你肯定遇见过这样的问题:由于某种原因,现场采集的数据,传到应用端的时候少了几条;恰巧又碰到了强迫症的客户。如何解决这种纠结而又蹂躏的情况呢?
有个被虐得很惨的客户找到我们,非常创新地逆向使用TDengine的降维(down sample)功能,使其项目瞬间多了一个非常优秀的亮点:
「我们公司的产品,绝对按照采集周期完美采集,正常情况下,不会丢失任意一条数据!最重要的是,我们的采集周期可以支持到1μs。」
当然,这个功能不是我们凭空想象,凭空捏造出来的,而是基于真实的客户需求产生的。
我们都知道,由于网络的原因,导致不可以避免地在传输过程中,会丢失某个时间戳的数据;特别是在采集周期特别短的情况下,数据量非常大,这种现象就是普遍存在、不可避免的。
但是与我们联系的客户是一家有技术洁癖的公司,一直追求产品的完美,虽然丢失数据这种情况不可避免,但对于他们来说是不能接受的。最开始这个客户了解的功能是这样的:
TDengine支持按时间段进行聚合,可以将表中数据按照时间段进行切割后聚合生成结果,比如温度传感器每秒采集一次数据,但需查询每隔10分钟的温度平均值。这个聚合适合于降维(down sample)操作,语法如下:
SELECT function_list FROM tb_name
[WHERE where_condition]
INTERVAL (interval)
[FILL ({NONE | VALUE | PREV | NULL | LINEAR})]
SELECT function_list FROM stb_name
[WHERE where_condition]
INTERVAL (interval)
[FILL ({ VALUE | PREV | NULL | LINEAR})]
[GROUP BY tags]聚合时间段的长度由关键词INTERVAL指定,官网给出的最短时间间隔10毫秒(10a)。注:聚合查询中,能够同时执行的聚合和选择函数仅限于单个输出的函数:count、avg、sum 、stddev、leastsquares、percentile、min、max、first、last,不能使用具有多行输出结果的函数。
那么如果采集周期和interval是一样的,是不是就实现了补值功能呢?根据客户(一家做芯片监测厂家)的实际场景,比如现场的采集周期是1μs,也就是说在1μs的时间范围内,仅有一条数据,如果丢失了,这个时间戳就没有数据。比如有一个超级表teststb有两个子表,id分别为1和2,原始数据如下图所示,可以看到有些时间点数据是丢失的:
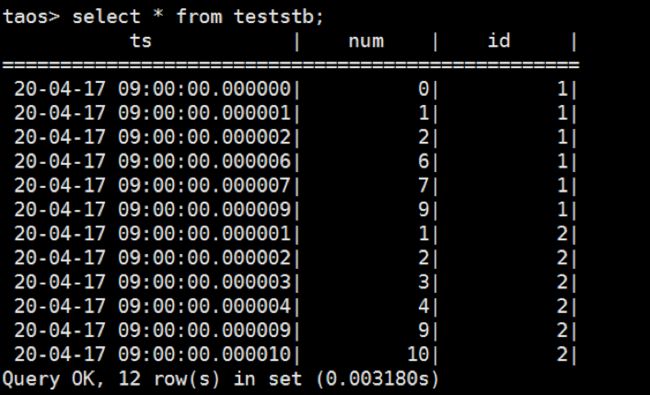
然后,我们创新使用这个函数:select first(num) from teststb where ts >= "2020-04-17 09:00:00.000000" and ts <="2020-04-17 09:00:00.000010" interval (1u) fill(prev) group by id order by ts;
结果如下图所示:
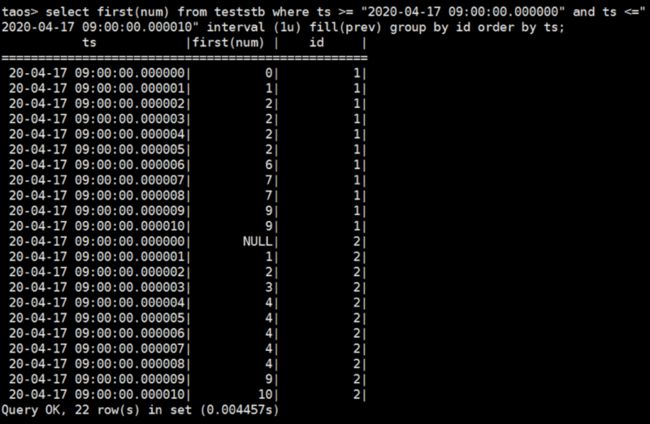
1)interval 的时间范围是 1μs,比官网的 10ms 粒度要小,这是为该客户的场景定制开发的,在版本 1.6.5.8 中已经开放出来了;
2)order by 原来不支持子表之间的排序问题,也为该客户的场景定制解决,目前可以支持 10 万条以内的记录进行排序;
3)使用 first 函数,取 interval 时间范围内的第一条数据,因为 interval 的时间范围和采集周期一致,所以使用 first 得到的就是原来的采样值;
4)如果此 interval 范围内没有数据,也就是采样值丢失了,根据物联网传感器数据相邻两条数据之间波动不大的现象,可以使用 fill(prev),也就是说将此时间戳的数据,填补为前一条正常采样的采样值;
5)但是如果时间 where 开始的时间点,第一条和前面一条都是 null,则 fill(prev)仍然会是 null,这一点需要注意。
这样就实现了,即使在网络环境非常差的情况下,也可以得到接近最真实现场环境的采样数据,方便对实际现场进行数据分析和故障排查。
一个“天下第一等”的功能就此诞生。
我们喜欢和有趣的人一起,做有趣且有意义的事。因此,有任何“新奇特”的想法,请尽管提给我们,也许你的灵机一动和奇思妙想能够让TDengine锦上添花。好看的皮囊千篇一律,希望TDengine能成为最有趣的那一个。
作者:苏晓慰
研发支持:李珲