弃不回家再到虚拟机中;
* 3.运行时注解RUNTIME,java源码里,.class文件中和Java虚拟机在运行期也保留注解信息,
* 可通过反射读取
*/
@Retention(RUNTIME)
//是一个ElementType类型的数组,用来指定注解所使用的对象范围
@Target(value = FIELD)
public @interface Add {
float ele1() default 0f;
float ele2() default 0f;
}
可以看到,因为是运行时注解,所以我们定义了@Retention是Runtime,定义了ele1,ele2两个看上去像函数的变量(在注解里这样写算是变量而不是方法或函数)
2. 下面我们使用反射去告诉这个注解你应该做什么
public class InjectorProcessor {
public void process(final Object object) {
Class class1 = object.getClass();
//找到类里所有变量Field
Field[] fields = class1.getDeclaredFields();
//遍历Field数组
for(Field field:fields){
//找到相应的拥有Add注解的Field
Add addMethod = field.getAnnotation(Add.class);
if (addMethod != null){
if(object instanceof Activity){
//获取注解中ele1和ele2两个数字,然后把他们相加
double d = addMethod.ele1() + addMethod.ele2();
try {
//把相加结果的值赋给该Field
field.setDouble(object,d);
}catch (Exception e){
}
}
}
}
}
}
就这样,我们利用了反射,告诉了Add这个注解,在代码里找到你的时候,你该做什么,把工作做好,你就有饭吃。
3.使用
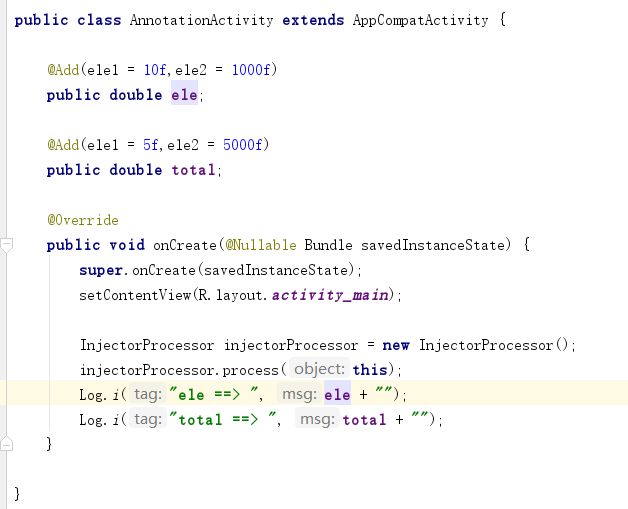

很快,我们就用第一种方式实现了给出的题目;确实,在代码量上这种方式比较简单粗暴,但是这种方式并不常用。
一、编译时自定义注解:
有不常用的方式,肯定就有常用的方式,下面我们就来介绍这个常用的方式——注解处理器
著名的第三方框架ButterKnife也就是用这种方式去实现注解绑定控件的功能的。
注解处理器是(Annotation Processor)是javac的一个工具,用来在编译时扫描和编译和处理注解(Annotation)。你可以自己定义注解和注解处理器去搞一些事情。一个注解处理器它以Java代码或者(编译过的字节码)作为输入,生成文件(通常是java文件)。这些生成的java文件不能修改,并且会同其手动编写的java代码一样会被javac编译。看到这里加上之前理解,应该明白大概的过程了,就是把标记了注解的类,变量等作为输入内容,经过注解处理器处理,生成想要生成的java代码。
我们可以看到所有注解都会在编译的时候就把代码生成,而且高效、避免在运行期大量使用反射,不会对性能造成损耗。
下面我们就看看怎么去实现一个注解处理器:
1. 建立工程:
- 首先创建一个project;
- 创建lib_annotations,
这是一个纯java的module,不包含任何android代码,只用于存放注解。 - 创建lib_compiler,
这同样是一个纯java的module。该module依赖于步骤2创建的module_annotation,处理注解的代码都在这里,该moduule最终不会被打包进apk,所以你可以在这里导入任何你想要的任意大小依赖库。 - 创建lib_api,
对该module不做要求,可以是android library或者java library或者其他的。该module用于调用步骤3生成的辅助类方法。
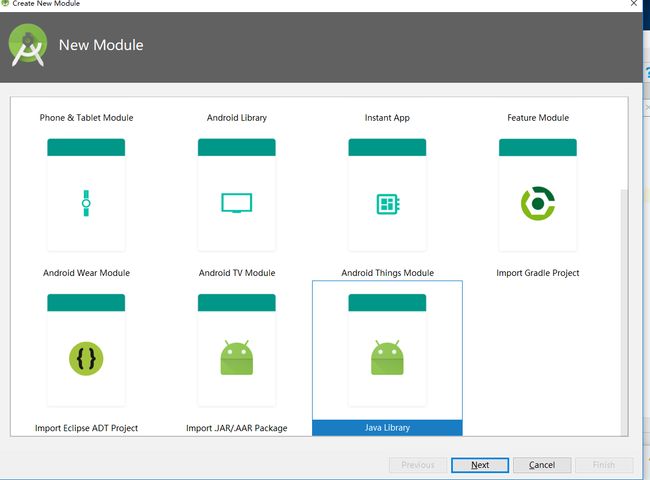
为什么我们要新建这么多module呢,原因很简单,因为有些库在编译时起作用,有些在运行时起作用,把他们放在同一个module下会报错,所以我们秉着各司其职的理念把他们都分开了。
2.在module的lib_annotations创建Add注解

跟第一种方法不同,我们在@Retention选择的是CLASS,虽然选择RUNTIME也是可以的,但是为了显示区别,我们还是作了修改。
3.写注解处理器
在写注解处理器之前我们必须在lib_compiler中引入两个库辅助我们成就大业:

- auto-service:
AutoService会自动在META-INF文件夹下生成Processor配置信息文件,该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,
就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。
基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定,方便快捷。 - javapoet:JavaPoet是square推出的开源java代码生成框架,提供Java Api生成.java源文件。这个框架功能非常有用,我们可以很方便的使用它根据注解、数据库模式、协议格式等来对应生成代码。通过这种自动化生成代码的方式,可以让我们用更加简洁优雅的方式要替代繁琐冗杂的重复工作。
我们先在lib_compiler中创建一个基类
public class AnnotatedClass {
public Element mClassElement;
/**
* 元素相关的辅助类
*/
public Elements mElementUtils;
public TypeMirror elementType;
public Name elementName;
//加法的两个值
