Python之NumPy使用
欢迎关注
微信公众号:想进化的猿
头条号:python进阶者
一、NumPy基本概念
NumPy是Python的一种开源数值计算扩展,是一种用Python实现的科学计算工具包,可用来存储和处理大型矩阵。Numpy提供的内容包括以下几部分:
1、一个强大的N维数组对象Array,也就是ndarray;
2、较为成熟的函数库;
3、用于整合C/C++和Fortran代码的工具包;
4、实用的线性代数、傅里叶变换和随机数生成函数。
NumPy是一个运行速度非常快的数学库,它的主要功能就是数组计算。NumPy配合SciPy(高级科学计算库)、Matplotlib(绘图工具库)一起使用可组成强大的科学计算环境,可用于代替MatLab的功能,并且有助于我们通过Python学习数据科学和机器学习。
关于NumPy的安装和系统学习可参考NumPy中文文档:https://www.numpy.org.cn。
二、NumPy基础数据结构
NumPy数组(即ndarray,以下统一用ndarray表示)是一个多维数组对象,它由两部分组成,包括:1、实际的数据。2、描述数据的元数据。
NumPy数组的创建
NumPy创建数组最基本的方法是将序列传递给NumPy的array()函数,参数可以是列表、元组等,基本用法如下:
import numpy as np
arr1 = np.array([0, 1, 2, 3, 4])
arr2 = np.array((0, 1, 2, 3, 4))
print([0, 1, 2, 3, 4])
print((0, 1, 2, 3, 4))
print(arr1)
print(arr2)以上代码分别给array()函数传入一个列表和元组,生成的ndarray是一样的。作为对比,我们把源列表和元组也打印出来,运行结果如下图所示。从打印结果可以看出,Python的列表和元组数据间用逗号隔开,而ndarray的数据之间用空格隔开。

ndarray还可以通过NumPy的arange()函数创建。arange()函数创建的是一个等差数组,它非常类似Python自身的range()函数,两者的区别仅仅在于返回值,arange()函数返回的是一个ndarray,而range()函数返回的是list。下面我们看一下arange()函数创建ndarray的基本用法。
import numpy as np
arr1 = np.arange(5)
arr2 = np.arange(1, 5)
arr3 = np.arange(1, 10, 2)
print(arr1)
print(arr2)
print(arr3)我们通过给arange()函数传入不同个数的参数分别创建了三个ndarray。arr1传入一个参数5,表示创建0~4共5个数的ndarray;arr2传入两个参数1,5,表示创建1~4的ndarray,arange与range一样,是不包括大数的,所以不能取到5;arr3传入3个参数,前两个参数表示数据范围1~9的整数,第三参数2表示以2为一个跨度,即取1,3,5,7,9这5个数为ndarray数据。运行结果如下所示。

熟悉Matlab的朋友都知道linspace是一个均分计算指令,NumPy中也有linspace()函数,作用与Matlab中的linspace一致,它也可以用来创建ndarray。
import numpy as np
arr1 = np.linspace(1, 10, 4)
arr2 = np.linspace(1, 10, 4, endpoint=False)
arr3 = np.linspace(1, 10, 4, retstep=True)
print(arr1)
print(arr2)
print(arr3)运行结果如下,1~10区间4等分后的数据组成ndarray,且数据为浮点型。linspace中的endpoint参数表示是否包含最后一个值,这里是10,默认为True包含,设为False就不包含了;retstep参数表示是否返回步长,默认为False不包含,设为Ture返回一个元组,包括一个ndarray和一个步长值。

以上我们创建的都是一维的ndarray,接下来我们创建几个多维的ndarray,基本创建方法如下。
import numpy as np
arr1 = np.array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
arr2 = np.arange(1, 5).reshape(2, 2)
arr3 = np.arange(1, 12, 2).reshape(2, 3)
print(arr1)
print(arr2)
print(arr3)reshape()函数可以重新调整矩阵的行数、列数、维数,利用reshape()可以将一维ndarray调整为多维的ndarray。运行结果如下。

通过array()函数想利用多维数组为参数来创建ndarray时,如果传入的多维数组个数不一样,NumPy不会报错,但不会如愿生成多维ndarray,而是会生成一维ndarray。当传入的多维数组中其中有字符串时,生成的多维ndarray就会自动转化成字符串类型,我们看一下效果。
import numpy as np
arr1 = np.array([[0, 1, 2, 3, 4], [5, 6, 7, 8]])
arr2 = np.array([[0, 1, 2, 3, 4], ['a', 'b', 'c', 'd', 'e']])
print(arr1)
print(arr2)arr1传入两个个数不同的数list,生成的是一个包含两个list类型的一维ndarray;arr2传入一个整型list和一个字符型list,生成的是一个字符型的二维ndarray。

