深度学习前沿算法思想
本文转自: https://mp.weixin.qq.com/s?__biz=MzA5NDExMTAzNA==&mid=2649981646&idx=2&sn=8fe05eac5a5068efb65ca1602e5fd3a0&chksm=8854b69bbf233f8db5dbaa1ea8396d181c9a35e760ab3c1c4934b504f69fe92683972d78d327&mpshare=1&scene=2&srcid=0219lkr9kPV09dnfglsFTQvT&from=timeline&key=990de978484973e68a2840a9ecd4cefcffdfa4331c166e782b8765c318f57bfa9d30bffd71690a96ec9832acce1935c5b5fce2d2ff46ed9762080a0e15b0145e2b2891d62b46d88e13ad4e11a51584f2&ascene=2&uin=MTgwOTU2NjU0MQ%3D%3D&devicetype=android-24&version=26050434&nettype=WIFI&abtest_cookie=AQABAAgAAQBChh4AAAA%3D&pass_ticket=bMwVMQ2K1X9RvTCJaBHIfrq9%2BOLAbQeQmw8cLAK33TF40zlmdma44fhN5bVmW1Vq&wx_header=1
第一版:
深度学习前沿算法思想
深度学习实践:使用Tensorflow实现快速风格迁移
行为识别:让机器学会“察言观色”第一步
第二版:
谷歌首届 TensorFlow 开发者峰会 重磅发布 TensorFlow 1.0
微软发布AI助手Cortana 提醒用户及时查看邮件
第三版:
目前最全面的深度学习教程自学资源汇总
第四版:
三角学回顾
1.深度增强学习前沿算法思想
2016年AlphaGo计算机围棋系统战胜顶尖职业棋手李世石,引起了全世界的广泛关注,人工智能进一步被推到了风口浪尖。而其中的深度增强学习算法是AlphaGo的核心,也是通用人工智能的实现关键。本文将带领大家了解深度增强学习的前沿算法思想,领略人工智能的核心奥秘。
前言
深度增强学习(Deep Reinforcement Learning,DRL)是近两年来深度学习领域迅猛发展起来的一个分支,目的是解决计算机从感知到决策控制的问题,从而实现通用人工智能。以Google DeepMind公司为首,基于深度增强学习的算法已经在视频、游戏、围棋、机器人等领域取得了突破性进展。2016年Google DeepMind推出的AlphaGo围棋系统,使用蒙特卡洛树搜索和深度学习结合的方式使计算机的围棋水平达到甚至超过了顶尖职业棋手的水平,引起了世界性的轰动。AlphaGo的核心就在于使用了深度增强学习算法,使得计算机能够通过自对弈的方式不断提升棋力。深度增强学习算法由于能够基于深度神经网络实现从感知到决策控制的端到端自学习,具有非常广阔的应用前景,它的发展也将进一步推动人工智能的革命。
深度增强学习与通用人工智能
当前深度学习已经在计算机视觉、语音识别、自然语言理解等领域取得了突破,相关技术也已经逐渐成熟并落地进入到我们的生活当中。然而,这些领域研究的问题都只是为了让计算机能够感知和理解这个世界。以此同时,决策控制才是人工智能领域要解决的核心问题。计算机视觉等感知问题要求输入感知信息到计算机,计算机能够理解,而决策控制问题则要求计算机能够根据感知信息进行判断思考,输出正确的行为。要使计算机能够很好地决策控制,要求计算机具备一定的“思考”能力,使计算机能够通过学习来掌握解决各种问题的能力,而这正是通用人工智能(Artificial General Intelligence,AGI)(即强人工智能)的研究目标。通用人工智能是要创造出一种无需人工编程自己学会解决各种问题的智能体,最终目标是实现类人级别甚至超人级别的智能。
通用人工智能的基本框架即是增强学习(Reinforcement Learning,RL)的框架,如图1所示。
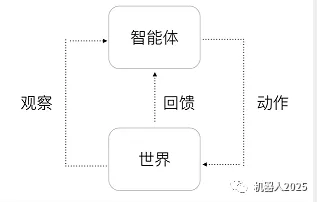
智能体的行为都可以归结为与世界的交互。智能体观察这个世界,然后根据观察及自身的状态输出动作,这个世界会因此而发生改变,从而形成回馈返回给智能体。所以核心问题就是如何构建出这样一个能够与世界交互的智能体。深度增强学习将深度学习(Deep Learning)和增强学习(Reinforcement Learning)结合起来,深度学习用来提供学习的机制,而增强学习为深度学习提供学习的目标。这使得深度增强学习具备构建出复杂智能体的潜力,也因此,AlphaGo的第一作者David Silver认为深度增强学习等价于通用人工智能DRL=DL+RL=Universal AI。
深度增强学习的Actor-Critic框架
目前深度增强学习的算法都可以包含在Actor-Critic框架下,如图2所示。

把深度增强学习的算法认为是智能体的大脑,那么这个大脑包含了两个部分:Actor行动模块和Critic评判模块。其中Actor行动模块是大脑的执行机构,输入外部的状态s,然后输出动作a。而Critic评判模块则可认为是大脑的价值观,根据历史信息及回馈r进行自我调整,然后影响整个Actor行动模块。这种Actor-Critic的方法非常类似于人类自身的行为方式。我们人类也是在自身价值观和本能的指导下进行行为,并且价值观受经验的影响不断改变。在Actor-Critic框架下,Google DeepMind相继提出了DQN,A3C和UNREAL等深度增强学习算法,其中UNREAL是目前最好的深度增强学习算法。下面我们将介绍这三个算法的基本思想。
DQN(Deep Q Network)算法
DQN是Google DeepMind于2013年提出的第一个深度增强学习算法,并在2015年进一步完善,发表在2015年的《Nature》上。DeepMind将DQN应用在计算机玩Atari游戏上,不同于以往的做法,仅使用视频信息作为输入,和人类玩游戏一样。在这种情况下,基于DQN的程序在多种Atari游戏上取得了超越人类水平的成绩。这是深度增强学习概念的第一次提出,并由此开始快速发展。
DQN算法面向相对简单的离散输出,即输出的动作仅有少数有限的个数。在这种情况下,DQN算法在Actor-Critic框架下仅使用Critic评判模块,而没有使用Actor行动模块,因为使用Critic评判模块即可以选择并执行最优的动作,如图3所示。

在DQN中,用一个价值网络(Value Network)来表示Critic评判模块,价值网络输出Q(s,a),即状态s和动作a下的价值。基于价值网络,我们可以遍历某个状态s下各种动作的价值,然后选择价值最大的一个动作输出。所以,主要问题是如何通过深度学习的随机梯度下降方法来更新价值网络。为了使用梯度下降方法,我们必须为价值网络构造一个损失函数。由于价值网络输出的是Q值,因此如果能够构造出一个目标Q值,就能够通过平方差MSE的方式来得到损失函数。但对于价值网络来说,输入的信息仅有状态s,动作a及回馈r。因此,如何计算出目标Q值是DQN算法的关键,而这正是增强学习能够解决的问题。基于增强学习的Bellman公式,我们能够基于输入信息特别是回馈r构造出目标Q值,从而得到损失函数,对价值网络进行更新。
在实际使用中,价值网络可以根据具体的问题构造不同的网络形式。比如Atari有些输入的是图像信息,就可以构造一个卷积神经网络(Convolutional Neural Network,CNN)来作为价值网络。为了增加对历史信息的记忆,还可以在CNN之后加上LSTM长短记忆模型。在DQN训练的时候,先采集历史的输入输出信息作为样本放在经验池(Replay Memory)里面,然后通过随机采样的方式采样多个样本进行minibatch的随机梯度下降训练。
DQN算法作为第一个深度增强学习算法,仅使用价值网络,训练效率较低,需要大量的时间训练,并且只能面向低维的离散控制问题,通用性有限。但由于DQN算法第一次成功结合了深度学习和增强学习,解决了高维数据输入问题,并且在Atari游戏上取得突破,具有开创性的意义。
A3C(Asynchronous Advantage Actor Critic)算法
A3C算法是2015年DeepMind提出的相比DQN更好更通用的一个深度增强学习算法。A3C算法完全使用了Actor-Critic框架,并且引入了异步训练的思想,在提升性能的同时也大大加快了训练速度。A3C算法的基本思想,即Actor-Critic的基本思想,是对输出的动作进行好坏评估,如果动作被认为是好的,那么就调整行动网络(Actor Network)使该动作出现的可能性增加。反之如果动作被认为是坏的,则使该动作出现的可能性减少。通过反复的训练,不断调整行动网络找到最优的动作。AlphaGo的自我学习也是基于这样的思想。
基于Actor-Critic的基本思想,Critic评判模块的价值网络(Value Network)可以采用DQN的方法进行更新,那么如何构造行动网络的损失函数,实现对网络的训练是算法的关键。一般行动网络的输出有两种方式:一种是概率的方式,即输出某一个动作的概率;另一种是确定性的方式,即输出具体的某一个动作。A3C采用的是概率输出的方式。因此,我们从Critic评判模块,即价值网络中得到对动作的好坏评价,然后用输出动作的对数似然值(Log Likelihood)乘以动作的评价,作为行动网络的损失函数。行动网络的目标是最大化这个损失函数,即如果动作评价为正,就增加其概率,反之减少,符合Actor-Critic的基本思想。有了行动网络的损失函数,也就可以通过随机梯度下降的方式进行参数的更新。
为了使算法取得更好的效果,如何准确地评价动作的好坏也是算法的关键。A3C在动作价值Q的基础上,使用优势A(Advantage)作为动作的评价。优势A是指动作a在状态s下相对其他动作的优势。假设状态s的价值是V,那么A=Q-V。这里的动作价值Q是指状态s下a的价值,与V的含义不同。直观上看,采用优势A来评估动作更为准确。举个例子来说,假设在状态s下,动作1的Q值是3,动作2的Q值是1,状态s的价值V是2。如果使用Q作为动作的评价,那么动作1和2的出现概率都会增加,但是实际上我们知道唯一要增加出现概率的是动作1。这时如果采用优势A,我们可以计算出动作1的优势是1,动作2的优势是-1。基于优势A来更新网络,动作1的出现概率增加,动作2的出现概率减少,更符合我们的目标。因此,A3C算法调整了Critic评判模块的价值网络,让其输出V值,然后使用多步的历史信息来计算动作的Q值,从而得到优势A,进而计算出损失函数,对行动网络进行更新。
A3C算法为了提升训练速度还采用异步训练的思想,即同时启动多个训练环境,同时进行采样,并直接使用采集的样本进行训练。相比DQN算法,A3C算法不需要使用经验池来存储历史样本,节约了存储空间,并且采用异步训练,大大加倍了数据的采样速度,也因此提升了训练速度。与此同时,采用多个不同训练环境采集样本,样本的分布更加均匀,更有利于神经网络的训练。
A3C算法在以上多个环节上做出了改进,使得其在Atari游戏上的平均成绩是DQN算法的4倍,取得了巨大的提升,并且训练速度也成倍的增加。因此,A3C算法取代了DQN成为了更好的深度增强学习算法。
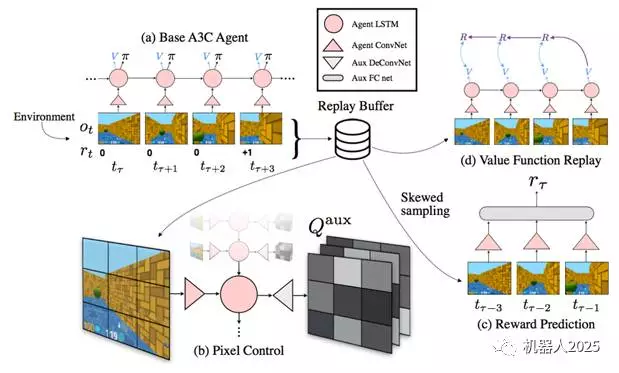
UNREAL(UNsupervised REinforcement and Auxiliary Learning)算法
UNREAL算法是2016年11月DeepMind提出的最新深度增强学习算法,在A3C算法的基础上对性能和速度进行进一步提升,在Atari游戏上取得了人类水平8.8倍的成绩,并且在第一视角的3D迷宫环境Labyrinth上也达到了87%的人类水平,成为当前最好的深度增强学习算法。
A3C算法充分使用了Actor-Critic框架,是一套完善的算法,因此,我们很难通过改变算法框架的方式来对算法做出改进。UNREAL算法在A3C算法的基础上,另辟蹊径,通过在训练A3C的同时,训练多个辅助任务来改进算法。UNREAL算法的基本思想来源于我们人类的学习方式。人要完成一个任务,往往通过完成其他多种辅助任务来实现。比如说我们要收集邮票,可以自己去买,也可以让朋友帮忙获取,或者和其他人交换的方式得到。UNREAL算法通过设置多个辅助任务,同时训练同一个A3C网络,从而加快学习的速度,并进一步提升性能。
在UNREAL算法中,包含了两类辅助任务:第一种是控制任务,包括像素控制和隐藏层激活控制。像素控制是指控制输入图像的变化,使得图像的变化最大。因为图像变化大往往说明智能体在执行重要的环节,通过控制图像的变化能够改善动作的选择。隐藏层激活控制则是控制隐藏层神经元的激活数量,目的是使其激活量越多越好。这类似于人类大脑细胞的开发,神经元使用得越多,可能越聪明,也因此能够做出更好的选择。另一种辅助任务是回馈预测任务。因为在很多场景下,回馈r并不是每时每刻都能获取的(比如在Labyrinth中吃到苹果才能得1分),所以让神经网络能够预测回馈值会使其具有更好的表达能力。在UNREAL算法中,使用历史连续多帧的图像输入来预测下一步的回馈值作为训练目标。除了以上两种回馈预测任务外,UNREAL算法还使用历史信息额外增加了价值迭代任务,即DQN的更新方法,进一步提升算法的训练速度。
