hadoop发布一个任务:远程jar包部署(备忘)
ps:需要装好HDFS的环境
此次实验是统计各ip的访问次数。
准备工作:
1.运行hdfs:
[root@CentOS ~]# start-dfs.sh
2.写好任务
任务结构:

MapperDemo类,规定了如何分析数据。
package com.yun;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* LongWritable 代表数据中 每行的字节行偏移量
* Test 每行的文本内容
*/
public class MapperDemo extends Mapper {
/**
*
* @param key :文本偏移量
* @param value :每行文本
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取第一行的第一个数据
String ip = value.toString().split(" ")[0];
context.write(new Text(ip),new IntWritable(1));
}
} ReducerDemo,规定了如何计算数据。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReducerDemo extends Reducer {
/**
*
* @param key :ip
* @param values :Int[]{1,1,1,...}
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
} CustomJobSubmiter,规约提交给hadoop做计算。
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import javax.swing.*;
public class CustomJobSubmiter extends Configured implements Tool {
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmiter(),args);
}
public int run(String[] args) throws Exception {
//1 封装job
Job job = Job.getInstance(getConf());
//附加:jar类加载器
job.setJarByClass(CustomJobSubmiter.class);
//2 设置数据读入与写出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3 设置处理数据的路径
TextInputFormat.addInputPath(job,new Path("/demo/input"));
TextOutputFormat.setOutputPath(job,new Path("/demo/output"));
//4 设置计算数据使用得逻辑
job.setMapperClass(MapperDemo.class);
job.setReducerClass(ReducerDemo.class);
//5 设置Mapper输出泛型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//6 设置Reducer输出泛型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//7 提交任务
job.submit();
return 0;
}
}pom的配置:
4.0.0
com.yun
mapreduce
1.0-SNAPSHOT
org.apache.hadoop
hadoop-hdfs
2.6.0
org.apache.hadoop
hadoop-common
2.6.0
org.apache.hadoop
hadoop-mapreduce-client-core
2.6.0
org.apache.hadoop
hadoop-mapreduce-client-jobclient
2.6.0
org.clojure
clojure
RELEASE
compile
打成jar包:
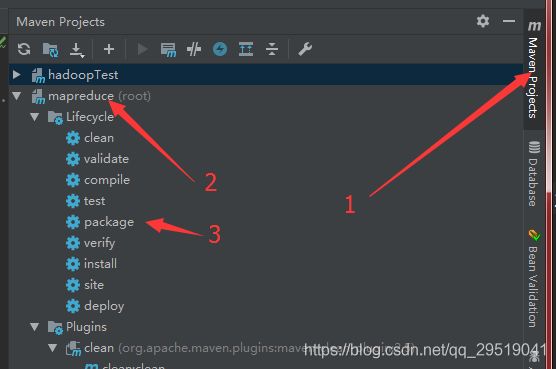
找到maven工程,找到项目,点击package打包
然后会看见target中多了个jar包。

找到这个jar包的路径,把它传送到 linux 中去。
如何把文件传输到linu,有很多办法,这里不赘述。
在linux根目录下,root目录下输入ls查看可找到
![]()
然后需要准备 输入的数据
这里为一个txt的文本
先创建一个文件
[root@CentOS ~]# vi newInput.txt
在文件中输入如下ip
139.212.122.190
61.233.169.47
61.235.118.135
171.10.177.236
210.44.124.58
171.10.177.236
210.38.128.203
182.81.141.169
106.91.10.155
171.15.236.27
36.61.91.146
61.233.175.233
139.205.123.246
171.14.166.146
171.14.166.146
139.212.122.190
139.212.122.190
171.10.60.168
210.44.124.58
36.61.18.65
36.63.76.3
139.212.122.190
106.91.10.155
36.63.76.3
123.234.253.167
61.233.169.47
171.10.177.236
36.63.76.3
36.63.76.3
139.205.123.246
123.234.253.167
171.15.236.27
210.44.124.58
121.76.252.189
171.14.166.146
36.60.90.114
123.234.253.167
把文件放进hdfs中:
我们在 CustomJobSubmiter 类中定义了 数据输入及输出的路径,因此要把文件放入定义的输入路径下。
[root@CentOS ~]# hdfs dfs -put /root/newInput.txt /demo/input
放好后,运行jar程序。hadoop jar命令 + jar包 + 需要运行的类
[root@CentOS ~]# hadoop jar mapreduce-1.0-SNAPSHOT.jar com.yun.CustomJobSubmiter
结果会输出到 /demo/output下,通过hadoop提供的浏览器访问文件系统的方式。

点击下载:

获取运算结果:

看懂的 点个赞吧。