NumPy中还有一些常见的ndarray创建方式,包括zeros()、zeros_like()、ones()、ones_like()、eye()等函数。zeros()函数初始化一个数据全为0的ndarray;zeros_like()函数传入一个ndarray,生成一个形状一模一样、数据全为0的ndarray;ones()函数和ones_like()函数的功能与zeros()函数、zeros_like()函数类似,只是ones()函数和ones_like()函数生成的ndarray数据全为1。eye()函数创建一个行列数相同的单位矩阵ndarray,即对角线值全为1,其余值全为0的ndarray。这些函数的基本用法如下。
import numpy as np
arr1 = np.zeros(5)
arr = [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
arr2 = np.zeros_like(arr)
arr3 = np.ones(5)
arr4 = np.ones_like(arr)
arr5 = np.eye(5)
print(arr1)
print(arr2)
print(arr3)
print(arr4)
print(arr5)运行结果如下所示。

NumPy数组的基本属性
首先,我们需要明确几个概念。数组的维数称为秩,一维数组的秩为1,二维数组的秩为2,依次类推。在NumPy中,每个线性的数组称为一个轴,秩描述的其实就是轴的数量。
NumPy数组的常见属性有以下几个:
ndim:ndarray的秩数(轴数),也就是数组的维度个数。
shape:ndarray的形状,例如n行m列的ndarray,shape就是(n,m)。
size:ndarray中所有元素的个数,例如n行m列的ndarray,size就是n*m。
dtype:ndarray的元素类型。
itemsize:ndarray中元素的字节大小,例如int32的字节大小为4,float64的字节大小为8。
我们创建一个4行5列的整型数组,即n=4,m=5,分别看一下这几个属性。
import numpy as np
arr = np.arange(20).reshape(4, 5)
print(arr)
print('ndim: ' + str(arr.ndim))
print('shape: ' + str(arr.shape))
print('size: ' + str(arr.size))
print('dtype: ' + str(arr.dtype))
print('itemsize: ' + str(arr.itemsize))运行结果如下所示。对于4行5列的ndarray,轴数为2,形状为(4,5),共有4*5=20个数据,元素类型为int64,字节大小就是int64的字节大小,为8。

三、NumPy常用函数
改变数组形状的reshape()、resize()、T()
reshape()函数的作用是重新调整ndarray的行数、列数、维数,根据传入的参数个数不同,可以重置成不同维数的数组,但是新的形状必须与原来的形状兼容,即相乘后必须等于原数组中元素的总数量,否则会报错。基本用法如下。
import numpy as np
arr1 = np.arange(12)
print(arr1)
print("---------------")
arr2 = arr1.reshape(3, 2, 2)
print(arr2)
print("---------------")
arr3 = arr2.reshape(3, 4)
print(arr3)以上代码首先创建了一个一维ndarray,共12个数,然后使用reshape()函数将一维ndarray调整成3*2*2的三维ndarray,再对新的三维ndarray调整成3*4的二维ndarray,可以看到,不管做怎样的调整,相乘后的结果都是源数组的元素总个数12。运行结果如下所示。

resize()函数与reshape()函数的作用一样,也可以重新调整ndarray的行数、列数、维数,不同的是reshape()函数需要兼容原来的形状,少于或超出原数组个数会报错,而resize()函数不会报错,当少于时,resize()函数会自动截断,当超出时,resize()函数会循环copy原数组中的值进行填充,直至将新ndarray填充满。我们创建一个10个数的一维ndarray,将形状调整成3*4共12个数,代码如下。
import numpy as np
arr = np.arange(10)
print(arr)
print("---------------")
np.resize(arr, (3, 4)) # 数量不够时会循环使用直至充满形状
print(np.resize(arr, (2, 6)))
print("---------------")
print(arr.resize(2, 6))
print(arr)运行结果如下所示,新数组共3*4=12个数,大于原数组的10个数,多出的两个数就会从原数组中取出前两个数进行填充。另外,调用ndarray本身的resize()方法不会生成新ndarray,但会改变ndarray形状,调用后再次打印arr,会发现它的形状已经被改变了,并且多余的位置以0填充。

ndarray复制
ndarray的复制使用NumPy的copy()函数,当我们把一个ndarray复制给新的ndarray时,两者是紧密关联的,当原ndarray改变时,新ndarray也会随之改变,但一般我们使用复制并不想要他们有关联性,这个时候使用copy()函数就可以解决这个问题,其实这就是NumPy中的浅copy和深copy。下面我们看一下两者的区别。
import numpy as np
arr1 = np.arange(10)
arr2 = arr1 # 指向同一个数组
print(arr1 == arr2)
arr1[2] = 100
print(arr1)
print(arr2)
print("---------------")
arr3 = arr1.copy()
print(arr1 == arr3)
arr1[3] = 1000
print(arr1)
print(arr3)运行结果如下图所示。首先不管是赋值还是使用copy()函数生成新ndarray,两者的值都是相等的。区别就是改变原数组时,一个会随之改变,一个不会。

