基于python的狗屁不通观后感生成器 2.0
基于上次狗屁不通观后感修改器的优化
好像输入影名或书名就可以运行了?
本次优化主要有:
1.加入了selenium的web自动化技术,并且实现了浏览器的无痕浏览(类似于隐藏浏览器技术)
2.运用了tkinter界面库设计了GUI图形交互界面(显得更高端,但是我的设计很丑,不要在意,能点就行,所以没用pyqt,采用了tkinter)
3.具有比较明显的错别字程序会帮你回正,也就是说你把《霸王别姬》记成了《霸王别鸡》,也是可以搜的出来了,好像也不会打错。。。
总的来说:可以只用输书名,或者影名就可以自动生成观后感,并且具有界面框,dangdangdang
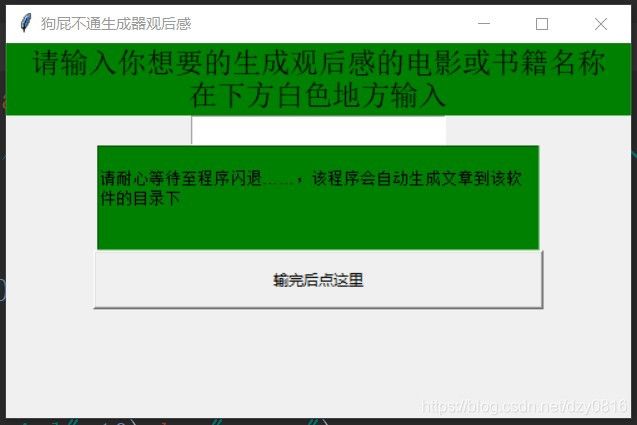 就长这个丑样(因为懒,所以懒得设计了,能用就行。。。)
就长这个丑样(因为懒,所以懒得设计了,能用就行。。。)
因为好像代码交互时好像出了点什么出了问题,所以。。。接下来直接单独附上tkinter的代码嘛
import tkinter as tk
window = tk.Tk()
window.title("狗屁不通生成器观后感")
window.geometry("500x300")
label = tk.Label(window,width=50,height=2,background ="green",
text="请输入你想要的生成观后感的电影或书籍名称\n在下方白色地方输入",
font = ("Arial",17),anchor = "n")
label.pack()
inputframe = tk.Entry(show = None,font = 10)
inputframe.pack()
result = tk.Text(height=5,width=50,font=("Arial",10),bg="green")
result.pack()
text="请耐心等待至程序闪退……,该程序会自动生成文章到该软件的目录下"
var = inputframe.get()
def get_name():
var = inputframe.get()
result.insert("insert",var)
result.insert("insert","\n")
result.insert("insert",text)
print(var)
button_one = tk.Button(height=2,width=50,text="输完后点这里",command=get_name)
button_one.pack()
x=get_name()
window.mainloop()
因为很简单,所以短。。。
接下来步入正题!!!,更新后的爬取代码,加了点selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import re
import requests
import bs4
from bs4 import BeautifulSoup
import time
import random
import os
def translation(name):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(options=chrome_options)
#selenium实现自动化浏览,这里用无痕模式
browser.get("https://www.douban.com/")
browser.find_element_by_name("q").send_keys(name)
browser.find_element_by_xpath("//input[@type='submit']").click()
browser.find_elements_by_xpath("//h3/a")[0].click()
handle = browser.window_handles
browser.switch_to.window(handle[1])#窗口句柄的切换
url = browser.current_url
return url
def gettext(url):
try:
kv={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
r=requests.get(url,timeout=20,headers=kv)
r.raise_for_status()
r.encoding=r.apparent_encoding
r.encoding = "utf-8"
return r.text
except:
return ""
#短评链接;
def getcri(text):
pat="https://movie.douban.com/review\/[0-9]*?\/\""
result=re.compile(pat).findall(text)
return result
#作品简介
def getbf(text):
pat="\导演.*?分"
result=re.compile(pat).findall(text)
return result
def main():
print("本作品作者董正宇QAQ")
print("请输入你想要获取的观后感,输入格式:电影(或书)的名称")
bookname = input()
url=translation(bookname)
key={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
txt=gettext(url)
listf=getcri(txt)#各链接
s=getbf(txt)#简介
soup=BeautifulSoup(txt,"html.parser")
title=soup.title.text.replace("\n","")
title=title.replace(" ","")
title=re.sub("\(.*?\)","",title)
print("搜索结果:"+title)
if not os.path.exists(title):
os.mkdir(title)
for i in listf:
after=i[:-2]
duanpin=gettext(after)
pat="data-original=\"[\d]\"\>(.*?)\<\/div\>"
result=re.findall(pat,duanpin,re.S)
name="狗屁不通文章"
content=re.sub("(\)+" ,"\n",result[0])
content_two=re.sub("()|(<\/p>)|( )+|-+"
,"",content)
each_par=content_two.split("\n")
pargraph=random.sample(range(0,len(each_par)),len(each_par)-3)
for i in pargraph:
random_par=random.randint(0,5)
with open(title+"/"+name+".txt","a",encoding="utf-8") as f:
f.write(each_par[i])
if random_par == 1:
f.write("\n")
main()
同样,自动生成的文章会保存在该exe的目录下,点开就可以用了
这回你直接可以输 (某书某影视)名字就可以用了
重点:后面这个代码也可以运行,只是不好看(而已。。)
下面附上结果图:

