STL中的空间配置器allocator的实现原理及源码剖析
allocator是STL为自己的模版容器所设计的标准空间配置器。处于std命名空间下
今天我要讲的的allocator的源码在我的github上,地址为 mySTL 是我模仿标准STL写出的代码,并添加了注释。
allocator简介
allocator为一个模版类,我们使用的时候一般都会将其绑定到一个具体的类型上。如下:
allocator<int> alc;allocator需要实现如下功能:
- 将底层的
alloc(内存分配器,只分配以字节为单位的原始内存,并构建了自己的内存池)封装起来,只保留以对象大小为单位的内存分配 - 对
alloc分配出来的地址空间进行placement new构造 - 对自身构造出来的内容进行对应的析构(需要和构造进行配对,比如用
allocator构造的对象一般只允许被allocator所析构)
allocator就只做这几件事情:分配内存、构造对象、析构对象、释放内存
在我们的印象中,分配内存和构造对象好像是一件事情,比如如果我们有A这个类,那么我们要使用A的时候,一般都会这么使用:
A a;
//或者
A *pA=new A();都是将构造和内存分配放在了一起,但是allocator却将这两件事情分开来处理
这有什么好处呢?直接将构造和内存分配放在一起不好吗?
平常的小规模的用户级使用当然是OK的,但是对于STL容器来说就不那么OK了,试想一下
vector的实现 —— 每次当空间不够用的时候都要将所有的对象从以前的位置复制到新的内存空间的位置,如果我们采用构造和内存分配一体化的话,vector的空间扩张需要做哪些工作:
- 找到一块更大的内存空间,并同时在上面对所有的内存实行对象的默认构造函数以实现对象的构造
- 将旧的空间的对象一个个通过拷贝构造函数赋值给新空间的被默认初始化的新对象,实现对象的移动
- 析构旧的空间的对象,然后回收内存空间
思考一下执行了多少次无用的构造?两次,一次默认初始化,一次拷贝初始化
如果里面有一百万个对象,则会用到巨大的cpu时间去做很多本来不需要的默认构造工作。
那么这两个构造函数的使用可以被避免吗?当然可以
如何避免?使用placement new 将内存分配和对象的构造分隔开来 (具体的可以参考博客【C++】 深入探究 new 和 delete)
所以,当我们使用allocator进行STL容器中的对象移动的时候,做了那些事情:
- 找到一块更大的内存空间
- 在这块内存空间上对每一块内存(对象大小的内存块)直接根据旧的空间上的对应位置的对象实行一对一的
placement new构造- 释放旧空间的内存
想一下节约了多少的无用的构造函数,STL为了提高效率真是无所不用其极
allocator源码剖析
空间配置器allocator
其实空间配置器allocator真正的的源码非常短,以下是我自己写的allocator对象,可以看到,allocator基本上只实现了以下几个方法:
construct():placement new指定地址构造对象allocate(): 内存空间分配(按对象的大小为单位从alloc中获取)destroy():operator delete指定地址析构对象deallocate(): 内存空间的回收(释放给alloc进行管理)
源码:
#ifndef _ALLOCATOR_H_
#define _ALLOCATOR_H_
#include::allocate() {
return static_cast(alloc::allocate(sizeof(T)));
}
template<class T>
T *allocator::allocate(size_t n) {
if (n == 0) return 0;
return static_cast(alloc::allocate(sizeof(T) * n));
}
template<class T>
void allocator::deallocate(T *ptr) {
alloc::deallocate(static_cast<void *>(ptr), sizeof(T));
}
template<class T>
void allocator::deallocate(T *ptr, size_t n) {
if (n == 0) return;
alloc::deallocate(static_cast<void *>(ptr), sizeof(T)* n);
}
template<class T>
void allocator::construct(T *ptr) {//调用default placement new
STL::construct(ptr,T());
}
template<class T>
void allocator::construct(T *ptr, const T& value) {//带参调用 placement new
STL::construct(ptr, value);
}
template<class T>
void allocator::destroy(T *ptr) {// 调用 operator delete 去析构 T
STL::destroy(ptr);
}
template<class T>
void allocator::destroy(T *first, T *last) {
STL::destroy(first,last);
}
}
#endif 可以看到,construct和destroy都是调用的STL命名空间下的对应函数,为什么要这样做,同样也是为了提高效率。
让我们思考一下,对于存储普通的简单对象的内存空间(没有显式的析构函数)
我们直接将其空间释放掉就可以直接完成内存空间的释放,而不需要在中间执行析构函数和`for`循环(因为它并没有显式的析构函数)
如何才能在运行的时候知道什么时候不执行一大堆的析构函数,什么时候又需要执行呢?
