有限边界的MDP
在前面两章关于强化学习的介绍中,我们定义了马尔可夫决策过程(MDP)以及价值迭代/策略迭代这两种用于求解MDP的算法。特别地,我们介绍了最优贝尔曼方程(optimal Bellman equation),它定义了在最佳策略π*下的最佳价值函数Vπ*:

在计算出最佳价值函数后,我们可以用下式求出最佳策略π*:

在这一章中,我们会将此扩展到一个更通用的情况下:
(1). 我们需要将等式改写成同时满足离散和连续两种情况,因此我们将原来式子中求和的部分改写为:
这代表着我们取的是价值函数在下一个状态下的期望值。在离散的情况下,期望值可以改写成状态的求和;在连续的情况下,期望值可以改写成状态的积分。符号s′ ~ Psa表示下一个状态s′ 以Psa的概率取样得到。
(2). 我们假设奖励函数同时取决于状态和行动,简而言之就是,R: S × A → R。因此原来式子需要改写为:
(3). 原来的MDP是没有时间边界(time horizon)的,现在我们假设有时间边界T,并定义有限边界的MDP(finite horizon MDP)由如下五元组构成:
在这种设定下,整个过程的奖励定义为:
这个式子替代了之前的定义:

在有限边界的MDP中,折扣因子γ不再出现。回顾下在无限边界的情况下,引入γ是为了让在无限状态的奖励函数是有界的,即:
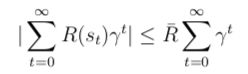
而在有限边界的情况下,整个奖励函数是有限个奖励函数之和,因此γ没有存在的必要了。
在有限边界的设定下,MDP的有些行为会有不一样的变化。最重要的变化是,最佳策略π*是非稳定的(non-stationary),也就是说它是随着时间变化的,用数学的表达就是:
这里的上标t表明当前策略在t时刻。具体来说就是,首先我们处于初始状态s0,然后根据时刻0的策略采取行动a0 := π(0)s0,随后状态按照Ps0a0的概率转移到下一个状态s1,然后根据时刻1的策略采取行动a1 := π(1)s1,以此类推。
为什么说最佳策略π*是非稳定的呢?直觉上来说,我们只能采取有限的行动,我们使用的策略取决于当前的环境以及我们还剩下多少时间。我们可以考虑如下的场景:在地图中分别有两个奖励+1和+10。起初我们的策略是选择接近+10的奖励,但是随着时间的推移,由于我们没有足够的步数到达+10,这时就迫使我们采取到达离我们更近的+1奖励。
(4). 状态转换概率也随着时间而变化,即在时刻t下的状态转换概率为P(t)stat。同样,奖励函数R(t)也随着时间而变化。
将上述几点统一起来,有限边界的MDP由如下五元组构成:
策略π在时刻t的价值函数定义和之前一样,即:
那么现在的问题是,在有限边界的设定下,我们如何求得最优价值函数呢?
在标准的价值迭代算法中,我们在每次迭代中使用了贝尔曼方程(题外话:贝尔曼是动态规划的创始人,贝尔曼方程在动态规划领域密切相关)。而在有限边界的MDP问题中,我们也采取基于迭代的算法,为了更好的进行说明,我们先看如下两个观察:
(1). 在最后时刻T,最优价值函数显然为:

(2). 在其他时刻 0 ≤ t < T,如果我们知道下一时刻的最优价值函数V*t+1,那么我们有:

有了上面两个观察,我们可以得到求解有限边界MDP的最优价值函数的算法:
(1). 根据等式(1)求得V*T
(2). 对每一个t = T - 1, ..., 1, 0:
根据等式(2)和V*t + 1计算出V*t
线性二次型调节控制
这一节我们介绍一个特殊的有限边界MDP的模型,它被称为线性二次型调节控制(Linear Quadratic Regulation (LQR)),这个模型广泛应用于机器人学(robotics)中。
首先我们明确下这个模型做了哪些假设。这个模型的状态和行动是连续的,并且:
状态转换函数是线性的,且有噪音,表示如下:
其中At ∈ Rn×n,Bt ∈ Rn×d是两个矩阵,wt ~ N(0, Σt)是高斯分布的噪音。在后面的段落中我们会看到只要噪音的高斯分布的均值为0,噪音不会影响到最优价值的计算。
我们继续假设奖励函数是二次函数,表示为:
其中Ut ∈ Rn×n,Wt ∈ Rd×d是两个半正定矩阵,也就是说奖励函数的值永远是负数。
现在我们已经完整定义了LQR模型的所有假设了,下面是求解LQR算法的两个步骤:
第一步:假设我们不知道A, B, Σ这三个矩阵。为了预估这三个参数,我们可以参考在价值迭代那节中用模型学习的方法。首先我们执行任意策略,并收集数据。然后用线性回归的方法求得A和B,即:
最后用高斯判别分析(GDA)模型中提到的方法求出Σ。
第二步:假设A, B, Σ三个参数已知,我们可以通过动态规划求出最优价值函数。换句话说就是,给定:

的情况下,我们想要计算V*t,我们用上一小节介绍的动态规划算法求解,具体来说就是:
(1). 初始化
对于最后时刻T,我们有:

(2). 不断循环
令 t < T且假设我们已知V*t + 1。
事实1:可以证明如果V*t + 1是关于st的二次函数,那么V*t + 1也是一个二次函数。或者可以表述为存在某个矩阵Φ和某个标量Ψ使得:

当t = T时,我们有Φt = -UT,Ψt = 0。
事实2:可以证明最优价值函数是关于状态的线性函数。
如果我们知道了V*t + 1,就等价于知道了Φt + 1和Ψt + 1,所以我们只需要解释如何根据Φt + 1和Ψt + 1以及其他参数求出Φt和Ψt就行了。

上式中第二行用到了最优价值函数的定义,第三行是将假设中的定义进行了代入。注意表达式最后是关于at的二次参数,因此可以求出最优行动a*t为:

其中:
由此可见,最优策略是与st线性相关的。基于a*t我们可以求出Φt和Ψt的值,它们之间的关系也被称为离散Ricatti方程(Discrete Ricatti equations)。
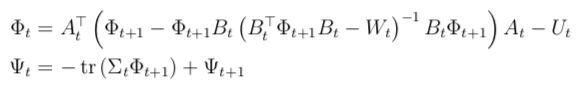
事实3:我们注意到Φt的值与Ψt和Σt都无关。由于Lt是关于At,Bt和Φt + 1的函数,这表明最优策略也与噪音无关。
最后总结一下,LQR问题求解的算法步骤如下:
- 如果需要的话,先估计参数At, Bt, Σt
- 初始化参数ΦT := -UT,ΨT := 0
- 对每一个t = T - 1, ..., 1, 0,利用Φt + 1,Ψt + 1和离散Ricatti方程求出Φt,Ψt。如果存在某个策略使得状态趋于0,那么迭代一定是收敛的。
利用事实3,我们可以使这个算法运行地更快一些。由于最优策略不依赖于Ψt,并且Φt的更新只依赖于Φt,因此迭代时只更新Φt就足够了。
总结
- 在原有MDP的基础上引入了时间边界的概念,这类问题被称为有限边界的MDP,在这种设定下策略和价值函数都是不稳定的,也就是说它们是随着时间变化的
- 线性二次型调节控制(LQR)是一个特殊的有限边界MDP模型,该模型广泛应用于机器人学中
参考资料
- 斯坦福大学机器学习课CS229讲义 LQR, DDP and LQG
- 网易公开课:机器学习课程 双语字幕视频