记一次并发和事务探索过程
一、前情提要
1、事务的相关概念和集成过程就不在这里重复,可看本人另一篇https://blog.csdn.net/qq_20475615/article/details/93713519
2、这次主要是探索并发中数据的问题,场景是电商系统下单减库存,mysql,暂没涉及分布式和集群
3、所有测试我们先预设原商品库存为100,且我们通过用户不同来指定休眠更好的看效果,admin为休眠的用户它下单1个商品,另一个请求下单3个商品
二、实践过程
- 脏读,代码如下
@Transactional(rollbackFor = Exception.class,isolation = Isolation.READ_UNCOMMITTED)
@Override
public boolean checkAndLockStock(Map goodsMap, String orderId) {
if(null == goodsMap){
throw BusinessException.of(BusinessMessageEnum.E_ERROR);
}
List logs = Lists.newArrayList();
for(Map.Entry entry:goodsMap.entrySet()){
MallGoods goods = this.getById(entry.getKey());
if(ObjectUtils.isEmpty(entry.getValue()) || ObjectUtils.isEmpty(goods.getStock()) || goods.getStock() < entry.getValue()){
throw new BusinessException(BusinessMessageEnum.E_AMOUNT_NOT_ENOUGH.getMsg());
}
boolean result = this.baseMapper.updateGoods(goods.getId(),entry.getValue());
if("admin".equals(securityUtil.getCurrUser().getUsername())){
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// throw BusinessException.of(BusinessMessageEnum.E_ERROR);
}
if(!result){
throw BusinessException.of(BusinessMessageEnum.E_ERROR);
}
}
return true;
} 首先是admin请求先发,然后更新后不提交事务,进入休眠,接着另一个用户请求过来发现读到的数据已经是admin没提交的事务的数据,如果在休眠后让admin那个线程回滚,脏读就出现了
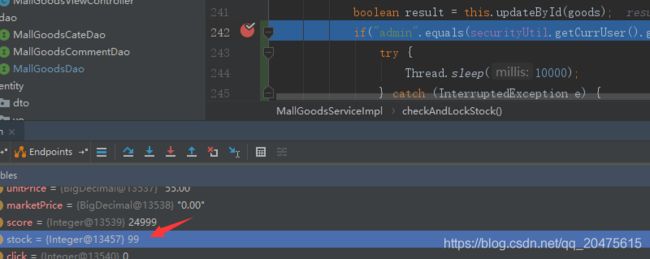
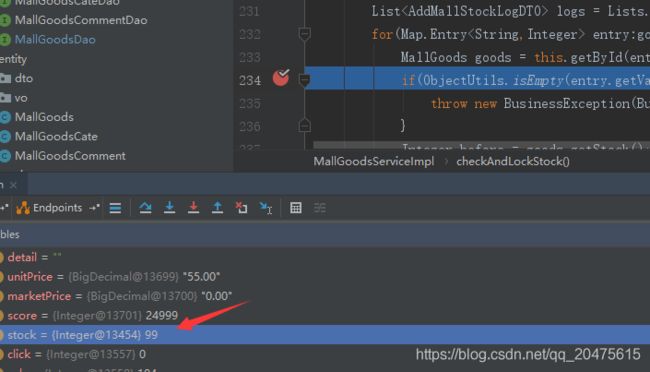
把隔离级别改一下就可以了
@Transactional(rollbackFor = Exception.class,isolation = Isolation.READ_COMMITTED)
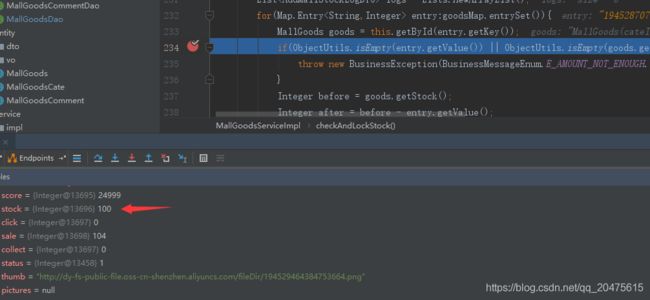
- 丢失更新:有一类和二类,一类是事务回滚把别人更新的也回滚了,二类是把人家改的覆盖了
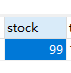
隔离级别为 READ_COMMITTED 脏读没了,但是在admin请求过来后更新了数据但不提交事务,另一个请求过来一阵操作并更新了数据提交事务,然后admin休眠到了才提交事务,结果另一个请求东西没了,本来结果应该是去掉 3+1,为96,但数据库结果是99,也就是前面先提交事务的减3不见了
改级别
@Transactional(rollbackFor = Exception.class,isolation = Isolation.REPEATABLE_READ)
- 事务A先查询后更新,不提交事务,此时有写锁,事务B来查询后再更新,阻塞,等A先提交事务之后B才能更新
- 事务A先查询后休眠,此时不会锁,事务B来查询后再更新,提交事务,A更新再提交事务
REPEATABLE_READ 是在写的时候给该条数据加锁,前面更新的事务没提交后面的事务是提交不了因为数据被锁住了。 这个级别保证的就是修改数据的提交顺序
实际上比如减少库存在这个REPEATABLE_READ 隔离级别下还出现数据错乱是因为在业务先查询之后计算,再保存计算的值有问题,它保证的是你写完的数据不丢失,而不是保证你读完到写完,比如我一开始用的
Integer before = goods.getStock();
Integer after = before - entry.getValue();
goods.setStock(after);
boolean result = this.updateById(goods);而更新的顺序其实是没问题的,假如自己写sql用 update t_mall_goods set stock = stock - #{value} where id = #{id} ,保证顺序性之后拿最新的值而不是预先计算好,则没问题。
那假如我们没有这个顺序性呢,就导致A更新后还没提交,B更新后没有限制直接提交,那A刚才update拿的即使是最新值也没用,那个最新值在B更新之前的,结果就是B的更新没有了
- SERIALIZABLE
