
- 来源 | 愿码(ChainDesk.CN)内容编辑
- 愿码Slogan | 连接每个程序员的故事
- 网站 | http://chaindesk.cn
- 愿码愿景 | 打造全学科IT系统免费课程,助力小白用户、初级工程师0成本免费系统学习、低成本进阶,帮助BAT一线资深工程师成长并利用自身优势创造睡后收入。
- 官方公众号 | 愿码 | 愿码服务号 | 区块链部落
- 免费加入愿码全思维工程师社群 | 任一公众号回复“愿码”两个字获取入群二维码
本文阅读时长:9min
本文说明了如何运用Python API使用Twitter库连接到Twitter帐户。具体来说,此API允许用户提取与特定Twitter帐户相关的大量数据,以及通过 Python 管理 Twitter 的帖子(例如一次发布多个推文)。
即使你是 Python 的初学者, 使用 Twitter Python 依赖包在分析方面也非常有用。例如,虽然Web开发人员可能更倾向于使用PHP等语言来连接API,但Python可以更灵活地分析数据的趋势和统计数据。因此,数据科学家和其他分析师会发现Python更适合这个目的。
我们将从Python连接到Twitter API的一些基本步骤开始,然后查看如何流式传输所需的数据。需要注意的是,虽然Twitter库(以及其他Python库,如Tweepy和Twython)可以使用数据执行大量不同的任务,但我们将专注于本文中的一些更基本(和有用)的查询,解决以下问题:
- 使用适当的凭据将Python连接到Twitter API
- 下载与特定帐户关联的推文
- 下载帐户的所有关注和关注用户的列表
- 一次发布多条推文
- 在Twitter上自定义搜索特定术语的实例。
1.将Python连接到Twitter API
本教程使用iPython作为Python接口连接到Twitter。为了连接到API,我们需要获取Consumer Key,Consumer Secret和Access Token Secret。
要获得这些,您需要在apps.twitter.com上登录您的帐户。到那里后,系统会提示您创建一个应用程序:
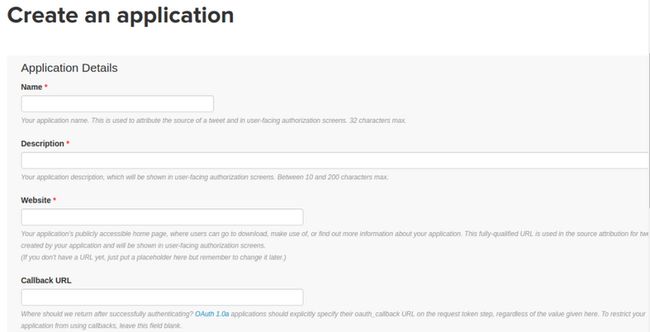
创建应用程序后,您将在Keys and Access Tokens部分下找到相关的密钥和令牌。


首先,我们在终端中安装python-twitter库,如下所示:
pip install python twitter完成后,我们导入Twitter库并输入凭据,如下所示:
import twitter
api = twitter.Api(consumer_key='your_consumer_key',
consumer_secret='your_consumer_secret',
access_token_key='your_access_token_key',
access_token_secret='your_access_token_secret')print(api.VerifyCredentials())输入正确的凭证后,与API的连接即告完成,我们现在可以通过Python平台控制我们的Twitter帐户!