ndarray数据类型转换
NumPy中支持的数据类型比Python内置的类型要更多,下表列举了常用的NumPy基本数据类型。
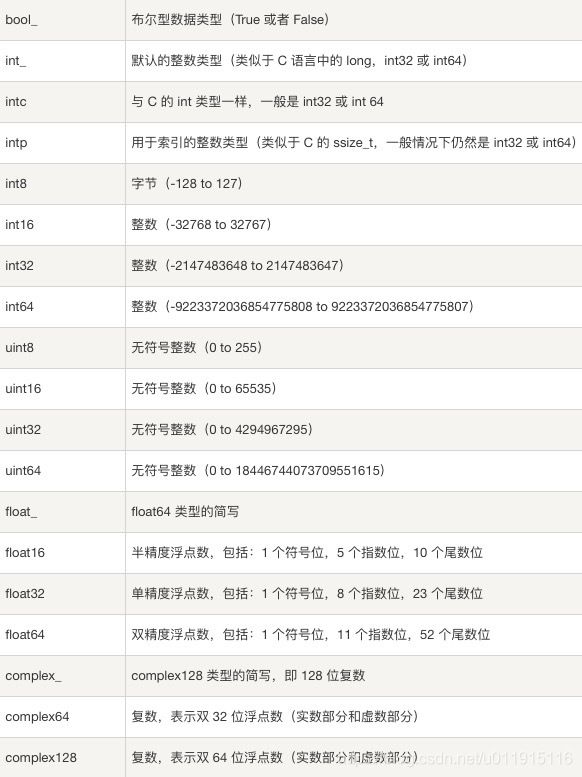
NumPy中设置ndarray数据类型使用astype()函数,基本用法如下。
import numpy as np
arr1 = np.arange(10, dtype=float)
print(arr1, arr1.dtype)
arr2 = arr1.astype(np.int64)
print(arr2, arr2.dtype)
arr3 = arr2.astype(np.string_)
print(arr3, arr3.dtype)运行结果如下所示。

ndarray合并
ndarray的合并使用NumPy的stack()函数,传入要合并的ndarray,axis参数表示按行合并或按列合并,默认axis=0按行合并,axis=1时按列合并。按行合并或按列合并还可以使用hstack()函数或vstack()函数。基本用法如下。
import numpy as np
a = np.arange(5)
b = np.arange(5, 9)
print(a)
print(b)
print("---------------")
print(np.hstack((a, b, a))) # 横向连接
print("---------------")
c = np.array([[1], [2], [3]])
d = np.array([['a'], ['b'], ['c']])
print(c)
print(d)
print("---------------")
print(np.vstack((c, d))) # 纵向连接
print("---------------")
# 默认纵向
# print(np.stack((a, b), axis=1)) # 列数不一致,会报错
b = np.arange(5, 10)
print(np.stack((a, b, a), axis=1))运行结果如下。需要注意的是,在合并时,必须保证要合并的几个ndarray在合并方向上的数量是一致的,否则会报错。

ndarray拆分
NumPy中使用split()函数对ndarray进行拆分,与合并的stack()函数类似,axis表示拆分方向,同时,也有hsplit()函数和vsplit()函数分别按行或按列拆分。split()相关函数的基本用法如下。
import numpy as np
arr = np.arange(16).reshape(4, 4)
print(arr)
print("---------------")
print(np.hsplit(arr, 2))
print(np.split(arr, 2, axis=1))
print("---------------")
print(np.vsplit(arr, 2))
print(np.split(arr, 2))运行结果如下。拆分时必须保证拆分的数量能等分,否则会报错。

四、NumPy的索引和切片
基本索引和切片
NumPy中ndarray的基本索引和切片与Python中的数组类似,我们分别以一维、二维、三维ndarray作为代表看一下NumPy中ndarray的基本索引和切片。
1、一维ndarray的基本索引和切片
import numpy as np
arr = np.arange(10)
print(arr)
print("---------------")
# 直接索引,打印arr索引为2的值
print(arr[2])
print("---------------")
# 切片,打印arr中从索引5开始到最后一个数的值(包括5)
print(arr[5:])
print("---------------")
print("---------------")
# 切片,打印arr中从开始到索引5的值(不包括5)
print(arr[:5])
print("---------------")
# 切片,打印arr中从第一个数开始以2位步长到最后一个数的值
print(arr[::2])运行结果如下。

2、二维ndarray的基本索引和切片
import numpy as np
arr = np.arange(15).reshape(3, 5)
print(arr)
print("---------------")
# 索引,打印行索引为1的那一行的值
print(arr[1])
print("---------------")
# 索引,打印行索引为1,列索引为1的值
print(arr[1][1])
print(arr[1, 1])
print("---------------")
# 切片,打印行索引从开始到行索引为2(不包括2)的几行值
print(arr[:2])
print("---------------")
# 切片,打印行索引从第一行到行索引为2(不包括2),列索引从2开始(包括2)到最后一列的值
print(arr[:2, 2:])运行结果如下。