上面说到 REPEATABLE_READ不保证读完到写完,SERIALIZABLE 便可以,最严格的老师,只要它读过,别人就只能读不能写,就相当于我看你一眼你就是我老婆,剩下的别人只能看不能动了,得等到我放你自由
- 死锁
用 REPEATABLE_READ 解决,是加写锁,这在商品里会带来的问题,下订单整个事务可能涉及多个商品,而如果两个请求各锁住一个商品,各自等对方的事务提交,就死锁了。
@Transactional(rollbackFor = Exception.class,isolation = Isolation.REPEATABLE_READ)
@Override
public boolean checkAndLockStock() {
Map goodsMap = Maps.newLinkedHashMap();
if("admin".equals(securityUtil.getCurrUser().getUsername())){
goodsMap.put("194528707925250048",1);
goodsMap.put("152869740279238656",1);
}
if("general".equals(securityUtil.getCurrUser().getUsername())){
goodsMap.put("152869740279238656",2);
goodsMap.put("194528707925250048",2);
}
for(Map.Entry entry:goodsMap.entrySet()){
MallGoods goods = this.getById(entry.getKey());
if(ObjectUtils.isEmpty(entry.getValue()) || ObjectUtils.isEmpty(goods.getStock()) || goods.getStock() < entry.getValue()){
throw new BusinessException(BusinessMessageEnum.E_AMOUNT_NOT_ENOUGH.getMsg());
}
boolean result = this.baseMapper.updateGoods(goods.getId(),entry.getValue());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(!result){
throw BusinessException.of(BusinessMessageEnum.E_ERROR);
}
}
return true;
} 上面故意让两个订单下两个相同商品,但是相互执行顺序调换,结果

实际上这种问题之所以出现因为我是单个商品更新的,如果商品是批量更新,尽管底层还是一条条执行,但这个时间差很小,没有在业务层一条条更新这么大的时间差,就基本不会有这种在业务层出现死锁的问题。
其实我这里是为了看效果用了LinkedHashMap按照我们存入的顺序,实际上用HashMap,存储不按我们的顺序再hash之后,存储重叠的商品读取出来前后顺序都是一致的。但如果用的其它结构比如直接商品实体的list之类的,就需要注意这个死锁问题。
三、解决
如果希望自己读完到写完的过程中在业务层进行计算又能最后数据保持一致,可以使用下面的几种方式
1、代码锁:这种就是简单粗暴,代码上加 synchronized 锁
- 如果锁整个方法就可能处理并发性能很差,相当于队列,一个个请求处理;
- 那优化一下只锁住比如操作数据库那块代码,稍微好了些,但是这种在不同商品减库存的时候也因为锁而阻塞的,其实这完全没必要,不同商品减库存互不干扰所以不会产生库存问题;
- 再优化一下,我们对于每个商品加锁,这样不同商品减库存就不会因为竞争锁而不能操作,只有涉及同个商品的才会竞争;
2、悲观锁:这种就是用前先锁住,其他人等着
- 共享锁/读锁/S锁:大家都只能读,可加S,但不能加X,select stock from t_mall_goods where id='' lock in share mode,(这个不能解决上面的问题,这里只是拓展)
- 排它锁/写锁/X锁:不管三七二十一,for update 先锁上,别人只能看不能动,别人看也不能用S或者X来锁,select stock from t_mall_goods where id='' for update,后面更新完了提交完事务了才能让别人去动
3、乐观锁:这种就是大家都能改,最后看谁快,慢的就回滚或者再获取新值进行操作
- 旧值:可以利用某一列作为参考(选择的这个列需要注意ABA问题,也就是A查到100,B从100改为90,C又改回100,A以为没变就去改动但这个100不是原来的,详情请自查资料),比如选择update_time,在第一次查询获取到的值比如设为 before_update_time,然后在更新时把该列放到where中来判断是不是被改过了,update t_mall_goods set stock = #{stock},update_time = now() where id = #{id} and update_time = #{before_update_time}
- 版本:维护一个版本列,原理如同前面的,update t_mall_goods set stock = #{stock},version = version+1 where id = #{id} and version = #{version}
4、记录锁:这种就是类似悲观锁,专门用一个表来作为锁,所有线程去创建一个记录,创建成功的也就是拿到锁,当然这个需要考虑拿锁的线程如果崩了没有及时删除记录导致其它线程都等待到超时了,所以要加个定时任务去处理这个异常记录。