UNREAL算法本质上是通过训练多个面向同一个最终目标的任务来提升行动网络的表达能力和水平,符合人类的学习方式。值得注意的是,UNREAL虽然增加了训练任务,但并没有通过其他途径获取别的样本,是在保持原有样本数据不变的情况下对算法进行提升,这使得UNREAL算法被认为是一种无监督学习的方法。基于UNREAL算法的思想,可以根据不同任务的特点针对性地设计辅助任务,来改进算法。
小结
深度增强学习经过近两年的发展,在算法层面上取得了越来越好的效果。从DQN,A3C到UNREAL,精妙的算法设计无不闪耀着人类智慧的光芒。在未来,除了算法本身的改进,深度增强学习作为能够解决从感知到决策控制的通用型学习算法,将能够在现实生活中的各种领域得到广泛的应用。AlphaGo的成功只是通用人工智能爆发的前夜。
作者: Flood Sung,CSDN博主,人工智能方向研究生,专注于深度学习,增强学习与机器人的研究。
原文:http://geek.csdn.net/news/detail/138103
2.深度学习实践:使用Tensorflow实现快速风格迁移
风格迁移简介
风格迁移(Style Transfer)是深度学习众多应用中非常有趣的一种,如图,我们可以使用这种方法把一张图片的风格“迁移”到另一张图片上:

然而,原始的风格迁移(论文地址:https://arxiv.org/pdf/1508.06576v2.pdf)的速度是非常慢的。在GPU上,生成一张图片都需要10分钟左右,而如果只使用CPU而不使用GPU运行程序,甚至需要几个小时。这个时间还会随着图片尺寸的增大而迅速增大。
这其中的原因在于,在原始的风格迁移过程中,把生成图片的过程当做一个“训练”的过程。每生成一张图片,都相当于要训练一次模型,这中间可能会迭代几百几千次。如果你了解过一点机器学习的知识,就会知道,从头训练一个模型要比执行一个已经训练好的模型要费时太多。而这也正是原始的风格迁移速度缓慢的原因。
快速风格迁移简介
那有没有一种方法,可以不把生成图片当做一个“训练”的过程,而当成一个“执行”的过程呢?答案是肯定的。这就这篇快速风格迁移(fast neural style transfer):Perceptual Losses for Real-Time Style Transfer and Super-Resolution
快速风格迁移的网络结构包含两个部分。一个是“生成网络”(原文中为Transformation Network),一个是“损失网络”(Loss Network)。生成网络接收一个图片当做输入,然后输出也是一张图片(即风格迁移后的结果)。如下图,左侧是生成网络,右侧为损失网络:

训练阶段:首先选定一张风格图片。训练的目标是让生成网络可以有效生成图片。目标由损失网络定义。
执行阶段:给定一张图片,将其输入生成网络,输出这张图片风格迁移后的结果。
我们可以发现,在模型的“执行”阶段我们就可以完成风格图片的生成。因此生成一张图片的速度非常块,在GPU上一般小于1秒,在CPU上运行也只需要几秒的时间。
快速风格迁移的Tensorflow实现
话不多说,直接上我的代码的Github地址:hzy46/fast-neural-style-tensorflow
还有变换效果如下。
原始图片:

风格迁移后的图片:




以上图片在GPU(Titan Black)下生成约需要0.8s,CPU(i7-6850K)下生成用时约2.9s。
关于快速风格迁移,其实之前在Github上已经有了Tensorflow的两个实现:
-
junrushao1994/fast-neural-style.tf
-
OlavHN/fast-neural-style
但是第一个项目只提供了几个训练好的模型,没有提供训练的代码,也没有提供具体的网络结构。所以实际用处不大。
而第二个模型做了完整的实现,可以进行模型的训练,但是训练出来的效果不是很好,在作者自己的博客中,给出了一个范例,可以看到生成的图片有很多噪声点:

我的项目就是在OlavHN/fast-neural-style的基础上做了很多修改和调整。
一些实现细节
与Tensorflow Slim结合
在原来的实现中,作者使用了VGG19模型当做损失网络。而在原始的论文中,使用的是VGG16。为了保持一致性,我使用了Tensorflow Slim(地址:tensorflow/models)对损失网络重新进行了包装。
Slim是Tensorflow的一个扩展库,提供了很多与图像分类有关的函数,已经很多已经训练好的模型(如VGG、Inception系列以及ResNet系列)。
下图是Slim支持的模型:
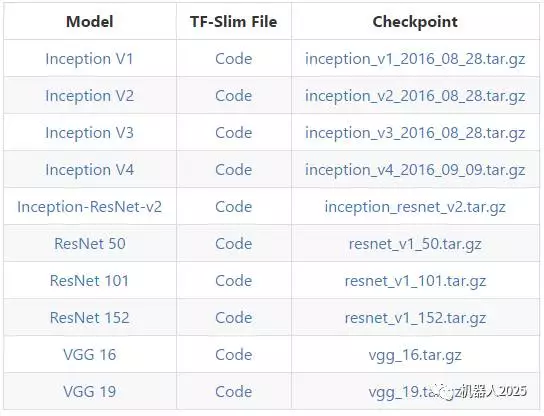
使用Slim替换掉原先的网络之后,在损失函数中,我们不仅可以使用VGG16,也可以方便地使用VGG19、ResNet等其他网络结构。具体的实现请参考源码。
改进转置卷积的两个Trick
原先我们需要使用网络生成图像的时候,一般都是采用转置卷积直接对图像进行上采样。
这篇文章指出了转置卷积的一些问题,认为转置卷积由于不合理的重合,使得生成的图片总是有“棋盘状的噪声点”,它提出使用先将图片放大,再做卷积的方式来代替转置卷积做上采样,可以提高生成图片的质量,下图为两种方法的对比:

对应的Tensorflow的实现:
def resize_conv2d(x, input_filters, output_filters, kernel, strides, training):
with tf.variable_scope('conv_transpose') as scope: height = x.get_shape()[1].value if training else tf.shape(x)[1] width = x.get_shape()[2].value if training else tf.shape(x)[2] new_height = height * strides * 2 new_width = width * strides * 2 x_resized = tf.image.resize_images(x, [new_height, new_width], tf.image.ResizeMethod.NEAREST_NEIGHBOR) shape = [kernel, kernel, input_filters, output_filters] weight = tf.Variable(tf.truncated_normal(shape, stddev=0.1), name='weight') return conv2d(x_resized, input_filters, output_filters, kernel, strides)以上为第一个Trick。
第二个Trick是文章 Instance Normalization: The Missing Ingredient for Fast Stylization 中提到的,用 Instance Normalization来代替通常的Batch Normalization,可以改善风格迁移的质量。
注意使用Optimizer和Saver
这是关于Tensorflow实现的一个小细节。
在Tensorflow中,Optimizer和Saver是默认去训练、保存模型中的所有变量的。但在这个项目中,整个网络分为生成网络和损失网络两部分。我们的目标是训练好生成网络,因此只需要去训练、保存生成网络中的变量。在构造Optimizer和Saver的时候,要注意只传入生成网络中的变量。
找出需要训练的变量,传递给Optimizer:
variable_to_train = []
for variable in tf.trainable_variables():
if not(variable.name.startswith(FLAGS.loss_model)):
variable_to_train.append(variable) train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step=global_step, var_list=variable_to_train)总结
总之是做了一个还算挺有趣的项目。代码不是特别多,如果只是用训练好的模型生成图片的话,使用CPU也可以在几秒内运行出结果,不需要去搭建GPU环境。建议有兴趣的同学可以自己玩一下。(再贴下地址吧:hzy46/fast-neural-style-tensorflow)
作者:何之源,复旦大学计算机科学硕士在读,研究方向为人工智能以及机器学习的应用。
来源:公众号黑信息
3.行为识别:让机器学会“察言观色”第一步
电影短片《Changing Batteries》讲了这样一个故事:独居的老奶奶收到儿子寄来的一个机器人,这机器人善于察言观色,很快就跟老奶奶“心有灵犀”,不仅能在老奶奶口渴时为她端水、在老奶奶扫地时接过老奶奶的扫把,做力所能及的家务活,如果老奶奶在椅子上看电视睡着了,机器人还为她轻轻盖上踏足。有了它,老奶奶又重新感受到久违的快乐,过上了更轻松的生活[1]……咳咳,催泪的故事讲完了,接下来我们先说说这机器人的察言观色技能是怎么实现的。
