maskrcnn_benchmark理解记录——关于batch norm、relu、dropout 的相对顺序以及dropout可不可用
ps:
1.如何在卷积神经网络中实现全局平均池化。在此之前,建议阅读 ResNet这篇论文 ,以了解全局平均池化操作的好处。代替全连接层。
2.dropout只可能在box分支的两个全连接层那里,这个可以后期finetuning下。全连接网络可以使feature map的维度减少,进而输入到softmax,但是又会造成过拟合,可以用pooling来代替全连接。那就解决了之前的问题:要不要在fc层使用dropout。使用AVP就不要了。
目录
一、batch norm、relu、dropout 等的相对顺序
conv2d + init.weight→bn→relu
conv2d + init.weight and bias→ relu
conv→relu→..........→conv→relu
补充:pytorch的torch.nn.init 对参数和偏置初始化方式
二、Dropout 层(2012年)与BN层 Dropout 层是否有效
一、batch norm、relu、dropout 等的相对顺序
在 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift 一文中,作者指出,“we would like to ensure that for any parameter values, the network always produces activations with the desired distribution”(produces activations with the desired distribution,为激活层提供期望的分布)。
因此 Batch Normalization 层恰恰插入在 Conv 层或全连接层之后,而在 ReLU等激活层之前。而对于 dropout 则应当置于 activation layer 之后。
-> CONV/FC -> BatchNorm -> ReLu(or other activation) -> Dropout -> CONV/FC ->;
那么看到我的有几种方式,全部未用dropout:
-
conv2d + init.weight→bn→relu
-
conv2d + init.weight and bias→ relu
-
conv→relu→..........→conv→relu
- 第一种在ResNet.py
- 先在结构层定义了 conv2d、bn和并对conv2d进行nn.init.kaiming_uniform_(l.weight, a=1)处理。
- 然后结合在forword中看到结构是:conv2d + init.weight→bn→relu
self.conv1 = Conv2d(
in_channels,
bottleneck_channels,
kernel_size=1,
stride=stride_1x1,
bias=False,
)
self.bn1 = norm_func(bottleneck_channels)
self.conv2 = Conv2d(
bottleneck_channels,
bottleneck_channels,
kernel_size=3,
stride=stride_3x3,
padding=dilation,
bias=False,
groups=num_groups,
dilation=dilation
)
self.bn2 = norm_func(bottleneck_channels)
self.conv3 = Conv2d(
bottleneck_channels, out_channels, kernel_size=1, bias=False
)
self.bn3 = norm_func(out_channels)
for l in [self.conv1, self.conv2, self.conv3,]:
nn.init.kaiming_uniform_(l.weight, a=1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = F.relu_(out)
out = self.conv2(out)
out = self.bn2(out)
out = F.relu_(out)
out0 = self.conv3(out)
out = self.bn3(out0)
- 第二种是在:roi_keypoint_feature_extractors.py
- 先在结构层对 conv2d进行nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")和 nn.init.constant_(module.bias, 0)的处理,权重和偏置的初始化
- 然后在forward中进行了relu,结合得到结构是:conv2d + init.weight and bias→ relu
for layer_idx, layer_features in enumerate(layers, 1):
''' 1 512 ... → ... 8 512'''
layer_name = "conv_fcn{}".format(layer_idx)
module = Conv2d(next_feature, layer_features, 3, stride=1, padding=1) #256 → 512
nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")
nn.init.constant_(module.bias, 0)
self.add_module(layer_name, module)
next_feature = layer_features
self.blocks.append(layer_name)
self.out_channels = layer_features
def forward(self, x, proposals):
x = self.pooler(x, proposals)
for layer_name in self.blocks: #TODO 这里应该是对五个特征图的list,逐步进行*8的卷积+relu
x = F.relu(getattr(self, layer_name)(x))
return x
- 第三种是在roi_box_feature_extractors.py
- 先在结构层定义了 fc6 和 fc7
- 然后在forward中进行了relu,结合得到结构是:FC→relu→FC→relu
self.pooler = pooler
self.fc6 = make_fc(input_size, representation_size, use_gn)
self.fc7 = make_fc(representation_size, representation_size, use_gn)
self.out_channels = representation_size #1024
def forward(self, x, proposals):
x = self.pooler(x, proposals)
x = x.view(x.size(0), -1)
x = F.relu(self.fc6(x))
x = F.relu(self.fc7(x))
return x
- 再来看看 roi_mask_feature_extractors.py
- 先在结构层定义了 fcn的每一层→blocks
- 然后在forward中进行了relu,结合得到结构是:conv→relu→..........→conv→relu
