sharding-jdbc读写分离源码分析
sharding-jdbc读写分离源码分析
由于最近生产上单点数据库有瓶颈,准备使用读写分离来提高应用的性能,在框架调研的过程中发现当当网的开源数据库驱动框架sharding-jdbc,读写分离的功能无需修改应用的代码只需要使用xml或者配置文件配置多个数据源,一时好奇想看看是怎么实现的,起先第一步使用springboot快速搭建一个可查看源码的项目在idea新建一个maven项目并引入shardingjdbc 的jar包 pom.xml文件如下图所示
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>1.4.6.RELEASEversion>
parent>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.21version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>io.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>3.0.0.M1version>
dependency>
<dependency>
<groupId>io.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-namespaceartifactId>
<version>3.0.0.M1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.9version>
dependency> 这里使用阿里巴巴的开源连接池druid做为datasourcetype并在properties文件配置连接属性
sharding.jdbc.datasource.names=ds_master,ds_slave_0,ds_slave_1
sharding.jdbc.datasource.ds_master.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds_master.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds_master.url=jdbc:mysql://192.168.212.67:3306/qu
sharding.jdbc.datasource.ds_master.username=root
sharding.jdbc.datasource.ds_master.password=root
sharding.jdbc.datasource.ds_slave_0.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds_slave_0.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds_slave_0.url=jdbc:mysql://192.168.0.147:3306/qu
sharding.jdbc.datasource.ds_slave_0.username=root
sharding.jdbc.datasource.ds_slave_0.password=root
sharding.jdbc.datasource.ds_slave_1.type=com.alibaba.druid.pool.DruidDataSource
sharding.jdbc.datasource.ds_slave_1.driver-class-name=com.mysql.jdbc.Driver
sharding.jdbc.datasource.ds_slave_1.url=jdbc:mysql://192.168.14.123:3306/qu
sharding.jdbc.datasource.ds_slave_1.username=root
sharding.jdbc.datasource.ds_slave_1.password=-46a580c!
sharding.jdbc.config.masterslave.name=ds_ms
sharding.jdbc.config.masterslave.master-data-source-name=ds_master
sharding.jdbc.config.masterslave.slave-data-source-names=ds_slave_0,ds_slave_1其中123和147为从库67为主库。并写一个最简单的JdbcTemplate进行查询代码如下
package com.shardingtest;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.test.context.web.WebAppConfiguration;
import javax.annotation.Resource;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = App.class)
@WebAppConfiguration
public class TestShareJdbc {
@Resource
private JdbcTemplate jdbcTemplate;
@Test
public void testJdbcTemplate(){
jdbcTemplate.queryForList("select * from qrtz_locks");
}
}这是我们断点来分析一下整个查询流程是怎么实现首先jdbctemplate.queryForList调用的是jdbctemplate的源码如下
public List> queryForList(String sql) throws DataAccessException {
return this.query(sql, this.getColumnMapRowMapper());
}
queryForList调用的是本身的query方法传入sql语句并且新建了一个ColumnMapRowMapper
public List query(String sql, RowMapper rowMapper) throws DataAccessException {
return (List)this.query((String)sql, (ResultSetExtractor)(new RowMapperResultSetExtractor(rowMapper)));
} 这里query方法调用的是query重载方法并把rowMapper包装成RowMapperResultSetExtractor
public T query(final String sql, final ResultSetExtractor rse) throws DataAccessException {
Assert.notNull(sql, "SQL must not be null");
Assert.notNull(rse, "ResultSetExtractor must not be null");
if (this.logger.isDebugEnabled()) {
this.logger.debug("Executing SQL query [" + sql + "]");
}
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
QueryStatementCallback() {
}
public T doInStatement(Statement stmt) throws SQLException {
ResultSet rs = null;
Object var4;
try {
rs = stmt.executeQuery(sql);
ResultSet rsToUse = rs;
if (JdbcTemplate.this.nativeJdbcExtractor != null) {
rsToUse = JdbcTemplate.this.nativeJdbcExtractor.getNativeResultSet(rs);
}
var4 = rse.extractData(rsToUse);
} finally {
JdbcUtils.closeResultSet(rs);
}
return var4;
}
public String getSql() {
return sql;
}
}
return this.execute((StatementCallback)(new QueryStatementCallback()));
} 其实query方法的真正的就是执行execute方法并且传入QueryStatementCallback回调函数。下面我们看下execute方法是怎么实现的
public T execute(StatementCallback action) throws DataAccessException {
Assert.notNull(action, "Callback object must not be null");