2.下载用户时间线
现在我们已经将Python连接到Twitter API,我们可以继续开始远程使用不同的Twitter功能。例如,如果我们希望下载推文的用户时间线,我们使用如下方法(并指定相应帐户的屏幕名称),然后使用该功能显示结果:
statuses = api.GetUserTimeline(screen_name='Michael Grogan')
print([s.text for s in statuses])一旦我们输入了上述内容,我们就会在Python界面中看到相应的时间轴:

3.下载以下和以下联系人
Twitter库还使我们能够下载特定用户正在关注的帐户列表,以及作为该特定用户的关注者的帐户。为此,我们使用前者,后者使用:
users = api.GetFriends()
print([u.name for u in users])
followers = api.GetFollowers()
print([f.name for f in followers])
请注意,我们还可以设置我们希望获取的用户数的上限。例如,如果我们希望为任何特定帐户获取100个关注者,我们可以通过向total_count函数添加变量来实现,如下所示:
followers = api.GetFollowers(total_count=100)
print([f.name for f in followers])4.发布多个推文
使用Twitter API的一个巧妙之处是能够一次发布多条推文。例如,我们可以使用该命令同时发布以下两条推文(同样,使用该功能进行确认)。一旦我们转到相关的Twitter帐户,我们就会看到这两条推文都已发布:
status = api.PostUpdate('How to calculate the Variance Inflation Factor in R: http://www.michaeljgrogan.com/ordinary-least-squares-an-analysis-of-stock-returns/ #rstats #datascience #programming')
print(status.text)status = api.PostUpdate('#BigData Scientists Earn 10X to 15X More Money Compared to Engineers, CAs http://bit.ly/1NoAgto #datascience')
print(status.text)5.搜索推文
Twitter库中包含的getsearch()函数是一个特别强大的工具。此功能允许我们在Twitter上搜索特定术语。请注意,这适用于已输入特定术语的所有用户,而不仅仅是我们在Python中提供凭据的帐户。
例如,让我们在Python中搜索术语“bigdata”。我们设置的参数是自2016年11月21日起包含该术语的推文,我们选择限制流式传输的推文数量为10:
api.GetSearch(term='bigdata', since=2016-11-21, count=10)
请注意,我们可以通过各种方式自定义GetSearch()函数,具体取决于我们希望如何提取数据。例如,如果没有指定日期,这将花费更长的时间来流式传输,我们也可以选择在2016年11月21日之前收集包含术语“bigdata”的推文,如下所示:
api.GetSearch(term='bigdata', until=2016-11-21, count=10)值得注意的是,此函数在我们在until变量下指定的日期之前下载最多7天的数据。
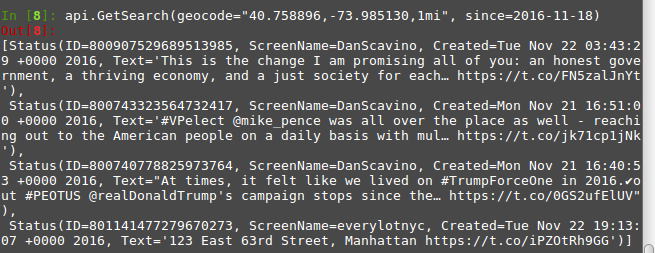
此外,我们不仅限于仅通过术语搜索GetSearch。例如,假设我们希望通过地理位置搜索推文 - 特别是自11月18日以来在纽约时代广场1英里范围内发送的推文(请注意,距离可以使用mi或km分别以英里或公里格式化):
api.GetSearch(geocode="40.758896,-73.985130,1mi", since=2016-11-18)运行该函数后,我们看到Python返回以下推文(当然,还有什么更好的地方可以找到Donald Trump!):GetSearch()
如何使用这些数据?
如前所述,Python对流式社交网络数据极具吸引力的一个特殊原因是能够对我们收集的信息进行深入的数据分析。
例如,我们已经看到了如何使用位置搜索推文GetSearch。随着机器学习在分析社交媒体趋势的数据科学家中风靡一时,在这一领域变得非常流行的一种特殊技术是网络分析。这种技术实际上可以显示分散的数据(或节点)以形成紧密的网络,通常某些节点被证明是一个焦点。例如,假设我们要分析全球十个不同地点的1000条最受欢迎的推文。
在随机的某一天,尽管我们看到网络中不同推文之间存在一些相关性,但我们可能仍会发现伦敦推文上的主题标签与纽约推文的主题标签差别很大。然而,在美国大选之夜或英国退欧这样的重大世界事件中,当Twitter对这一特定主题发展趋势时,发现网络往往更加紧密,因此,在这种情况下,情感分析的机会更多。一个场景,例如,很明显谁将赢得总统职位,或英国投票退出欧盟。人们通常会看到网络以不同的方式聚集,这取决于趋势推文,因为可以获得更多的实时信息。
这只是Python的优势之一。虽然使用API连接到Twitter(可以在许多编程语言中完成)是一回事,但是能够使用分析以有意义的方式对数据进行排序是另一回事。可以通过Python使用机器学习技术来分析来自社交网络的流数据并从该数据进行有意义的预测。
结论
模块文档提供了可用于Python下载,过滤和操作数据的不同功能的非常详细的描述。最后,虽然我们还研究了使用API直接发布到Twitter的方法,但上述技术在分析趋势时尤其有用,例如标签流行度,按位置搜索术语的频率等等。在这方面,通过Python与Twitter交互对于那些希望对收集的信息实施数据分析技术的人特别有用。
当然,与Twitter的API交互可以使用多种语言完成,具体取决于您的最终目标。如果目标是Web开发或设计,那么PHP或Ruby可能是您最好的选择。但是,如果您的目标是使用从Twitter获得的数据进行有意义的分析,那么Python就是不二之选。