3、三维ndarray的基本索引和切片
import numpy as np
arr = np.arange(16).reshape(4, 2, 2)
print(arr)
print("---------------")
# 索引
print(arr[1][1][1])
print("---------------")
# 切片
print(arr[1:])运行结果如下。

四维以上的ndarray使用索引和切片的方法以此类推即可。
布尔型索引和切片
NumPy中还有一种布尔型的索引和切片,布尔型有True和False两个值,对ndarray使用布尔型索引和切片会取出布尔值为True的值,需要注意的是用于索引和切片的布尔型数组的长度和待操作的ndarray的操作轴的大小必须一致。另外,布尔型数组也可与切片,整数(整数序列)一起使用。基本用法如下。
import numpy as np
arr = np.arange(12).reshape(3, 4)
print(arr)
print("---------------")
x = np.array([True, False, True])
y = np.array([True, True, False, False])
print(x)
print(y)
print("---------------")
# 对第一维(这里是行)操作
print(arr[x])
print("---------------")
# 对第二维(这里是列)操作
print(arr[:, y])
print("---------------")
print(arr>6)
print("---------------")
print(arr[arr>6])对第一维操作时,可省略后面的维度,但对非第一维操作时,其他维度上的值不能忽略,可用“:”表示其他维度上的所有值。除了显示的设置布尔型数组进行索引和切片,还可以使用条件表达式,上述代码中我们打印了arr>6的值,可以看到,返回的是一个与arr形状一致的布尔型ndarray,再使用新生成的布尔型ndarray对arr进行索引,得到的将会是一个满足条件的一维ndarray。运行结果如下所示。

五、ndarray数据运算
基本标量数据运算
基本标量数据运算指的是在ndarray上以其中的元素方式进行计算,既可以用“+(加)、-(减)、*(乘)、/(除)、**(幂)”等数学运算符重载,也可以使用NumPy模块中的函数(add、subtract、multiply、divide等)。下面我们来看一下ndarray的一些基本标量数据运算。
import numpy as np
arr = np.arange(12).reshape(3, 4)
print(arr)
print("---------------")
# 加
print(arr + 5)
print(np.add(arr, 5))
print("---------------")
# 减
print(arr - 5)
print(np.subtract(arr, 5))
print("---------------")
# 乘
print(arr * 5)
print(np.multiply(arr, 5))
print("---------------")
# 除
print(arr / 5)
print(np.divide(arr, 5))
print("---------------")
# 幂
print(arr ** 2)
print("---------------")
# 平方根
print(np.sqrt(x))我们创建一个3*4的ndarray,然后分别对它进行加、减、乘、除、幂、平方根的运算,可以看到,当ndarray与单个数进行标量数据运算时,ndarray中的每个元素分别与此数进行运算得到结果。同时,用数学符号和使用NumPy模块中的运算函数计算的结果是一致的。运行结果如下所示。

ndarray除了可以与单个数进行基本标量数据运算外,两个ndarray之间也可以进行基本标量数据运算,运算规则为ndarray中对应位置上的元素分别进行对应的运算。我们创建两个ndarray进行基本标量数据运算。
import numpy as np
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# 加法
print(x + y)
print(np.add(x, y))
print("---------------")
# 减法
print(x - y)
print(np.subtract(x, y))
print("---------------")
# 乘法
print(x * y)
print(np.multiply(x, y))
print("---------------")
# 除法
print(x / y)
print(np.divide(x, y))
print("---------------")
# 幂
print(x ** y)
print("---------------")两个ndarray中对应位置上的元素分别做对应运算,运行结果如下所示。
矩阵运算
我们之前有提到,ndarray的元素之间是用空格隔开的,从结构上看,一个一维ndarray相当于一个向量,一个多维ndarray就相当于一个矩阵。事实上,在很多应用场景下,我们也经常把ndarray当做向量或矩阵来使用。学过向量与矩阵的朋友都知道,数学上的向量乘法、矩阵乘法是不同于标量乘法的,不是简单的对应位置上的元素做乘法。(关于向量与矩阵的概念以及向量乘法、矩阵乘法这里不做详细介绍,但这是比较重要的知识点,不了解或者已经遗忘的朋友请务必去学习回顾一下。)
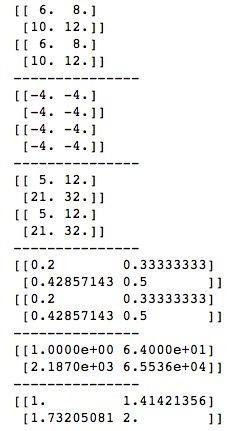
不同于MATLAB,NumPy中“*”符号只是是标量乘法,而不是向量乘法、矩阵乘法,NumPy中的向量乘法、矩阵乘法使用dot()函数来计算,运算结果也成为向量或矩阵的内积。dot()函数也有两种使用方法,既可以作为ndarray对象的实例方法,也可以直接以NumPy模块中的函数作为运算。我们创建两个矩阵和两个向量,分别进行向量与向量的内积计算,向量与矩阵的内积计算,矩阵与矩阵的内积计算。
import numpy as np
# 创建两个矩阵
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
# 创建两个向量
v = np.array([9,10])
w = np.array([11, 12])
# 向量与向量的内积为标量
print(v.dot(w.T))
print(np.dot(v, w))
print("---------------")
# 矩阵与向量的内积为向量
print(x.dot(v))
print(np.dot(x, v))
print("---------------")
# 矩阵与矩阵的内积为矩阵
print(x.dot(y))
print(np.dot(x, y))运算结果如下所示。向量与向量的内积结果为一个标量,向量与矩阵的内积结果为一个向量,矩阵与矩阵的内积结果为一个矩阵。

