车联网属于物联网的一个分支,通过车载终端采集数据,利用无线网络传输到云服务平台进行持久化存储,最终提供基于实时/历史数据的个性化服务。
目前初创型的车辆网企业,接入的车辆通常低于10万,数据采集频率远远大于1秒。这个级别的数据规模,如果采用HBase系的技术方案,需要至少6台8核32G配置的机器,而采用TDengine作为数据存储引擎,一台2核8G的机器就可以完成。
技术架构
TDengine作为时序处理引擎,可以完全不用Kafka、HDFS/HBase/Spark、Redis等软件,大幅简化大数据平台的设计,降低研发成本和运营成本。因为需要集成的开源组件少,因而系统可以更加健壮,也更容易保证数据的一致性。
- 基于HBase的解决方案,架构图如下

- 而基于TDengine的解决方案,架构图如下

数据模型
车载终端采集的数据字段非常多,很多企业按照国标ISO 22901建立数据模型,也有公司按照业务需要使用自定义的数据模型。但通常,采集数据都包含如下字段,本文也采用这种方法构造数据模型。
- 采集时间(时间戳)
- 车辆标志(字符串)
- 经度(双精度浮点)
- 维度(双精度浮点)
- 海拔(浮点)
- 方向(浮点)
- 速度(浮点)
- 车牌号(字符串)
- 车辆型号(字符串)
- 车辆vid(字符串)
不同于其他时序数据引擎,TDengine为每辆车单独创建一张数据表,数据字段为采集时间、车辆标志、经度、纬度、海拔、方向、速度等与时间序列相关的采集数据;标签字段为车牌号、车辆型号等车辆本身固定的描述信息。这里面有一个小技巧,浮点数据压缩比相对整型数据压缩比很差,经度纬度通常精确到小数点后7位,因此将经度纬度增大1E7倍转为长整型存储,将海拔、方向、速度增大1E2倍转为整型存储。
创建数据库的语句为
create database db cache 8192 ablocks 2 tblocks 1000 tables 10000;创建超级表的SQL语句为
create table vehicle(ts timestamp, longitude bigint, latitude bigint, altitude int, direction int, velocity int) tags(card int, model binary(10));以车辆vid作为表名(例如vid为1,车牌号为25746,类型为bmw),那么创建数据表的语句为
create table v1 using tags(25746, ‘bmw’);数据写入
仍然以车辆v1为例,写入一条记录到表v1的SQL语句为
insert into v1 values(1562150939000,1,2,3,4,5);测试数据的生成,可以采用批量数据写入方法,类似
insert into v1 values(1562150939000,1,1,1,1,1) (1562150969000,2,2,2,2,2) (1562150999000,3,3,3,3,3) (……)(……);本文采用C语言编写了一个车辆模拟数据生成程序,该程序首先10万张数据表,然后每张数据表写入1个月的数据(数据间隔1分钟,计44000条数据)
#include
#include
#include
#include
#include "time.h"
#include "taos.h"
int main(int argc, char *argv[]) {
taos_init();
TAOS *taos = taos_connect("127.0.0.1", "root", "taosdata", NULL, 0);
if (taos == NULL) {
printf("failed to connect to server, reason:%s\n", taos_errstr(taos));
exit(1);
}
if (taos_query(taos, "create database db cache 8192 ablocks 2 tblocks 1000 tables 10000") != 0) {
printf("failed to create database, reason:%s\n", taos_errstr(taos));
exit(1);
}
taos_query(taos, "use db");
char sql[65000] = "create table vehicles(ts timestamp, longitude bigint, latitude bigint, altitude int, direction int, velocity int) tags(card int, model binary(10))";
if (taos_query(taos, sql) != 0) {
printf("failed to create stable, reason:%s\n", taos_errstr(taos));
exit(1);
}
int begin = time(NULL);
for (int table = 0; table < 100000; ++table) {
sprintf(sql, "create table v%d using vehicles tags(%d, 't%d')", table, table, table);
if (taos_query(taos, sql) != 0) {
printf("failed to create table t%d, reason:%s\n", table, taos_errstr(taos));
exit(1);
}
for (int loop = 0; loop < 44; loop++) {
int len = sprintf(sql, "insert into v%d values", table);
for (int row = 0; row < 1000; row++) {
len += sprintf(sql + len, "(%ld,%d,%d,%d,%d,%d)", 1561910400000L + 60000L * (row + loop * 1000L), row, row, row, row, row);
}
if (taos_query(taos, sql) != 0) {
printf("failed to insert table t%d, reason:%s\n", table, taos_errstr(taos));
}
}
}
int end = time(NULL);
printf("insert finished, time spend %d seconds", end - begin);
}
} 将改C文件命名为test.c,在相同目录下创建makefile文件
ROOT = ./
TARGET = exe
LFLAGS = -Wl,-rpath,/usr/lib/ -ltaos -lpthread -lm -lrt
CFLAGS = -O3 -g -Wall -Wno-deprecated -fPIC -Wno-unused-result -Wconversion -Wno-char-subscripts -D_REENTRANT -Wno-format -D_REENTRANT -DLINUX -msse4.2 -Wno-unused-function -D_M_X64 -std=gnu99 -I/usr/local/include/taos/
all: $(TARGET)
exe:
gcc $(CFLAGS) ./test.c -o $(ROOT)/test $(LFLAGS)
clean:
rm $(ROOT)test 编译之后,将测试程序和数据库在同一台2核8G的台式机上运行,写入时间共计为3946秒,相当于4400000000条/3946秒=111.5万条/秒,折算成点数为111.5*5=557万点/秒。
insert finished, time spend 3946 seconds该程序是单线程运行的,如将其修改成多线程,速度还会有更大提升,但是仅就目前的性能来看,对于车辆网的场景也已经足够。
数据查询
TDengine在数据查询方面做了很多针对时序数据的优化。基于上面生成的测试数据集进行查询,这是一些常见SQL语句的运行结果,性能还是有点吓人的。
- 查询总数

