背景
基于本公司使用es场景,不需要分词功能.而es string 类型的时候,会自动分词,导致省份、地区等字段都分词了。
具体使用方式
创建 elasticsearc 模板(_template),使用命令:
curl -XPUT localhost:9200/_template/dmp_down_result -d '
{
"template" : "dmp_down_*", #定义模板名字,以dmp_down_ 开始的索引将使用此模板
"settings": {
"number_of_shards": 14, #设置分片数量
"number_of_replicas": 1, #设置副本数
"index.refresh_interval": "30s" #刷新间隔(可不设置)
},
"aliases" : {
"dmp_down_result" : {} #别名
},
"mappings" : {
"dmp_es_result1":{ #索引中的type名字,需要与被建索引一致
"properties": #具体字段映射设置
{"user_id": { #hive数据中的字段,必须与此对应
"type" : "multi_field", #类型 多媒体
"fields" : {
"user_id" : {"type" : "string", "index" : "not_analyzed"} , #类型 string,not_analyzed:为不使用分词,使用分词为:analyzed
}
},
"phone": {
"type" : "multi_field",
"fields" : {
"imei" : {"type" : "string", "index" : "not_analyzed"}
}
},
"address": {
"type" : "multi_field",
"fields" : {
"idfa" : {"type" : "string", "index" : "not_analyzed"}
}
}
}
}}
}
}
} '
创建完模板后,可通过http://localhost:9200/_template 来查看是否生效
由此完成创建操作.下附图
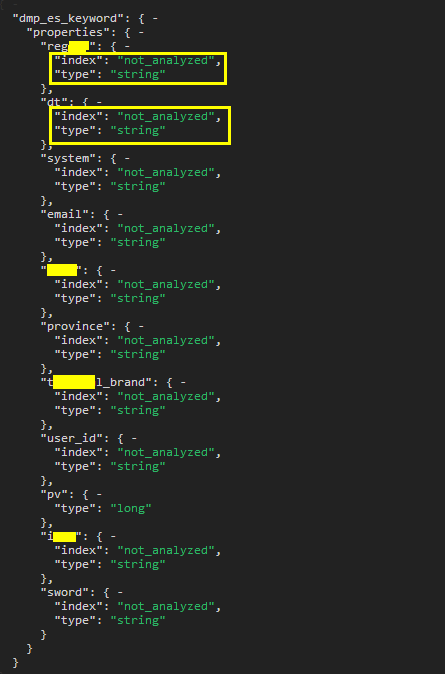
导入数据如报:maybe it contains illegal characters? 此错误时,在导入时是无法排查的,可通过手动创建索引/type 方式来查看具体错误信息.如:{"error":{"root_cause":[{"type":"remote_transport_exception","reason":"[dmp_es-16][10.8.1.16:9300][indices:admin/create]"}],"type":"illegal_state_exception","reason":"index and alias names need to be unique, but alias [dmp_keyword_result] and index [dmp_keyword_result] have the same name"},"status":500} 这样可以更直观的看出问题.索引名重复,重新启一个索引名字就可以了.
附:es-hadoop hive数据同步方法:
下载eslaticsearch-hadoop jar包,需要与当前elasticsearch 版本相对应
将eslaticsearch-hadoop jar上传到集群
在hive命令行中 执行:add jar /home/hdroot/ elasticsearch-hadoop-2.2.0.jar
建表命令:
CREATE EXTERNAL TABLE dmp_es_result2(
user_id string,
imei string,
idfa string,
email string,
type_id array
province string,
region string,
dt string,
terminal_brand string,
system string)
STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource' = '索引名/类型',
'es.index.auto.create' = 'true',
'es.nodes'='localhost',
'es.port' = '9200',
'es.field.read.empty.as.null' ='true');
es.resource:指定同步到es 中的索引名/类型名
es.index.auto.create:是否使用主动主键,如不使用可指定es.mapping.id=主键
es.nodes:es集群节点地址,任意一个节点就可以,多个可以用逗号(,)分开如:192.168.1.1:9200,192.168.1.2:9200
es.port:es集群端口号,如es.nodes指定了多个,此可以不使用
es.field.read.empty.as.null:对空、null字段的处理方式。加上此参数可以使数据导入更准备(此处有点不太确定)
导入数据hive语句:
INSERT OVERWRITE TABLE dmp_es_result2 select user_id,imei,idfa,email,type_id,province,region,dt,terminal_brand,system from temp_zy_game_result01;
如果执行成功,就可以看到es中的数据同步过去了.