数据处理运算
NumPy中对于ndarray的数据处理运算提供了许多有用的函数,包括计算平均值的mean()函数、计算最大、最小值的max()、min()函数,计算标准差的std()函数、计算方差的var()函数、求总和的sum()函数、排序函数sort()等。这些运算函数的基本用法如下。
import numpy as np
arr = np.arange(12).reshape(3, 4)
# 平均值
print(arr.mean())
print(np.mean(arr, axis=0))
print("---------------")
# 最大、最小值
print(arr.max())
print(np.max(arr, axis=1))
print("---------------")
print(arr.min())
print("---------------")
# 标准差
print(arr.std())
print("---------------")
# 方差
print(arr.var())
print("---------------")
# 求和
print(arr.sum())
print("---------------")
# 排序
print(np.sort(arr))
print(-np.sort(-arr))我们创建一个3*4的ndarray来进行数据处理运算。这些数据处理运算函数与dot()函数一样,也有两种使用方法,以mean()为例,我们可以使用arr.mean()或np.mean(),当不传参数时,默认操作对象为整个ndarray,设置axis=1或axis=0时可以分别指定对行或对列进行数据处理运算。运行结果如下所示。

六、NumPy中的广播
NumPy中的广播是一种非常强大的机制,它允许NumPy在执行数据运算时使用不同形状的数组。例如,当一个较小的ndarray和一个较大的ndarray要进行数据运算时,我们会希望通过多次使用较小的数组来对较大的数组执行一些操作。
在介绍基本标量数据运算时,我们用ndarray与一个标量进行运算,其实就是一个简单的广播,广播机制会把标量循环填充成与要运算的ndarray同样形状的一个ndarray,然后再运算,所以我们看到的结果就是ndarray中每个元素分别与标量进行相关运算。
如果没有广播机制,当ndarray与一个标量进行运算时,需要先对这个标量进行转化,我们可以来看一下这个过程。
import numpy as np
x = np.arange(12).reshape(3, 4)
print(x)
v = 5
# 创建与x形状一致的空ndarray
y = np.empty_like(x)
# 用标量5填充这个空ndarray
for i in range(3):
for j in range(4):
y[i, j] = 5
print("---------------")
print(y)
# 运算
print("---------------")
print(np.add(x, y))首先,创建一个与要运算的ndarray形状一致的空ndarray,然后用参与运算的标量去填充这个空ndarray,最后对这两个形状一致的ndarray进行运算。运行结果如下所示。

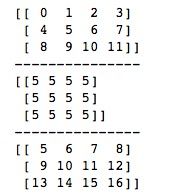
以上是一种保持ndarray形状一致的扩展方法,但是这种方法在ndarray非常大时,像这样的显式循环就会变得很慢。这时我们有另一种快速的扩展方法,使用NumPy的tile()函数进行叠加。 我们可以像如下这样实现这种方法。
import numpy as np
x = np.arange(12).reshape(3, 4)
print(x)
v = np.array([5])
# 使用tile进行ndarray叠加
vv = np.tile(v, (3, 4))
print("---------------")
print(vv)
# 运算
y = x + vv
print("---------------")
print(y)tile()函数传入要扩展的ndarray,然后将形状传入,就会开始往各个维度方向上进行扩展。运行结果如下所示,与循环方式填充实现的结果是一样的。
以上是没有广播机制的前提下对较小的ndarray进行扩展填充至与较大的ndarray形状一致的方法,有了广播机制,就不需要以上的操作了,对于3*4的ndarray与标量5的运算,我们可以直接进行。
import numpy as np
x = np.arange(12).reshape(3, 4)
print(x)
v = 5
# 直接运算
y = x + v
print("---------------")
print(y)运算结果如下所示,可以得到一样的正确结果。