- 单辆车的明细数据
| 查询类型 | 查询时间 |
|---|---|
| 1车当前值查询 | 2.3ms |
| 1车1小时明细查询 | 2.1ms |
| 1车1日明细查询 | 6.3ms |
| 1车10日明细查询 | 15.4ms |
| 1车31日明细查询 | 31.6ms |
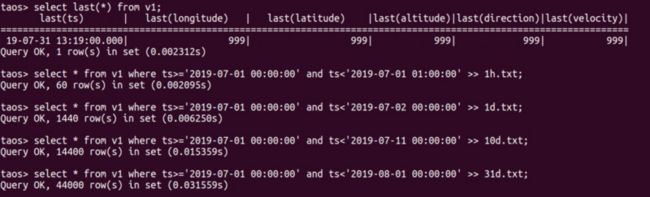
- 单辆车的聚合查询
| 查询类型 | 查询时间 |
|---|---|
| 1车1小时聚合查询 | 1.9ms |
| 1车1日聚合查询 | 1.7ms |
| 1车10日聚合查询 | 2.3ms |
| 1车31日聚合查询 | 2.2ms |

- 多辆车的单日聚合查询
| 查询类型 | 查询时间 |
|---|---|
| 1车单日聚合查询 | 3.2ms |
| 10车单日聚合查询 | 5.1ms |
| 100车单日聚合查询 | 10.4ms |
| 1000车单日聚合查询 | 51.4ms |
| 10000车单日聚合查询 | 455.9ms |
| 100000车单日聚合查询 | 2074.8ms |
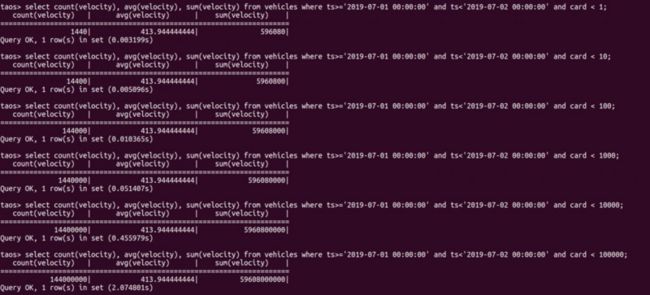
- 多辆车单月聚合查询
| 查询类型 | 查询时间 |
|---|---|
| 1车单月聚合查询 | 3.1ms |
| 10车单月聚合查询 | 4.1ms |
| 100车单月聚合查询 | 7.7ms |
| 1000车单月聚合查询 | 33.7ms |
| 10000车单月聚合查询 | 289.5ms |
| 100000车单月聚合查询 | 1197.ms |

