海量数据处理——分治和hash映射
什么是Hash
Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做HASH值. 也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系。
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:
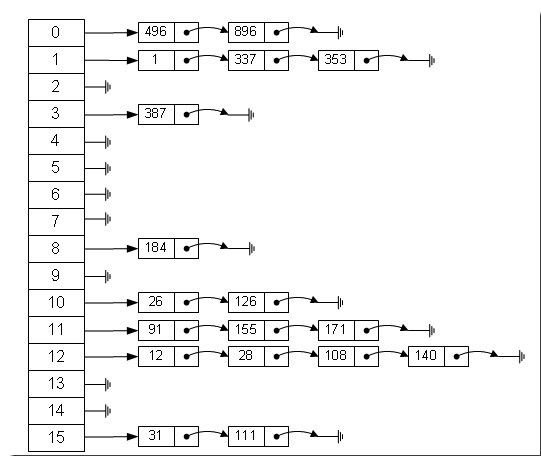
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1,除法散列法
最直观的一种,上图使用的就是这种散列法,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
2,平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28 (右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
3,斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
1,对于16位整数而言,这个乘数是40503
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0,1, 1,2, 3,5, 8,13, 21,34, 55,89, 144,233,377,610, 987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
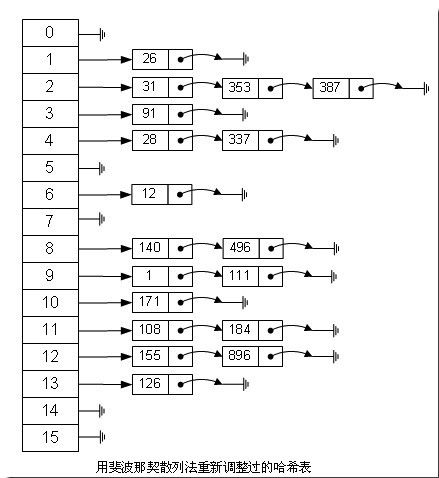
注:用斐波那契散列法调整之后会比原来的取摸散列法好很多。
适用范围
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
基本原理及要点
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
扩展
d-left hashing中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例(海量数据处理)
我们知道hash 表在海量数据处理中有着广泛的应用,下面,请看另一道百度面试题:
题目:海量日志数据,提取出某日访问百度次数最多的那个IP。
方案:IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
方法介绍
对于海量数据而言,由于无法一次性装进内存处理,导致我们不得不把海量的数据通过hash映射分割成相应的小块数据,然后再针对各个小块数据通过hash_map进行统计或其它操作。
那什么是hash映射呢?简单来说,就是为了便于计算机在有限的内存中处理big数据,我们通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小数存放在内存中,或大文件映射成多个小文件),而这个映射散列方式便是我们通常所说的hash函数,设计的好的hash函数能让数据均匀分布而减少冲突。
1、海量日志数据,提取出某日访问百度次数最多的那个IP
分析:百度作为国内第一大搜索引擎,每天访问它的IP数量巨大,如果想一次性把所有IP数据装进内存处理,则内存容量明显不够,故针对数据太大,内存受限的情况,可以把大文件转化成(取模映射)小文件,从而大而化小,逐个处理。
换言之,先映射,而后统计,最后排序。
解法:具体分为以下3个步骤
- 1.分而治之/hash映射
- 首先把这一天访问百度日志的所有IP提取出来,然后逐个写入到一个大文件中,接着采用映射的方法,比如%1000,把整个大文件映射为1000个小文件。
- 2.hash_map统计
- 当大文件转化成了小文件,那么我们便可以采用hash_map(ip, value)来分别对1000个小文件中的IP进行频率统计,再找出每个小文件中出现频率最大的IP。
- 3.堆/快速排序
- 统计出1000个频率最大的IP后,依据各自频率的大小进行排序(可采取堆排序),找出那个频率最大的IP,即为所求。
注:Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中去的情况,即这里采用的是%1000算法,那么同一个IP在hash后,只可能落在同一个文件中,不可能被分散的。
2、寻找热门查询,300万个查询字符串中统计最热门的10个查询
原题:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,请你统计最热门的10个查询串,要求使用的内存不能超过1G。
分析:这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。
由上面第1题,我们知道,数据大则划为小的,例如一亿个ip求Top 10,可先%1000将ip分到1000个小文件中去,并保证一种ip只出现在一个文件中,再对每个小文件中的ip进行hash_map统计并按数量排序,最后归并或者最小堆依次处理每个小文件的top10以得到最后的结果。
但对于本题,数据规模比较小,能一次性装入内存。因为根据题目描述,虽然有一千万个Query,但是由于重复度比较高,故去除重复后,事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去(300万个字符串假设没有重复,都是最大长度,那么最多占用内存3M*1K/4=0.75G。所以可以将所有字符串都存放在内存中进行处理)。
所以我们放弃分而治之/hash映射的步骤,直接上hash_map统计,然后排序。So,针对此类典型的TOP K问题,采取的对策往往是:hash_map + 堆。
解法:
- 1.hash_map统计
- 先对这批海量数据预处理。具体方法是:维护一个Key为Query字串,Value为该Query出现次数的hash_map,即hash_map(Query, Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并将Value值设为1;如果该字串在Table中,那么将该字串的计数加1 即可。最终我们在O(N)的时间复杂度内用hash_map完成了统计;
- 2.堆排序
- 借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(n) + N' * O(logk),其中,N为1000万,N’为300万。
关于第2步堆排序,可以维护k个元素的最小堆,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>...kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(x入堆,用时logk),否则不更新堆。这样下来,总费时O(k_logk+(n-k)_logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk。
当然,你也可以采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。