当然,需要注意的是,不是所有较小的ndarray与较大的ndarray之间的运算都是可以利用广播机制的,例如,我们用形状为(4,3)的ndarray与形状为(3,4)的ndarray进行数据运算,就会报“operands could not be broadcast together with shapes (4,3) (3,4)”的错误,可以看到,形状(4,3)和(3,4)的ndarray并不能顺利进行广播来运算。
因此,我们在使用广播机制时,一定要特别注意是否遵循了以下规则:
1、如果ndarray不具有相同的rank,则将较低等级ndarray的形状添加1,直到两个形状具有相同的长度。
2、如果两个ndarray在维度上具有相同的大小,或者如果其中一个ndarray在该维度中的大小为1,则称这两个ndarray在维度上是兼容的。
3、如果ndarray在所有维度上兼容,则可以一起广播。
4、广播之后,每个阵列的行为就好像它的形状等于两个输入ndarray的形状的元素最大值。
5、在一个ndarray的大小为1且另一个ndarray的大小大于1的任何维度中,第一个ndarray的行为就像沿着该维度复制一样。
形状(4,3)和(3,4)的ndarray就是由于没有遵循规则2,所以不能顺利进行广播。在遵循广播机制规则的基础下,我们应该尽可能地使用去它,因为广播机制通常会使我们的代码更加简洁,效率也更高。
七、NumPy中的随机数
NumPy中的随机数集中在random包中,它包含了多种概率分布的随机样本,是数据计算、分析的重要辅助工具,主要包括normal(mean,stdev,size)、random(size)、rand(d0, d1, ..., dn)、randn(d0, d1, ..., dn)、randint(low[, high, size, dtype])、choice(a[, size, replace, p])。下面我们分别看一下这几种随机数的用法。
normal(mean,stdev,size)
normal(mean,stdev,size)生成一组均值为mean,标准差为stdev、大小形状为size的高斯随机数或高斯随机数ndarray。
import numpy as np
arr = np.random.normal(2, 1, size=(5, 5))
print(arr)
print("---------------")
print(arr.mean())
print("---------------")
print(arr.std())我们创建了一个均值为2,标准差为1的5*5的ndarray,然后使用mean()函数和std()函数分别计算这个ndarray的均值和标准差,虽然由于浮点数误差可能存在偏差,但结果基本上是接近mean=2、std=1的。运行结果如下所示。
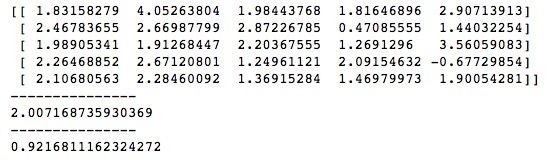
random(size)
random(size)生成一组[0,1)范围(大于等于0小于1)、大小形状为size的随机数或随机数ndarray。此外,random_sample(size)、ranf(size)、sample(size)与random(size)的用法与功能基本一样。
import numpy as np
arr1 = np.random.random(size=(5, 5))
print(arr1)
print("---------------")
arr2 = np.random.random_sample(size=(5, 5))
print(arr2)
print("---------------")
arr3 = np.random.ranf(size=(5, 5))
print(arr3)
print("---------------")
arr4 = np.random.sample(size=(5, 5))
print(arr4)我们分别用random(size)、random_sample(size)、ranf(size)、sample(size)这四个函数创建5*5的ndarray,可以看到,这四个函数创建的ndarray中的元素都是[0,1)范围内的。运行结果如下所示。

rand(d0, d1, ..., dn)
rand(d0, d1, ..., dn)生成一个[0, 1)的均匀分布的随机浮点数或N维随机浮点数ndarray,如果没有参数,则返回一个值,如果有参数,则返回d0*d1*…*dn个值。
import numpy as np
x = np.random.rand()
print(x)
print("---------------")
arr = np.random.rand(2, 2, 3)
print(arr)运行结果如下, 当给rand()函数传入参数时,d0, d1, ..., dn分别表示第1、2、...、(n-1)维上的元素个数,会生成一个d0*d1*…*dn的ndarray。
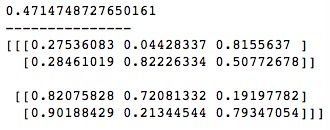
randn(d0, d1, ..., dn)
randn(d0, d1, ..., dn)生成一个期望为0、方差为1(标准正态分布)的随机浮点数或N维随机浮点数ndarray,参数d0, d1, ..., dn的含义与rand()函数中的参数是一样的。
import numpy as np
x = np.random.randn()
print(x)
print("---------------")
arr = np.random.randn(2, 4, 4)
print(arr)
print("---------------")
print("均值为: " + str(arr.mean()))
print("方差为: " + str(arr.var()))运行结果如下所示,可以看到,虽然存在误差,但是均值和方差分别是解决0和1的。
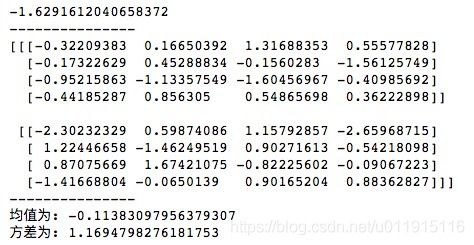
randint(low[, high, size, dtype])
randint(low[, high, size, dtype])生成一个整数或N维整数ndarray。当传入参数high时,范围为[low,high),当不传参数high时,范围就会变成为[0,low);size表示生成的ndarray维度大小;dtype为数据类型,但是只能传整型(int、int8、int32、int64等),默认的数据类型是np.int。
import numpy as np
print(np.random.randint(5))
print("---------------")
print(np.random.randint(5, 10))
print("---------------")
print(np.random.randint(5, size=10))
print("---------------")
print(np.random.randint(5, 10, size=(2, 5)))
print("---------------")
print(np.random.randint(5, dtype=np.int32))运行结果如下所示。