在人工智能研究领域,这一技能叫人体行为识别,是智能监控、人机交互、机器人等诸多应用的一项基础技术。以电影提到的老人智能看护场景为例,智能系统通过实时检测和分析老人的行动,判断老人是否正常吃饭、服药、是否保持最低的运动量、是否有异常行动出现(例如摔倒), 从而及时给予提醒,确保老人的生活质量不会由于独自居住而有所降低。第二个例子是人机交互系统,通过对人的行为进行识别,猜测用户的“心思”,预测用户的意图,及时给予准确的响应。第三个例子是医院的康复训练,通过对动作行为的规范程度做出识别,评估恢复程度以提供更好的康复指导等。
俗话说“排骨好吃,骨头难啃”,行为识别是一项具有挑战性的任务,受光照条件各异、视角多样性、背景复杂、类内变化大等诸多因素的影响。对行为识别的研究可以追溯到1973年,当时Johansson通过实验观察发现,人体的运动可以通过一些主要关节点的移动来描述,因此,只要10-12个关键节点的组合与追踪便能形成对诸多行为例如跳舞、走路、跑步等的刻画,做到通过人体关键节点的运动来识别行为[2]。正因为如此,在Kinect的游戏中,系统根据深度图估计出的人体骨架(Skeleton,由人体的一些关节点的位置信息组成),对人的姿态动作进行判断,促成人机交互的实现。另一个重要分支则是基于RGB视频做行为动作识别。与RGB信息相比,骨架信息具有特征明确简单、不易受外观因素影响的优点。我们在这里主要探讨基于骨架的行为识别及检测。
人体骨架怎么获得呢?主要有两个途径:通过RGB图像进行关节点估计(Pose Estimation)获得[3][4],或是通过深度摄像机直接获得(例如Kinect)。每一时刻(帧)骨架对应人体的K个关节点所在的坐标位置信息,一个时间序列由若干帧组成。行为识别就是对时域预先分割好的序列判定其所属行为动作的类型,即“读懂行为”。但在现实应用中更容易遇到的情况是序列尚未在时域分割(Untrimmed),因此需要同时对行为动作进行时域定位(分割)和类型判定,这类任务一般称为行为检测。
基于骨架的行为识别技术,其关键在于两个方面:一方面是如何设计鲁棒和有强判别性的特征,另一方面是如何利用时域相关性来对行为动作的动态变化进行建模。
我们采用基于LSTM (Long-Short Term Memory)的循环神经网络(RNN)来搭建基础框架,用于学习有效的特征并且对时域的动态过程建模,实现端到端(End-to-End)的行为识别及检测。关于LSTM的详细介绍可参考[5]。我们的工作主要从以下三个方面进行探讨和研究:
-
如何利用空间注意力(Spatial Attention)和时间注意力(Temporal Attention)来实现高性能行为动作识别 [8]?
-
如何利用人类行为动作具有的共现性(Co-occurrence)来提升行为识别的性能[7]?
-
如何利用RNN网络对未分割序列进行行为检测(行为动作的起止点的定位和行为动作类型的判定)[9]?
空时注意力模型(Attention)之于行为识别

注意力模型(Attention Model)在过去这两年里成了机器学习界的“网红”,其想法就是模拟人类对事物的认知,将更多的注意力放在信息量更大的部分。我们也将注意力模型引入了行为识别的任务,下面就来看一下注意力模型是如何在行为识别中大显身手的。
时域注意力:众所周知,一个行为动作的过程要经历多个状态(对应很多时间帧),人体在每个时刻也呈现出不同的姿态,那么,是不是每一帧在动作判别中的重要性都相同呢?以“挥拳”为例,整个过程经历了开始的靠近阶段、挥动拳脚的高潮阶段以及结束阶段。相比之下,挥动拳脚的高潮阶段包含了更多的信息,最有助于动作的判别。依据这一点,我们设计了时域注意力模型,通过一个LSTM子网络来自动学习和获知序列中不同帧的重要性,使重要的帧在分类中起更大的作用,以优化识别的精度。
空域注意力:对于行为动作的判别,是不是每个关节点在动作判别中都同等重要呢?研究证明,一些行为动作会跟某些关节点构成的集合相关,而另一些行为动作会跟其它一些关节点构成的集合相关。比如“打电话”,主要跟头、肩膀、手肘和手腕这些关节点密切相关,同时跟腿上的关节点关系很小,而对“走路”这个动作的判别主要通过腿部节点的观察就可以完成。与此相适应,我们设计了一个LSTM子网络,依据序列的内容自动给不同关节点分配不同的重要性,即给予不同的注意力。由于注意力是基于内容的,即当前帧信息和历史信息共同决定的,因此,在同一个序列中,关节点重要性的分配可以随着时间的变化而改变。
