机器学习自动化 要学习什么_如何自动化机器学习
机器学习自动化 要学习什么
Paolo Tamagnini,Simon Schmid和Christian Dietz是KNIME的数据科学家和软件工程师。
是否有可能完全自动化数据科学生命周期? 是否可以根据一组数据自动构建机器学习模型?
确实,在最近几个月中,出现了许多声称可以自动化全部或部分数据科学过程的工具。 它们如何运作? 你能自己建造一个吗? 如果采用这些工具之一,则需要花费多少工作才能使其适应您自己的问题和自己的数据集?
通常,为机器学习自动化或AutoML付出的代价是黑匣子模型的失控。 您从自动化中获得的东西,会在微调或可解释性上失去。 尽管这样的价格对于定义明确的域中的外接数据科学问题可能是可以接受的,但它可能成为在更广泛的域中更复杂的问题的限制。 在这些情况下,需要与最终用户进行一定程度的交互。
在KNIME ,我们采用一种较软的方法来进行机器学习自动化。 我们的引导式自动化 - 引导式分析的一个特殊实例-利用全自动的Web应用程序来指导用户选择,培训,测试和优化多种机器学习模型。 该工作流程专为业务分析人员设计,可以利用他们的领域知识轻松创建预测分析解决方案。
在本文中,我们将从网络浏览器运行时,从业务分析师的角度展示此应用程序的步骤。 在后续文章中,我们将展示幕后实现,详细说明用于特征工程,机器学习,离群值检测,特征选择,参数优化和模型评估的技术。
机器学习自动化的指导性分析
使用引导式自动化,我们不打算通过完全自动化过程来代替驱动程序。 相反,我们提供帮助,并且允许在整个建模过程中随时收集反馈。 数据科学家为最终用户开发了一种指导性自动化应用程序。 要取得成功,它需要:
- 最终用户易于使用(例如,从Web浏览器执行)
- 一组GUI交互点,用于收集首选项并显示结果
- 可伸缩性选项
- 在后台运行的灵活,广泛,敏捷的数据科学软件应用程序
灵活,广泛和敏捷是指数据科学应用程序,它允许组装复杂的数据和机器学习操作,并易于与其他数据科学工具,数据类型和数据源集成。
通常,引导式自动化应用程序可以使多种机器学习模型的开发自动化。 在这种情况下,我们需要自动化数据科学周期的以下部分以创建通用分类模型:
- 资料准备
- 特征工程
- 参数优化
- 功能选择
- 模型训练
- 模型评估
- 模型部署
在最终用户看来,最终应用程序看起来很简单,但在后台运行的系统可能会非常复杂,因此,要完全从头开始创建并不容易。 为了帮助您完成此过程,我们创建了一个交互式应用程序的蓝图,用于自动创建机器学习分类模型。
该蓝图是使用KNIME分析平台开发的,可以在我们的公共资源库中找到 。
机器学习指导自动化的蓝图
引导式自动化蓝图的主要概念包括几个基本步骤:
- 资料上传
- 通过人机交互定义应用程序设置
- 根据先前定义的设置自动进行模型训练和优化
- 具有性能摘要和模型下载的仪表板
 尼米
尼米
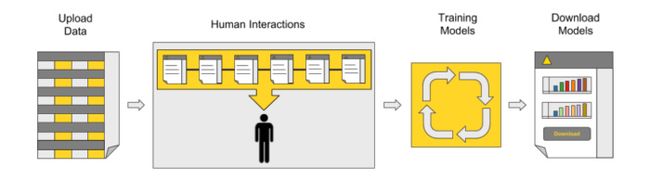
图1:指导性自动化蓝图背后的主要过程:数据上传,应用程序设置,自动模型训练和优化,性能比较仪表板和模型下载。
蓝图(图1)中实施的当前过程适用于标准的预测分析问题。 但是,当我们处理数据问题时,标准很少出现。 通常,由于特殊的数据类型,数据结构或仅已有的专家知识,必须对输入数据应用自定义处理。 有时,训练和测试集可能需要遵循特定的规则,例如时间顺序。
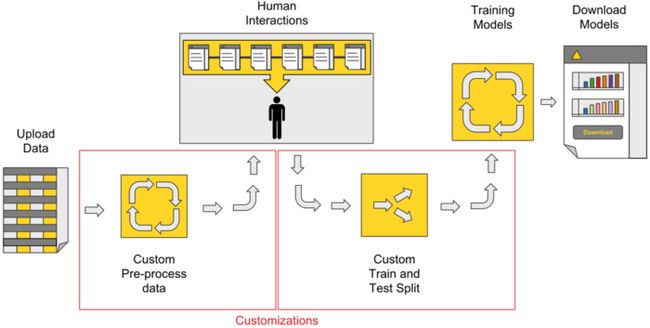
图2显示了对先前过程的可能定制,包括定制数据预处理和定制训练/测试拆分。您可以轻松地将这些定制应用于KNIME Analytics Platform中的蓝图。 由于它具有可视化的编程框架,因此无需编码。
 尼米
尼米
图2:引导自动化的可能定制。 在这种情况下,自定义数据准备和自定义训练/测试拆分将添加到流程中。
指导性的机器学习自动化:逐步实现Web浏览器
让我们通过KNIME Server从Web浏览器中查看自动化制图 。
首先,我们将看到一系列交互点:
- 上载资料
- 选择目标变量
- 删除不必要的功能
- 选择一种或多种机器学习算法进行训练
- (可选)自定义参数优化和功能工程设置
- 选择执行平台
输入的功能可以根据业务分析师自身的专业知识或功能相关性的度量来删除。 我们使用的相关性度量是基于列的缺失值和值分布; 缺失值太多,值太恒定或值散布太远的列将受到惩罚。
自定义参数优化和功能工程是可选的。 通过对可自定义参数范围进行网格搜索来实现参数优化。 如果启用了要素工程,则首先使用许多选定的要素组合和转换,然后进行最终的要素选择。