choice(a[, size, replace, p])
choice(a[, size, replace, p])生成一个元素值来自数组a、大小形状为size的值或ndarray。a表示输入数组,即生成结果的元素的来源数组,当输入为单个数字例如5时,为range(5);size表示输出的ndarray大小形状,默认为1;replace设置输出数字是否可重复,False代表不可重复,比如a=[1,2,3,4,5],输出的ndarray中1,2,3,4,5不能重复,所以该ndarray的维数不能超过5;p代表a中对应的单位出现的概率,为一个数组,例如[0.1,0.2,0.1,0.3,0.3],他们维数和a相同,且加起来总和必须等于1。
import numpy as np
arr_from = [2, 12, 6, 8, 9]
arr1 = np.random.choice(arr_from)
print(arr1)
print("---------------")
arr2 = np.random.choice(arr_from, size=(2, 3))
print(arr2)
print("---------------")
arr3 = np.random.choice(arr_from, size=(2, 2), replace=False)
print(arr3)
print("---------------")
arr4 = np.random.choice(arr_from, size=(2, 3), p=[0.1, 0.1, 0.1, 0.1, 0.6])
print(arr4)
print("---------------")
arr_str_from = ['xzq', 'qlh', 'xzq666', 'qlh888']
result = np.random.choice(arr_str_from)
print(result)arr1只传入来源数组a,得到的是一个来自a的值;arr2传入size,返回的结果就会变成指定大小形状的ndarray;arr3将replace参数设置成False,元素不可重复,所以size的大小必须小于源数组a;arr4设置概率p,为了观察差异,我们将最后一个元素9的概率设置成0.6,可以发现,得到的ndarray中出现9的频率会特别高。此外,当源数组a中拥有字符型数据时,整个源数组中的元素都会被转成字符型数据。运行结果如下所示。

seed(n)
我们在使用随机数时,有时候会有生成相同随机数的需求,NumPy中使用seed()函数来控制生成相同的随机数,每次运行代码时给seed()函数设置相同的标记n时,即可生成相同的随机数。
import numpy as np
# 不使用seed
a = np.random.rand(5)
print('第一次列表a:',a)
a = np.random.rand(5)
print('第二次列表a:',a)
print("---------------")
# 使用seed
np.random.seed(2)
b = rand(5)
print('第一次列表b:',b)
np.random.seed(2)
b = rand(5)
print('第二次列表b:',b)
np.random.seed(2)
b = rand(5)
print('第三次列表b:',b)
np.random.seed(0)
b = rand(5)
print('第四次列表b:',b)
np.random.seed(0)
b = rand(5)
print('第五次列表b:',b)
np.random.seed(2)
b = rand(5)
print('第六次列表b:',b)
b = rand(5)
print('第七次列表b:',b)我们通过几组随机数来看一下是否设置seed()函数对生成随机数的影响。运行结果如下所示,可以看到,当不设置seed时,生成的随机数都是随机的不相同的;而使用seed()函数时,对于设置了相同标记的seed(n)时,生成的随机数是一模一样的,如第一次、第二次、第三次、第六次都设置了seed(2),第四次、第五次都设置了seed(0),返回的就分别是一样的随机数,而第七次我们没设置任何seed(),所以又返回了不一样的随机数。
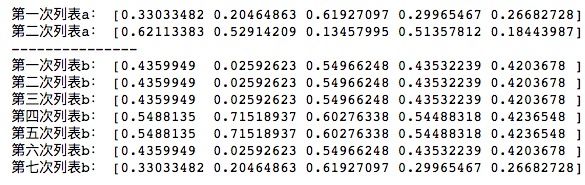
八、ndarray的保存与加载
NumPy中可以怼ndarray数据进行存储,以便下次继续使用,一般我们将ndarray数据保存成.npy文件。NumPy中使用save()函数对ndarray进行保存,基本用法如下。
import numpy as np
arr = np.random.rand(4, 4)
print(arr)
np.save('/Users/qhzc-imac-02/Desktop/result.npy', arr)
print('保存成功')运行结果如下所示。我们传入路径和要保存的ndarray,运行后就会在指定路径下生成一个.npy文件。
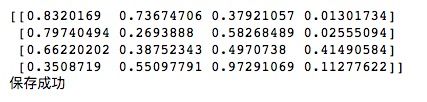
我们用sublime把这个文件打开,可以看到如下内容。