图1.2展示了网络框架图。时域注意力子网络 (Temporal Attention)学习一个时域注意力模型来给不同帧分配合适的重要性,并以此为依据对不同帧信息进行融合。空域注意力子网络(Spatial Attention)学习一个时域注意力模型来给不同节点分配合适的重要性,作用于网络的输入关节点上。

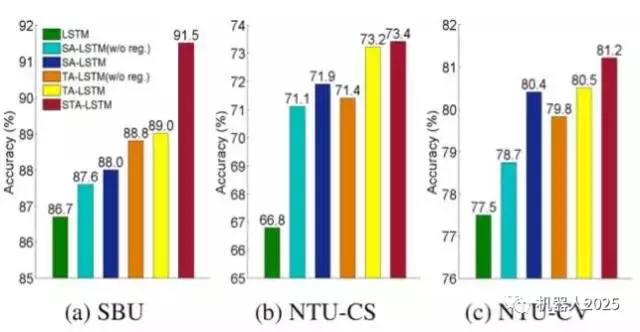
空时注意力模型能带来多大的好处呢?我们在SBU 数据库、NTU RGB+D 数据库的Cross Subject(CS) 和 Cross View(CV) 设置上分别进行了实验,以检测其有效性。图1.3展示了性能的比较:LSTM表示只有主LSTM网络时的性能(没引入注意力模型)。当同时引入时域注意力(TA)和空域注意力(SA)网络后,如STA-LSTM所示,识别的精度实现了大幅提升。
细心的读者可能已经发现,序列中的空域注意力和时域注意力具体为多大是没有参考的(不知道Groundtruth)。网络是以优化最终分类性能来自动习得注意力。那么,学到的注意力模型分配的注意力数值是什么样呢?我们可视化并分析了空时注意力模型的输出。图1.4可视化了在 “挥拳”行为动作的测试序列上,模型输出的空域注意力权重的大小,时域注意力权重值 以及相邻帧时域注意力的差值。如图1.4(a)中所示,主动方(右侧人)的节点被赋予了更大的权值,且腿部的节点更加活跃。图(b)展示了时域注意力的变化,可以看到,时域注意力随着动作的发展逐渐上升,相邻帧时域注意力差值的变化则表明了帧间判别力的增量。时域注意力模型会对更具判别力的帧赋予较大的注意力权重。对不同的行为动作,空间注意力模型赋予较大权重的节点也不同,整体和人的感知一致。

LSTM网络框架和关节点共现性(Co-occurrence)的挖掘之于行为识别
欣赏完“网红”的魅力之后,我们还是回归一下LSTM网络的本真吧。近年来,除了在网络结构上的探索,如何在网络设计中利用人的先验知识以及任务本身的特性来提升性能,也越来越多地受到关注。
着眼于人的行为动作的特点,我们将行为动作中关节点具有的共现性特性引入到LSTM网络设计中,将其作为网络参数学习的约束来优化识别性能。人的某个行为动作常常和骨架的一些特定关节点构成的集合,以及这个集合中节点的交互密切相关。如要判别是否在打电话,关节点“手腕”、“手肘”、“肩膀”和“头”的动作最为关键。不同的行为动作与之密切相关的节点集合有所不同。例如对于“走路”的行为动作,“脚腕”、“膝盖”、“臀部”等关节点构成具有判别力的节点集合。我们将这种几个关节点同时影响和决定判别的特性称为共现性(Co-occurrence)。

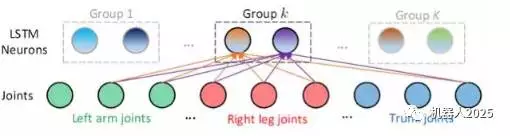
在训练阶段,我们在目标函数中引入对关节点和神经元相连的权重的约束,使同一组的神经元对某些关节点组成的子集有更大的权重连接,而对其他节点有较小的权重连接,从而挖掘关节点的共现性。如图2.2所示,一个LSTM 层由若干个LSTM神经元组成,这些神经元被分为K组。同组中的每个神经元共同地和某些关节点有更大的连接权值(和某类或某几类动作相关的节点构成关节点子集),而和其他关节点有较小的连接权值。不同组的神经元对不同动作的敏感程度不同,体现在不同组的神经元对应于更大连接权值的节点子集也不同。在实现上,我们通过对每组神经元和关节点的连接加入组稀疏(Group Sparse)约束来达到上述共现性的挖掘和利用。
关节点共现性约束的引入,在SBU数据库上带来了3.4%的性能改进。通过引入Dropout技术,最终实现了高达90.4%的识别精度。
基于联合分类和回归的循环神经网络之于行为动作检测

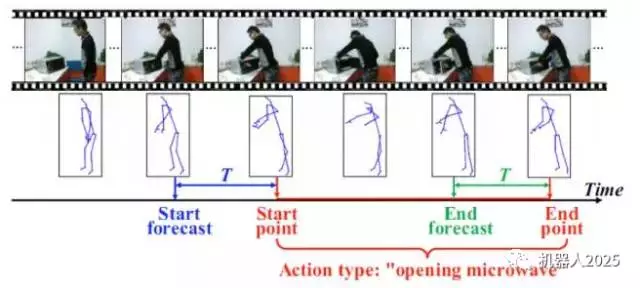
前面讨论了对于时域分割好的序列的行为动作分类问题。但是想要计算机get到“察言观色”的技能并不那么容易。在实际的应用中多有实时的需求,而摄像头实时获取的视频序列并没有根据行为动作的发生位置进行预先时域分割,因此识别系统不仅需要判断行为动作的类型,也需要定位行为动作发生的位置,即进行行为动作检测。如图3.1所示,对于时间序列流,检测系统在每个时刻给出是否当前是行为动作的开始或结束,以及行为动作的类型信息。

在线(Online)的行为动作检测常常采用滑窗的方法,即对视频序列流每次观察一个时间窗口内的内容,对其进行分类。然而基于滑窗的方法常常伴随着冗余的计算,性能也会受到滑动窗口大小的影响。