3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词
解法:
- 1.分而治之/hash映射
- 顺序读取文件,对于每个词x,取hash(x)%5000,然后把该值存到5000个小文件(记为x0,x1,...x4999)中。这样每个文件大概是200k左右。当然,如果其中有的小文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。
- 2.hash_map统计
- 对每个小文件,采用trie树/hash_map等统计每个文件中出现的词以及相应的频率。
- 3.堆/归并排序
- 取出出现频率最大的100个词(可以用含100个结点的最小堆)后,再把100个词及相应的频率存入文件,这样又得到了5000个文件。最后就是把这5000个文件进行归并(类似于归并排序)的过程了。
4、海量数据分布在100台电脑中,想个办法高效统计出这批数据的TOP10
解法一:
如果同一个数据元素只出现在某一台机器中,那么可以采取以下步骤统计出现次数TOP10的数据元素:
- 1.堆排序
- 在每台电脑上求出TOP 10,可以采用包含10个元素的堆完成(TOP 10小,用最大堆,TOP 10大,用最小堆,比如求TOP10大,我们首先取前10个元素调整成最小堆,如果发现,然后扫描后面的数据,并与堆顶元素比较,如果比堆顶元素大,那么用该元素替换堆顶,然后再调整为最小堆。最后堆中的元素就是TOP 10大)。
- 2.组合归并
- 求出每台电脑上的TOP 10后,然后把这100台电脑上的TOP 10组合起来,共1000个数据,再利用上面类似的方法求出TOP 10就可以了。
解法二:
但如果同一个元素重复出现在不同的电脑中呢,比如拿两台机器求top 2的情况来说:
- 第一台的数据分布及各自出现频率为:a(50),b(50),c(49),d(49) ,e(0),f(0)
- 其中,括号里的数字代表某个数据出现的频率,如a(50)表示a出现了50次。
- 第二台的数据分布及各自出现频率为:a(0),b(0),c(49),d(49),e(50),f(50)
这个时候,你可以有两种方法:
- 遍历一遍所有数据,重新hash取摸,如此使得同一个元素只出现在单独的一台电脑中,然后采用上面所说的方法,统计每台电脑中各个元素的出现次数找出TOP 10,继而组合100台电脑上的TOP 10,找出最终的TOP 10。
- 或者,暴力求解:直接统计统计每台电脑中各个元素的出现次数,然后把同一个元素在不同机器中的出现次数相加,最终从所有数据中找出TOP 10。
5、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序
解法一:
- 1.hash映射
- 顺序读取10个文件,按照hash(query)%10的结果将query写入到另外10个文件(记为a0,a1,..a9)中。这样新生成的文件每个的大小大约也1G(假设hash函数是随机的)。
- 2.hash_map统计
- 找一台内存在2G左右的机器,依次对用hash_map(query, query_count)来统计每个query出现的次数。注:hash_map(query, query_count)是用来统计每个query的出现次数,不是存储他们的值,出现一次,则count+1。
- 3.堆/快速/归并排序
- 利用快速/堆/归并排序按照出现次数进行排序,将排序好的query和对应的query_cout输出到文件中,这样得到了10个排好序的文件(记为)。最后,对这10个文件进行归并排序(内排序与外排序相结合)。
解法二:
一般query的总量是有限的,只是重复的次数比较多而已,可能对于所有的query,一次性就可以加入到内存了。这样,我们就可以采用trie树/hash_map等直接来统计每个query出现的次数,然后按出现次数做快速/堆/归并排序就可以了。
解法三:
与解法1类似,但在做完hash,分成多个文件后,可以交给多个文件来处理,采用分布式的架构来处理(比如MapReduce),最后再进行合并。
6、给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
解法:
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 1.分而治之/hash映射
- 遍历文件a,对每个url求取,然后根据所取得的值将url分别存储到1000个小文件(记为,这里漏写个了a1)中。这样每个小文件的大约为300M。遍历文件b,采取和a相同的方式将url分别存储到1000小文件中(记为)。这样处理后,所有可能相同的url都在对应的小文件()中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
- 2.hash_set统计
- 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
7、100万个数中找出最大的100个数
解法一:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100万*100)。
解法二:采用快速排序的思想,每次分割之后只考虑比轴大的一部分,知道比轴大的一部分在比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100万*100)。
解法三:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100万*lg100)。
举一反三
1、怎么在海量数据中找出重复次数最多的一个?
提示:先做hash,然后求模映射为小文件,求出每个小文件中重复次数最多的一个,并记录重复次数。然后找出上一步求出的数据中重复次数最多的一个就是所求(具体参考前面的题)。
2、上千万或上亿数据(有重复),统计其中出现次数最多的前N个数据。
提示:上千万或上亿的数据,现在的机器的内存应该能存下。所以考虑采用hash_map/搜索二叉树/红黑树等来进行统计次数。然后就是取出前N个出现次数最多的数据了,可以用第2题提到的堆机制完成。
3、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
提示:这题是考虑时间效率。用trie树统计每个词出现的次数,时间复杂度是O(nle)(le表示单词的平准长度)。然后是找出出现最频繁的前10个词,可以用堆来实现,前面的题中已经讲到了,时间复杂度是O(nlg10)。所以总的时间复杂度,是O(nle)与O(nlg10)中较大的哪一个。
4、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
提示:这题用trie树比较合适,hash_map也行。当然,也可以先hash成小文件分开处理再综合。
5、一个文本文件,找出前10个经常出现的词,但这次文件比较长,说是上亿行或十亿行,总之无法一次读入内存,问最优解。
提示:首先根据用hash并求模,将文件分解为多个小文件,对于单个文件利用上题的方法求出每个文件件中10个最常出现的词。然后再进行归并处理,找出最终的10个最常出现的词。