private float value1;
private float value2;
public AnnotatedClass(Element classElement) {
this.mClassElement = classElement;
this.elementType = classElement.asType();
this.elementName = classElement.getSimpleName();
value1 = mClassElement.getAnnotation(Add.class).ele1();
value2 = mClassElement.getAnnotation(Add.class).ele2();
}
Name getElementName() {
return elementName;
}
TypeMirror getElementType(){
return elementType;
}
Float getTotal(){
return (value1 + value2);
}
/**
* 包名
*/
public String getPackageName(TypeElement type) {
return mElementUtils.getPackageOf(type).getQualifiedName().toString();
}
/**
* 类名
*/
private static String getClassName(TypeElement type, String packageName) {
int packageLen = packageName.length() + 1;
return type.getQualifiedName().toString().substring(packageLen).replace('.', '$');
}
}
然后我们的主角就要出场了——注解处理器
我们创建一个文件,然后继承AbstractProcessor
@AutoService(Processor.class)
public class AddProcessor extends AbstractProcessor{
private static final String ADD_SUFFIX = "_Add";
private static final String TARGET_STATEMENT_FORMAT = "target.%1$s = %2$s";
private static final String CONST_PARAM_TARGET_NAME = "target";
private static final char CHAR_DOT = '.';
private Messager messager;
private Types typesUtil;
private Elements elementsUtil;
private Filer filer;
/**
* 解析的目标注解集合,一个类里可以包含多个注解,所以是Map>
*/
Map> annotatedElementMap = new LinkedHashMap<>();
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
messager = processingEnv.getMessager();
typesUtil = processingEnv.getTypeUtils();
elementsUtil = processingEnv.getElementUtils();
filer = processingEnv.getFiler();
}
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
@Override
public Set getSupportedAnnotationTypes() {
Set annotataions = new LinkedHashSet();
annotataions.add(Add.class.getCanonicalName());
return annotataions;
}
@Override
public boolean process(Set annotations, RoundEnvironment roundEnv) {
因为该方法可能会执行多次,所以每次进来必须clear
annotatedElementMap.clear();
//1.遍历每个有Add注解的Element,
//2.然后把它加入Map里面,一个类里可以包含多个注解,所以是Map>,
//3.赋予它工作任务,告诉他你该做什么,
//4.然后生成Java文件
for (Element element : roundEnv.getElementsAnnotatedWith(Add.class)) {
//判断被注解的类型是否符合要求
if (element.getKind() != ElementKind.FIELD) {
messager.printMessage(Diagnostic.Kind.ERROR, "Only FIELD can be annotated with @%s");
}
TypeElement encloseElement = (TypeElement) element.getEnclosingElement();
String fullClassName = encloseElement.getQualifiedName().toString();
AnnotatedClass annotatedClass = new AnnotatedClass(element);
//把类名和该类里面的所有关于Add注解的注解放到Map里面
if(annotatedElementMap.get(fullClassName) == null){
annotatedElementMap.put(fullClassName, new ArrayList());