self.blocks = []
for layer_idx, layer_features in enumerate(layers, 1):
layer_name = "mask_fcn{}".format(layer_idx)
module = make_conv3x3(
next_feature, layer_features,
dilation=dilation, stride=1, use_gn=use_gn
)
self.add_module(layer_name, module)
next_feature = layer_features
self.blocks.append(layer_name)
self.out_channels = layer_features
def forward(self, x, proposals):
x = self.pooler(x, proposals)
for layer_name in self.blocks:
x = F.relu(getattr(self, layer_name)(x))
return x
补充:pytorch的torch.nn.init 对参数和偏置初始化方式

二、Dropout 层(2012年)与BN层 Dropout 层是否有效
- Batch Normalization(BN)即批规范化,是正则化的一个重要手段。在正则化效果的基础上,批处理规范化还可以减少卷积网络在训练过程中的梯度弥散。这样可以减少训练时间,提升结果。
由此产生的网络可以通过饱和非线性进行训练,更能容忍增加的训练速率,并且通常不需要Dropout进行正则化。 BN模型的高性能表明在卷积之间使用BN是有效的。此外,Dropout不应该放在卷积之间,因为Dropout模型的性能往往比Control模型差。

在CNN使用BN时需要:
-
在卷积层和激活层之间插入BN层。
-
调节BN的超参数。
一个BN层的例子:也就是conv2d →BN→relu
model.add(Conv2d(60,3, padding = 'same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
- Dropout是神经网络中防止模型过拟合的重要正则化方式,而近来的网络结构中却少有见到Dropout的身影。一般情况下,只需要在网络存在过拟合风险时才需要实现正则化。如果网络太大、训练时间太长、或者没有足够的数据,就会发生这种情况。
注意,这只适用于CNN的全连接层。对于所有其他层,不应该使用Dropout。相反,应该在卷积之间插入批处理标准化。这将使模型规范化,并使模型在训练期间更加稳定。
首先,Dropout对卷积层的正则化效果一般较差。
因为卷积层的参数很少,所以一开始就不需要太多的正则化。此外,由于特征映射中编码的空间关系,激活变得高度相关,这使得Dropout无效。
其次,Dropout规范化的研究已经过时了。
在卷积神经网络的初期,卷积层通过池化层(一般是 最大池化)后总是要一个或n个全连接层,最后在softmax分类。其特征就是全连接层的参数超多,使模型本身变得非常臃肿。最近的网络架构设计逐渐抛弃了如VGG16这样在网络末端包含全连接层的大型网络模型,对于这样的模型,过拟合,以前通常是通过在全连接层之间添加Dropout操作来解决。但现在通过全局平均池化(global average pooling)(GAP)替换全连接层,在提高性能的同时减小了模型大小,并减小过拟合。
如何在卷积神经网络中实现全局平均池化。在此之前,建议阅读 ResNet这篇论文 ,以了解全局平均池化操作的好处。
一个丢弃率为0.5的Dropout层
model=keras.models.Sequential()model.add(keras.layers.Dense(150, activation='relu'))model.add(keras.layers.Dropout(0.5))
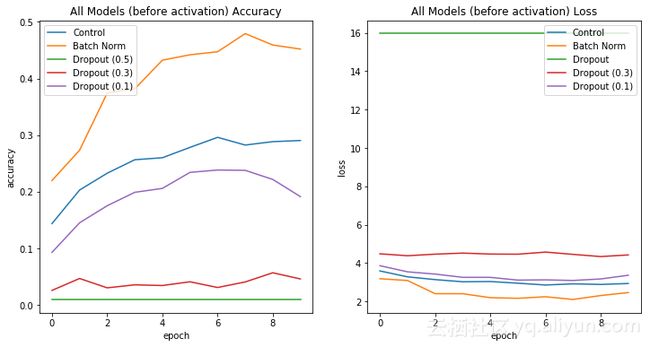
1.19年3月18.Dropout VS BN: 别在你的网络中使用Dropout中提出
https://blog.csdn.net/qq_27292549/article/details/81092653 这是18年4月的文章
做分类的时候,Dropout 层一般加在全连接层,防止过拟合,提升模型泛化能力。而很少见到卷积层后接Drop out (原因主要是 卷积参数少,不易过拟合),今天找了些博客,特此记录。
You can imagine that if neurons are randomly dropped out of the network during training, that other neurons will have to step in and handle the representation required to make predictions for the missing neurons. This is believed to result in multiple independent internal representations being learned by the network.
The effect is that the network becomes less sensitive to the specific weights of neurons. This in turn results in a network that is capable of better generalization and is less likely to overfit the training data.
你可以想象,如果神经元在训练过程中随机被网络丢弃(死掉、不激活),那么其他神经元将不得不介入并处理对缺失神经元进行预测所需的表示。这将导致网络学习多个独立的内部表示。其结果是网络对神经元的特定权重变得不那么敏感。 这反过来导致网络能够更好地概括并且不太可能过拟合训练数据。
在附上提出Dropout的论文中的观点:
from the Srivastava/Hinton dropout paper:
“The additional gain in performance obtained by adding dropout in the convolutional layers (3.02% to 2.55%) is worth noting. One may have presumed that since the convolutional layers don’t have a lot of parameters, overfitting is not a problem and therefore dropout would not have much effect. However, dropout in the lower layers still helps because it provides noisy inputs for the higher fully connected layers which prevents them from overfitting.”
They use 0.7 prob for conv drop out and 0.5 for fully connected.“通过在卷积层中添加dropout(3.02%至2.55%)获得的额外性能增益值得注意。 人们可能已经假定由于卷积层没有很多参数,因此过度拟合不是问题,因此丢失不会产生太大影响。 然而,较低层中的丢失仍然有帮助,因为它为较高的完全连接层提供噪声输入,从而防止它们过度拟合。
他们conv 使用0.7 prob,fc使用0.5