- 多辆车单月曲线查询
| 查询类型 | 查询时间 |
|---|---|
| 1车单月曲线查询 | 6.9ms |
| 10车单月曲线查询 | 13.2ms |
| 100车单月曲线查询 | 75.6ms |
| 1000车单月曲线查询 | 710.9ms |
| 10000车单月曲线查询 | 7137.6ms |
| 100000车单月曲线查询 | 32130.8ms |

- 资源消耗
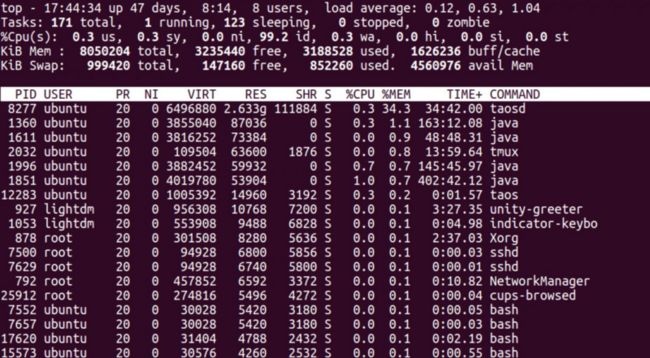
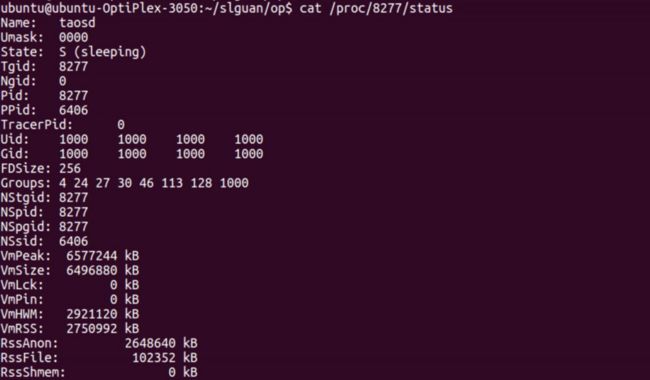
数据库服务进程只消耗了约2.7GB的内存,CPU占用可以忽略不计。
结果分析
TDengine提供的时序数据解决方案,单机情况下的平均写入速度在百万条/秒级别,单辆车的所有查询均能做到实时,多辆车的查询速度也非常快,是车联网乃至物联网的必备利器。
关于 TDengine
TDengine是涛思数据拥有自主知识产权的高性能、可伸缩、高可靠、零管理的物联网大数据平台软件,可以将数据库、缓存、消息队列、流式计算等功能完全融合在一起。由于针对物联网大数据特点做了各种优化,TDengine的数据插入、查询的性能比通用的大数据平台好10倍以上,存储空间也大为节省,采用SQL接口,与第三方软件能无缝集成,大幅简化了物联网平台的系统架构,大幅减少了研发和运维的复杂度与成本。TDengine可广泛运用于物联网、车联网、工业大数据等领域。2019年7月12日,TDengine开源,在GitHub全球趋势排行榜上连续几天排名第一。
目前在GitHub上,TDengine的Star数已超10,000,GitHub地址:https://github.com/taosdata/T... ,欢迎来GitHub上Star我们!