}
annotatedElementMap.get(fullClassName).add(annotatedClass);
}
//因为该方法会执行多次,所以size=0时返回true结束
if (annotatedElementMap.size() == 0) {
return true;
}
//用javapoet生成类文件
try {
for (Map.Entry> entry : annotatedElementMap.entrySet()) {
MethodSpec constructor = createConstructor(entry.getValue());
TypeSpec binder = createClass(getClassName(entry.getKey()), constructor);
JavaFile javaFile = JavaFile.builder(getPackage(entry.getKey()), binder).build();
javaFile.writeTo(filer);
}
} catch (IOException e) {
messager.printMessage(Diagnostic.Kind.ERROR, "Error on creating java file");
}
return true;
}
//以下是javapoet创建各种方法的实现方式
private MethodSpec createConstructor(List randomElements) {
AnnotatedClass firstElement = randomElements.get(0);
MethodSpec.Builder builder = MethodSpec.constructorBuilder()
.addModifiers(Modifier.PUBLIC)
.addParameter(TypeName.get(firstElement.mClassElement.getEnclosingElement().asType()), CONST_PARAM_TARGET_NAME);
for (int i = 0; i < randomElements.size(); i++) {
addStatement(builder, randomElements.get(i));
}
return builder.build();
}
private void addStatement(MethodSpec.Builder builder, AnnotatedClass randomElement) {
builder.addStatement(String.format(
TARGET_STATEMENT_FORMAT,
randomElement.getElementName().toString(),
randomElement.getTotal())
);
}
private TypeSpec createClass(String className, MethodSpec constructor) {
return TypeSpec.classBuilder(className + ADD_SUFFIX)
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(constructor)
.build();
}
private String getPackage(String qualifier) {
return qualifier.substring(0, qualifier.lastIndexOf(CHAR_DOT));
}
private String getClassName(String qualifier) {
return qualifier.substring(qualifier.lastIndexOf(CHAR_DOT) + 1);
}
}
我们可以看到注解处理器总共有四个方法,他们分别的作用是:
- init() 可选
在该方法中可以获取到processingEnvironment对象,借由该对象可以获取到生成代码的文件对象, debug输出对象,以及一些相关工具类
- getSupportedSourceVersion()
返回所支持的java版本,一般返回当前所支持的最新java版本即可
- getSupportedAnnotationTypes()
你所需要处理的所有注解,该方法的返回值会被process()方法所接收
- process() 必须实现
扫描所有被注解的元素,并作处理,最后生成文件。该方法的返回值为boolean类型,若返回true,则代表本次处理的注解已经都被处理,不希望下一个注解处理器继续处理,否则下一个注解处理器会继续处理。
4.使用
好了,打了这么多代码,我们先看下编译时生成的代码和文件是怎么样的,就会使用了:
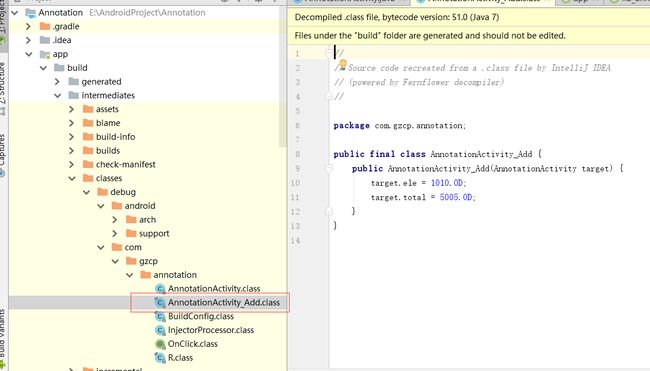
我们可以看到,我们在注解处理器里面写了那么多代码,就是为了生成Build目录下的.class文件,是自动生成的。
看到了生成的AnnotationActivity_Add的文件,我们下面就去写一个注入方法,把我们想要结果拿出来展示:
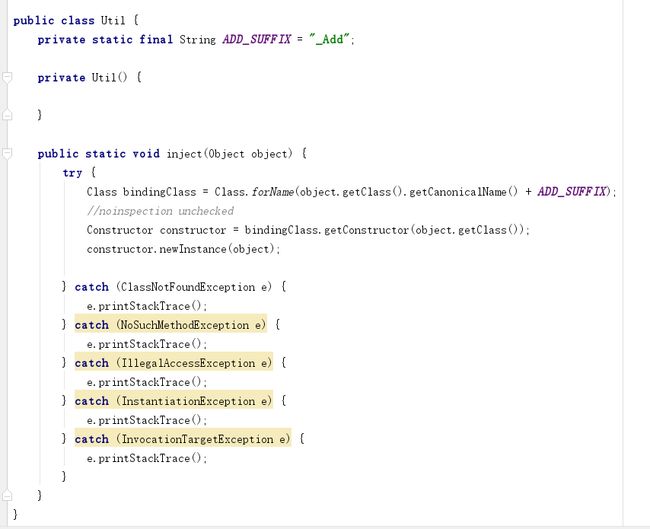
我们看到Util里面我们实现了想要的东西,把AnnotationActivity_Add的结果找出来再赋值给相应的变量。


总结
我们成功的用两种不同的注解方式实现了两数相加的运算,1.运用的是反射,2.运用的是注解处理器。虽然看上去注解处理器的方式比较繁琐,但是使用比较普遍,而且有很多好处,这里就不一一述说。如果有兴趣学习的同学可以下载源码去学习一下,互相交流,共同学习。Demo源码下载链接
参考文章:
使用Android注解处理器,解放劳动生产力
JavaPoet - 优雅地生成代码
我的掘金