我们用了一个型别萃取的方式去获取到它是否是一个简单对象来判断其是否需要执行析构函数,以下为construct.h头文件:
#ifndef _CONSTRUCT_H_
#define _CONSTRUCT_H_
#include"type_traits.h"
#include::has_trivial_destructor trivial_destoructor;
__destroy_aux(first, last, trivial_destoructor());
}
template<class ForwardIterator>
inline void __destroy_aux(ForwardIterator first, ForwardIterator last, STL::__true_type) {}
template<class ForwardIterator>
void __destroy_aux(ForwardIterator first, ForwardIterator last, STL::__false_type) {
for (; first < last; ++first) {
destroy(&*first);
}
}
}
#endif 可以看到我们在执行destroy的时候并不是直接就执行pointer->~T();,而是通过调用__destroy_aux的方式进行destroy,同时还要传入一个__type_traits类型中的对应对象:
STL::__type_traits::has_trivial_destructor trivial_destoructor;
__destroy_aux(first, last, trivial_destoructor());为什么要传入一个__type_traits中的对象类型和调用__destroy_aux?前面说过了,为了实现对简单对象和复杂对象调用不同的函数以实现效率最大化
__type_traits 的实现如下:
struct __true_type {};
struct __false_type {};
templatetype>
struct __type_traits
{
typedef __false_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_constructor;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
template<>
struct __type_traits
{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_constructor;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
template<>
struct __type_traits
{
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_constructor;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
....
....
....
一大堆的模版特化类 可以看到,__true_type和__false_type都是一个空类,所以并不存在内存的损耗(相对于这样做的好处来说),这个类将你传入的对象的真实属性发掘出来,然后根据不同的has_trivial_destructor返回不同的对象类型,产生__true_type或者__false_type,然后传入__destroy_aux,__destroy_aux函数定义如下:
inline void __destroy_aux(ForwardIterator first, ForwardIterator last, STL::__true_type) {}
template<class ForwardIterator>
void __destroy_aux(ForwardIterator first, ForwardIterator last, STL::__false_type) {
for (; first < last; ++first) {
destroy(&*first);
}
}很容易就能发现,当传入的对象类型为__true_type的时候,执行的是一个空的函数体,这样就不用再进入for循环去做大量的无用功
关于特性萃取的详细说明下章也许会讲到,但是并不影响我们了解allocator的实现
二级配置器
看完了上层的空间配置器allocator的实现,现在让我们来看一看支撑其实现的二级空间配置器alloc(同样在我的github上有源码),二级空间配置器就更加简单了,只负责两件事情:
- 分配和回收以字节为单位的连续的、原始的内存空间(不负责对象的析构和构造)
- 维护一个自由链表去响应分配和回收比较小的内存空间的处理(如果申请的内存空间大于128字节,则使用二级空间配置器中的C函数
malloc( )和free( )去申请内存空间)
你可能会想,为什么要维护一个这样的自由链表呢?不是会造成很多的空间的浪费吗?
的确,这样的一个自由链表会带来额外的性能开销和内存负担,但是相对于其好处来说,又是值得的。因为容器中存放的空间是会被经常的释放和申请(大部分的对象都是小于128字节的),如果大量的分配和释放小额的区块,就会导致大量的内存碎片的产生。
碎片的产生还在其次。但申请越小的内存,操作系统维护这块内存的造成的损耗比例就越大。
为什么呢?思考一下,当你向操作系统申请一块内存的时候,操作系统并不是直接就将这么大的一整个内存块交给你,而是会多申请一块内存空间去管理你要申请的这块内存,如图:
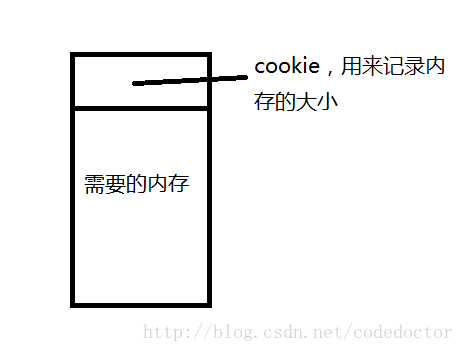
可以看到,每次我们申请一块内存,都会向操作系统缴税,你申请的空间越小,cookie占得比例就越大。所以二级配置器解决这种损耗的方法就是,每次都给内存池中申请一大块的内存空间,并且用多条自由链表对这块内存进行维护
每次如果需要空间,则先判断其大小,如果不大于128字节,则直接从链表中拔出大小适当的节点区块(如果不足,则向内存池进行申请新的空间),如果要释放,则将这个区块还原(记住,alloc不仅负责申请,也同样负责释放,而且这时候不能简单的使用free去释放你从链表中申请的空间,因为其没有头部的cookie信息)
好吧,说了这么多,我们还是先来看一下alloc这个类是如何实现的吧。
以下是alloc的头文件代码:
#ifndef _ALLOC_H_
#define _ALLOC_H_
#include这个头文件中,唯一值得说的只有这个:
union obj {// free_lists 的节点
union obj* free_list_link;
char client_data[1];
};这个就是我们所说的自由链表的节点,你也许会想,维护刚才我所说的这样的链表岂不是也会造成像cookie那样的损耗吗。
但注意,上面用的节点是一个union,从它的第一个成员来看,obj是一个指针,指向另一个相同大小的节点。从它的第二个成员来看,obj被视为一个指针,指向实际的区块的首地址。
这样的一物二用,就不会为了维护链表而造成新的浪费
具体的这个链表的实现和维护我就不再贴了,代码量还是很大的,如果有兴趣,可以去我的github的mySTL上围观源码。
一级配置器
不多说了,就是用malloc、free、oom_malloc、oom_realloc几个C语言函数进行构建的,负责用户申请大区块空间时的空间配置器,封装在alloc中
ok,over~