在计算型函数前面加上两行:from numba import jit @jit可提速近100倍
在自定义的计算型函数前面加上两行:
from numba import jit
@jit可以提速近100倍(非计算的函数反可能会降速).例:
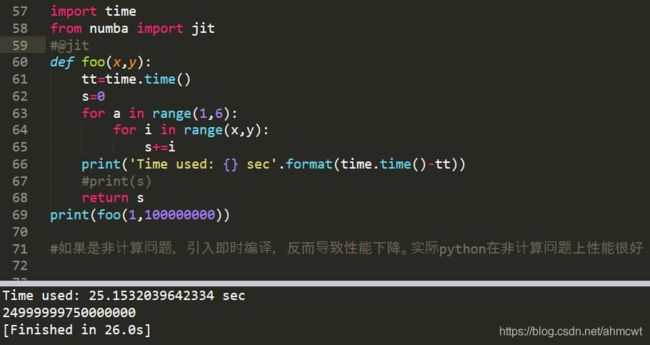
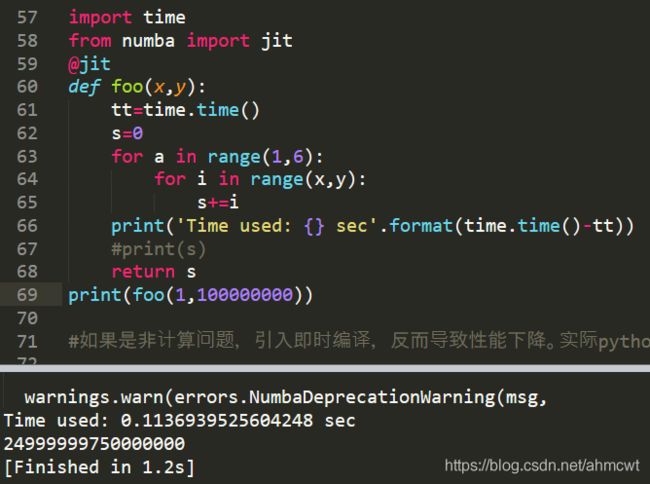
import time
from numba import jit
@jit #加上这句可以提速近100倍
def foo(x,y):
tt=time.time()
s=0
for a in range(1,6):
for i in range(x,y):
s+=i
print('Time used: {} sec'.format(time.time()-tt))
#print(s)
return s
print(foo(1,100000000))
#如果是非计算问题,引入即时编译,反而导致性能下降。实际python在非计算问题上性能很好
---------------------------------------
Time used: 25.1532039642334 sec
24999999750000000
[Finished in 26.0s]
---------------------------------------
warnings.warn(errors.NumbaDeprecationWarning(msg,
Time used: 0.1136939525604248 sec
24999999750000000
[Finished in 1.2s]
详见转:https://blog.csdn.net/qq_39241986/article/details/102486661
(注,原文代码直接复制运行可能会出错,本文例可以直复用,但会有警告提示)
树莓派安装numba时出错,参考https://blog.csdn.net/T_infinity/article/details/93317077
numba官方文档http://numba.pydata.org/numba-doc/latest/user/installing.html
下载numba
git clone git://github.com/numba/numba.gitnumba之前先装 https://llvmlite.readthedocs.io/en/latest/admin-guide/install.html
https://blog.csdn.net/weixin_37446411/article/details/55095767?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159218707519724848340064%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159218707519724848340064&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v3~pc_rank_v2-3-55095767.first_rank_ecpm_v3_pc_rank_v2&utm_term=%E6%A0%91%E8%8E%93%E6%B4%BE+numba+%E5%AE%89%E8%A3%85
所需资源:https://releases.llvm.org/download.html#3.9.1
https://pypi.org/simple/awkward-numba/