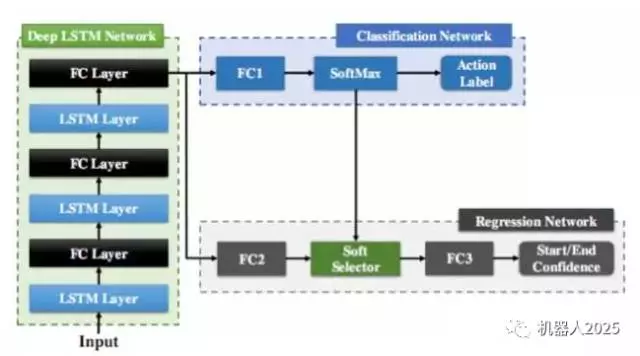
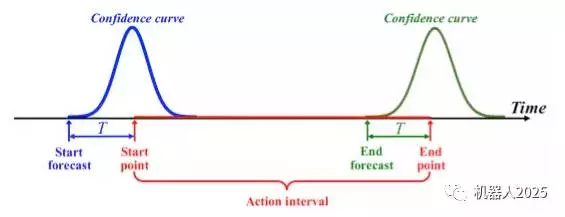
对于骨架序列流,我们设计了基于循环神经网络LSTM的在线行为动作检测系统,在每帧给出行为动作判定的结果。LSTM的记忆性可以避免显式的滑动窗口设计。如图3.3所示,网络由LSTM 层和全连层(FC Layer)组成前端的网络Deep LSTM Network, 后面连接的分类网络 (Classification Network)用于判定每帧的动作类别,同时,回归网络 ( Regression Network )用于辅助确定动作行为的起止帧。图3.4展示了该回归子网络对起止点位置的目标回归曲线,即以起始点(结束点)为中心的高斯形状曲线。在测试时,当发现代表起始点的回归曲线到达局部峰值时,便可以定位为行为动作的起点位置。由于LSTM网络对时间序列处理的强大能力,加上联合分类回归的设计,联合分类和回归循环网络(JCR-RNN)实现了快速准确的行为动作检测。
总结和展望
由于行为识别技术在智能监控、人机交互、视频序列理解、医疗健康等众多领域扮演着越来越重要的角色,研究人员正使出“洪荒之力”提高行为识别技术的准确度。说不定在不久的某一天,你家门口真会出现一个能读懂你的行为、和你“心有灵犀”的机器人,对于这一幕,你是不是和我们一样充满期待?
[1] https://movie.douban.com/subject/25757903/
[2] Gunnar Johansson. Visual perception of biological motion and a model for it is analysis. Perception and Psychophysics 14(2), pp 201–211, 1973.
[3] Alejandro Newell, Kaiyu Yang, Jia Deng. Stacked Hourglass Networks for Human Pose Estimation, In ECCV, 2016.
[4] Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh. Realtime Multi-person 2D Pose Estimation using Part Affinity Fields. arXiv preprint arXiv:1611.08050, 2016.
[5] http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[6] CVPR2011 Tutorial on Human Activity Recognition.
http://michaelryoo.com/cvpr2011tutorial/
[7] Wentao Zhu, Cuiling Lan, Junliang Xing, Wenjun Zeng, Yanghao Li, Li Shen, Xiaohui Xie. Co-Occurrence Feature Learning for Skeleton Based Action Recognition Using Regularized Deep LSTM Networks. In AAAI, 2016.
[8] Sijie Song, Cuiling Lan, Junliang Xing, Wenjun Zeng, Jiaying Liu. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. Accepted by AAAI, 2017.
[9] Yanghao Li, Cuiling Lan, Junliang Xing, Wenjun Zeng, Chunfeng Yuan, Jiaying Liu. Online Human Action Detection Using Joint Classification-Regression Recurrent Neural Networks. In ECCV, 2016.
作者简介:兰翠玲博士,微软亚洲研究院副研究员,从事计算机视觉,信号处理方面的研究。她的研究兴趣包括行为识别、姿态估计、深度学习、视频分析、视频压缩和通信等,并在多个顶级会议,期刊上发表了近20篇论文,如AAAI, ECCV, TCSVT等。
来源::微软研究院AI头条,授权CSDN发布。