就执行平台而言,有一些选项可用,从您自己的本地计算机(默认)到基于Spark的平台或其他分布式执行平台 。
用于所有交互点的网页模板在下面的图3中进行了汇总,其右侧包括对所需任务的描述,顶部包括应用程序流程图。 将来的步骤以灰色显示,过去的步骤以黄色显示,而当前步骤仅以黄色框显示。
 尼米
尼米
图3:此图遵循Web浏览器中指导自动化的蓝图执行:(1)上载数据集文件; (2)选择目标变量; (3)过滤掉不需要的列; (4)选择训练算法; (5)定义执行环境。 流程图的顶部是整个过程的导航栏。
定义所有设置后,应用程序将在后台执行步骤。 选定的输入要素将经过数据预处理(处理缺失值和异常值),要素创建和转换,参数优化和要素选择以及最终模型的再培训和评估(就准确性度量和计算性能而言)。
在这里,我们到达了自动化指导旅程的终点。 该应用程序返回一个仪表盘,在该仪表盘中,将比较所选机器学习模型的准确性和执行速度。
在测试集上计算出ROC曲线 , 精度度量 , 增益或提升图以及混淆矩阵 ,并显示在最终的着陆页中以比较精度度量(图4)。
 尼米
尼米
图4:指导性自动化蓝图最后一页中的仪表板。 仪表板的顶部包含用于模型性能评估的图表。 所有经过训练的模型的累积视图包括:(1)准确性的条形图(蓝色)和AUC得分(红色); (2)ROC曲线。 每个模型的单一视图包括:(3)混淆矩阵热图和(4)累积增益图。 每个模型在仪表板中都有一行来承载单个视图。
在训练和部署期间评估模型执行速度。 部署执行速度被衡量为运行单个输入的预测的平均速度。 因此,两个条形图分别以秒为单位显示模型训练时间,以毫秒为单位显示产生单个预测的平均时间(图5)。
所有仪表板视图都是交互式的。 可以更改绘图设置,并且可以即时探索数据可视化。
 尼米
尼米
图5:在这里我们看到了显示执行速度的仪表板部分。 顶部的条形图以秒为单位显示训练时间; 底部的柱状图显示了部署期间单个预测的平均时间(以毫秒为单位)。
现在可以下载模型了。 在最终仪表板的末尾,您将找到下载一个或多个经过训练的模型以供将来使用的链接,例如,将其作为生产中的RESTful API。
要获得完整的自动化指导经验,您可以在此演示视频中观看实际应用程序:“ 机器学习自动化的指导分析 ”。
适用于业务分析师的机器学习
在本文中,我们描述了用于指导机器学习自动化的KNIME蓝图,并说明了所需的步骤。 这个工作流程驱动的Web应用程序代表了我们对半自动(引导式)机器学习应用程序的解释。 在我们的下一篇文章中,我们将了解幕后的实现。
通过KNIME Analytics平台实现并在本文中介绍的蓝图可以免费下载 ,根据需要进行定制并可以免费重用。 通过在Knime服务器上运行相同的应用程序,可以执行基于Web的工作流程。
现在,该从该蓝图开始创建一个指导性机器学习应用程序。 通过这种方式,您可以使业务分析师能够轻松地从Web浏览器创建和训练机器学习模型。
KNIME的数据科学家Paolo Tamagnini拥有罗马萨皮恩扎大学的数据科学硕士学位,并拥有纽约大学的数据可视化技术研究经验,以实现机器学习的可解释性。
Simon Schmid目前正在德国康斯坦茨大学攻读计算机科学硕士学位。 他的研究兴趣是机器学习的自动化。 自2016年以来,他一直在KNIME担任软件工程师。 他现在位于德克萨斯州的奥斯汀,完成了进一步的实习,更加深入地探索了机器学习的指导自动化。
克里斯蒂安·迪茨(Christian Dietz)拥有斯图加特商业与管理学院的商业信息学文凭,并获得了康斯坦茨大学计算机科学的硕士学位。 在康斯坦茨大学(University of Konstanz)担任研究程序员之后,他在该大学开发了生物图像分析和机器学习领域的框架和库,然后加入KNIME担任软件工程师。 他最近的一些项目包括针对KNIME Analytics Platform的深度学习,H2O机器学习和图像处理集成。
有关KNIME的更多信息,请访问www.knime.com和KNIME博客 。
-
新技术论坛提供了一个以前所未有的深度和广度探索和讨论新兴企业技术的场所。 选择是主观的,是基于我们选择的技术,我们认为这些技术对InfoWorld读者来说是重要的,也是他们最感兴趣的。 InfoWorld不接受发布的营销担保,并保留编辑所有贡献内容的权利。 将所有查询发送到 newtechforum@infoworld.com 。
这个故事“如何使机器学习自动化”最初由InfoWorld发布 。
翻译自: https://www.idginsiderpro.com/article/3333802/how-to-automate-machine-learning.html
机器学习自动化 要学习什么