保存的.npy文件是以二进制格式存储的,所以看到的并不是我们的原始数组。但这不影响我们对保存的数据的继续使用,待下次使用时,只需要使用NumPy中的load()函数即可。
import numpy as np
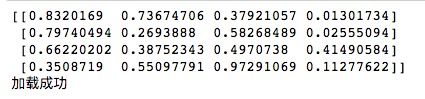
arr_load = np.load('/Users/qhzc-imac-02/Desktop/result.npy')
print(arr_load)
print('加载成功')运行结果如下所示,加载的ndarray就是我们之前保存的ndarray,内容是完全一样的。
如果我们要将多个ndarray保存到同一个文件中,这时我们可以使用NumPy的savez()函数。savez函数的第一个参数是路径,后面的参数则是需要保存的ndarray,有几个传几个,也可以使用关键字参数为ndarray起一个名字,非关键字参数传递的ndarray会自动为传入的数组命名为arr_0,arr_1,arr2等。savez函数保存的是一个.npz压缩文件,其中每个文件都是一个.npy文件,文件名对应于ndarray名。基本用法如下。
import numpy as np
arr1 = np.random.rand(2, 2)
arr2 = np.random.rand(3, 3)
arr3 = np.random.rand(4, 4)
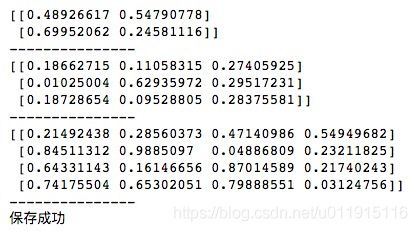
np.savez('/Users/qhzc-imac-02/Desktop/ndarrays_save.npz', arr1, no2=arr2, no3=arr3)
print(arr1)
print("---------------")
print(arr2)
print("---------------")
print(arr3)
print("---------------")
print('保存成功')运行后会在指定路径下生成一个.npz文件,它也是以二进制格式存储的。便于与加载结果的对比将运行结果记录如下。
加载.npz文件同样通过NumPy的load()函数,load()函数会自动识别.npz文件,并且返回一个类似于字典的对象,可以通过ndarray名作为关键字获取ndarray的内容。
import numpy as np
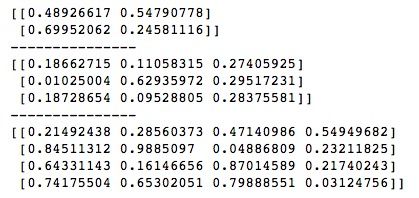
ndarray_dict = np.load('/Users/qhzc-imac-02/Desktop/ndarrays_save.npz')
print(ndarray_dict['arr_0'])
print("---------------")
print(ndarray_dict['no2'])
print("---------------")
print(ndarray_dict['no3'])运行结果如下所示。使用时注意保存时给每个ndarray的命名,可以看到,加载出来的数据与保存的是一致的。
以上对ndarray的保存都是以二进制格式保存的,如果我们想从保存的文件中查看我们保存的内容,可以将ndarray保存成.txt格式。NumPy中使用savetxt()函数来存储.txt格式,对应的使用loadtxt()函数来加载.txt文件中的ndarray。
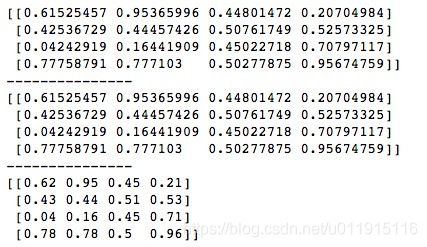
import numpy as np
arr = np.random.rand(4, 4)
print(arr)
print("---------------")
np.savetxt('/Users/qhzc-imac-02/Desktop/ndarray1.txt', arr, delimiter=',')
arr_txt_load1 = np.loadtxt('/Users/qhzc-imac-02/Desktop/ndarray1.txt', delimiter=',')
print(arr_txt_load1)
print("---------------")
np.savetxt('/Users/qhzc-imac-02/Desktop/ndarray2.txt', arr, delimiter=',', fmt='%.2f')
arr_txt_load2 = np.loadtxt('/Users/qhzc-imac-02/Desktop/ndarray2.txt', delimiter=',')
print(arr_txt_load2)我们创建一个4*4的随机ndarray,分别保存成两个.txt文件,都使用“,”作为分隔符,同时将保存至ndarray2.txt的ndarray设置成保留两位小数。运行后可以看到在指定位置生成了ndarray1.txt和ndarray2.txt两个文件,我们打开这两个文件可以看到如下内容。
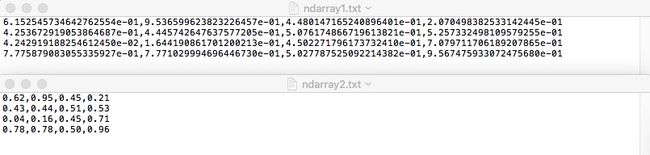
ndarray1.txt文件保存的是源数据,而ndarray2.txt文件由于设置了保存两位小数,所以是格式化后的数据。此时再调用loadtxt()函数分别加载这两个.txt文件,就会得到各自文件中的内容。从ndarray1.txt加载的内容与源ndarray一模一样,ndarray2.txt则会加载保留两位小数的ndarray。