//从连接池或者threadlocal里取连接
Connection con = DataSourceUtils.getConnection(this.getDataSource());
Statement stmt = null;
Object var7;
try {
Connection conToUse = con;
if (this.nativeJdbcExtractor != null && this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativeStatements()) {
conToUse = this.nativeJdbcExtractor.getNativeConnection(con);
}
stmt = conToUse.createStatement();
this.applyStatementSettings(stmt);
Statement stmtToUse = stmt;
if (this.nativeJdbcExtractor != null) {
stmtToUse = this.nativeJdbcExtractor.getNativeStatement(stmt);
}
//调用回调函数传入Statement
T result = action.doInStatement(stmtToUse);
this.handleWarnings(stmt);
var7 = result;
} catch (SQLException var11) {
JdbcUtils.closeStatement(stmt);
stmt = null;
DataSourceUtils.releaseConnection(con, this.getDataSource());
con = null;
throw this.getExceptionTranslator().translate("StatementCallback", getSql(action), var11);
} finally {
JdbcUtils.closeStatement(stmt);
//回收连接
DataSourceUtils.releaseConnection(con, this.getDataSource());
}
return var7;
} 这里主要做了几件事。1.threadlocal取connection连接,如果没有就从datesource里面取2.创建statement完以后执行sql语句并调用回调。3.最后关闭连接返回连接池 重点查看Connection 数据库的读写分离应该是在这里包装连接池实现的断点到 Connection con = DataSourceUtils.getConnection(this.getDataSource());这行只是我们查看Connection 对象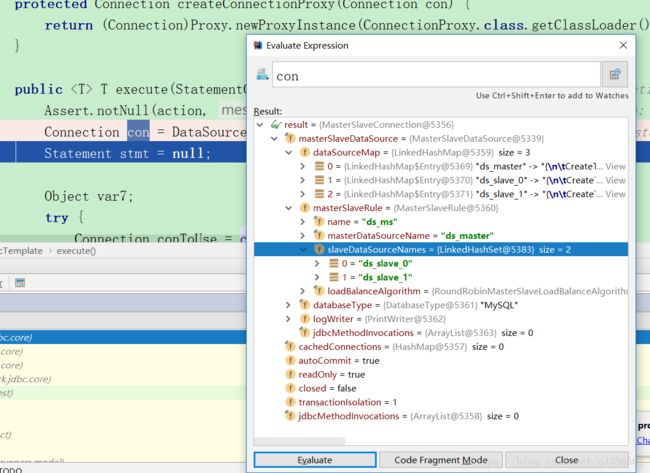
这里的connection的实现是MasterSlaveConnection里面最重要的属性属性包括linkedHashMap的datasourceMap有3个数据源就是我们文中最早配置的3台数据库的连接
masterSlaveRule分片规则其中包括了从库的名字和主库名字在datasourceMap中的key和负载均衡算法的实现RoundRobinMasterSlaveLoadBalanceAlgorithm之后继续调用connection的createstatement方法 stmt = conToUse.createStatement();这时候调用的是MasterSlaveConnection的createStatement方法
public Statement createStatement() {
return new MasterSlaveStatement(this);
}我们来看看MasterSlaveStatement有哪些属性
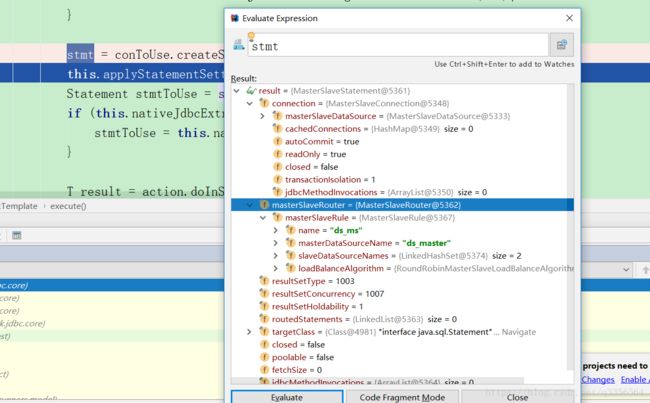
其中最关键的就是MasterSlaveConnection引用和masterSlaveRule的分片信息接下来就是把MasterSlaveStatement传入回调函数执行sql语句回到上步的回调函数执行
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
QueryStatementCallback() {
}
public T doInStatement(Statement stmt) throws SQLException {
ResultSet rs = null;
Object var4;
try {
//关键点是MasterSlaveStatement执行了executeQuery方法
rs = stmt.executeQuery(sql);
ResultSet rsToUse = rs;
if (JdbcTemplate.this.nativeJdbcExtractor != null) {
rsToUse = JdbcTemplate.this.nativeJdbcExtractor.getNativeResultSet(rs);
}
var4 = rse.extractData(rsToUse);
} finally {
JdbcUtils.closeResultSet(rs);
}
return var4;
}
public String getSql() {
return sql;
}
}
return this.execute((StatementCallback)(new QueryStatementCallback()));
}这里我们查看MasterSlaveStatement 的executeQuery方法
public ResultSet executeQuery(String sql) throws SQLException {
//根据语法判断sql语句的类型这边先不做详细分析
SQLStatement sqlStatement = (new SQLJudgeEngine(sql)).judge();
//根据sql语句的类型得到相应的dataSourceNames
Collection dataSourceNames = this.masterSlaveRouter.route(sqlStatement.getType());
Preconditions.checkState(1 == dataSourceNames.size(), "Cannot support executeQuery for DML or DDL");
//根据语句和负载均衡的得到连接名字从datamap中取出
Statement statement = this.connection.getConnection((String)dataSourceNames.iterator().next()).createStatement(this.resultSetType, this.resultSetConcurrency, this.resultSetHoldability);
this.routedStatements.add(statement);
//执行原生statement sql语句
return statement.executeQuery(sql);
} public Collection route(SQLType sqlType) {
if (this.isMasterRoute(sqlType)) {
MasterVisitedManager.setMasterVisited();
return Collections.singletonList(this.masterSlaveRule.getMasterDataSourceName());
} else {
return Collections.singletonList(this.masterSlaveRule.getLoadBalanceAlgorithm().getDataSource(this.masterSlaveRule.getName(), this.masterSlaveRule.getMasterDataSourceName(), new ArrayList(this.masterSlaveRule.getSlaveDataSourceNames())));
}
} 其中route的代码如下判断sql的类型如果是主库路由返回主库连接名字如果是从库连接根据负载均衡算法返回从库连接名,最后根据连接名字从datamap中取出相对应的连接。最后根据连接创建statement执行sql语句
总结
我们可以看到实现读写分离的关键是在与MasterSlaveConnection 和MasterSlaveStatement这2个类MasterSlaveConnection存储的所有连接池的原数据包括读库和写库,MasterSlaveStatement重写了executeQuery方法实现对查询语句的判断和路由的指向。完成读写分离不同语句路由至不同库的操作