MLlib是Spark提供的一个机器学习库,通过调用MLlib封装好的算法,可以轻松地构建机器学习应用。它提供了非常丰富的机器学习算法,比如分类、回归、聚类及推荐算法。除此之外,MLlib对用于机器学习算法的API进行了标准化,从而使将多种算法组合到单个Pipeline或工作流中变得更加容易。通过本文,你可以了解到:
- 什么是机器学习
- 大数据与机器学习
- 机器学习分类
- Spark MLLib介绍
机器学习是人工智能的一个分支,是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。因为学习算法中涉及了大量的统计学理论,机器学习与推断统计学联系尤为密切,也被称为统计学习理论。算法设计方面,机器学习理论关注可以实现的,行之有效的学习算法。来源:Mitchell, T. (1997). Machine Learning. McGraw Hill.
什么是机器学习

机器学习的应用已遍及人工智能的各个分支,如专家系统、自动推理、自然语言理解、模式识别、计算机视觉、智能机器人等领域。机器学习是人工智能的一个分支学科,主要研究的是让机器从过去的经历中学习经验,对数据的不确定性进行建模,对未来进行预测。机器学习应用的领域很多,比如搜索、推荐系统、垃圾邮件过滤、人脸识别、语音识别等等。
大数据与机器学习
大数据时代,数据产生的速度是非常惊人的。互联网、移动互联网、物联网、GPS等等都会在无时无刻产生着数据。处理这些数据所需要的存储与计算的能力也在成几何级增长,由此诞生了一系列的以Hadoop为代表的大数据技术,这些大数据技术为处理和存储这些数据提供了可靠的保障。
数据、信息、知识是由大到小的三个层次。单纯的数据很难说明一些问题,需要加之人们的一些经验,将其转换为信息,所谓信息,也就是为了消除不确定性,我们常说信息不对称,指的就是在不能够获取足够的信息时,很难消除一些不确定的因素。而知识则是最高阶段,所以数据挖掘也叫知识发现。
机器学习的任务就是利用一些算法,作用于大数据,然后挖掘背后所蕴含的潜在的知识。训练的数据越多,机器学习就越能体现出优势,以前机器学习解决不了的问题,现在通过大数据技术可以得到很好的解决,性能也会大幅度提升,如语音识别、图像识别等等。
机器学习分类
机器学习主要分为下面几大类:
- 监督学习(supervised learning)
基本上是分类的同义词。学习中的
监督来自训练数据集中标记的实例。比如,在邮政编码识别问题中,一组手写邮政编码图像与其对应的机器可读的转换物用作训练实例,监督分类模型的学习。常见的监督学习算法包括:线性回归、逻辑回归、决策树、朴素贝叶斯、支持向量机等等。 - 无监督学习(unsupervised learning)
本质上是聚类的同义词。学习过程是无监督的,因为输入实例没有类标记。无监督学习的任务是从给定的数据集中,挖掘出潜在的结构。比如,把猫和狗的照片给机器,不给这些照片打任何标签,但是希望机器能够将这些照片分分类,最终机器会把这些照片分为两大类,但是并不知道哪些是猫的照片,哪些是狗的照片,对于机器来说,相当于分成了 A、B 两类。常见的无监督学习算法包括:K-means 聚类、主成分分析(PCA)等。
- 半监督学习(Semi-supervised learning)
半监督学习是一类机器学习技术,在学习模型时,它使用标记的和未标记的实例。让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习。
半监督学习的现实需求非常强烈,因为在现实应用中往往能容易地收集到大量未标记样本,而获取
标记却需耗费人力、物力。例如,在进行计算机辅助医学影像分析时,可以从医院获得大量医学影像, 但若希望医学专家把影像中的病灶全都标识出来则是不现实的有标记数据少,未标记数据多这个现象在互联网应用中更明显,例如在进行网页推荐时需请用户标记出感兴趣的网页, 但很少有用户愿花很多时间来提供标记,因此,有标记网页样本少,但互联网上存在无数网页可作为未标记样本来使用。 - 强化学习(reinforcement learning)
又称再励学习、评价学习,是一种重要的机器学习方法,在智能控制机器人及分析预测等领域有许多应用。强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process, MDP)。
Spark MLLib介绍
MLlib是Spark的机器学习库,通过该库可以简化机器学习的工程实践工作。MLlib包含了非常丰富的机器学习算法:分类、回归、聚类、协同过滤、主成分分析等等。目前,MLlib分为两个代码包:spark.mllib与spark.ml。
spark.mllib
Spark MLlib是Spark的重要组成部分,是最初提供的一个机器学习库。该库有一个缺点:如果数据集非常复杂,需要做多次处理,或者是对新数据需要结合多个已经训练好的单个模型进行综合计算时,使用Spark MLlib会使程序结构变得复杂,甚至难以理解和实现。
spark.mllib是基于RDD的原始算法API,目前处于维护状态。该库下包含4类常见的机器学习算法:分类、回归、聚类、协同过滤。指的注意的是,基于RDD的API不会再添加新的功能。
spark.ml
Spark1.2版本引入了ML Pipeline,经过多个版本的发展,Spark ML克服了MLlib处理机器学习问题的一些不足(复杂、流程不清晰),向用户提供了基于DataFrame API的机器学习库,使得构建整个机器学习应用的过程变得简单高效。
Spark ML不是正式名称,用于指代基于DataFrame API的MLlib库 。与RDD相比,DataFrame提供了更加友好的API。DataFrame的许多好处包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
Spark ML API提供了很多数据特征处理函数,如特征选取、特征转换、类别数值化、正则化、降维等。另外基于DataFrame API的ml库支持构建机器学习的Pipeline,把机器学习过程一些任务有序地组织在一起,便于运行和迁移。Spark官方推荐使用spark.ml库。
数据变换
数据变换是数据预处理的一项重要工作,比如对数据进行规范化、离散化、衍生指标等等。Spark ML中提供了非常丰富的数据转换算法,详细可以参考官网,现归纳如下:
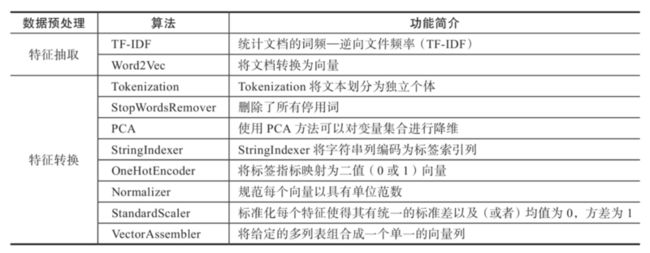
上面的转换算法中,词频逆文档频率(TF-IDF)、Word2Vec、PCA是比较常见的,如果你做过文本挖掘处理,那么对此应该并不陌生。
数据规约
大数据是机器学习的基础,为机器学习提供充足的数据训练集。在数据量非常大的时候,需要通过数据规约技术删除或者减少冗余的维度属性以来达到精简数据集的目的,类似于抽样的思想,虽然缩小了数据容量,但是并没有改变数据的完整性。Spark ML提供的特征选择和降维的方法如下表所示:

选择特征和降维是机器学习中常用的手段,可以使用上述的方法减少特征的选择,消除噪声的同时还能够维持原始的数据结构特征。尤其是主成分分析法(PCA),无论是在统计学领域还是机器学习领域,都起到了很重要的作用。
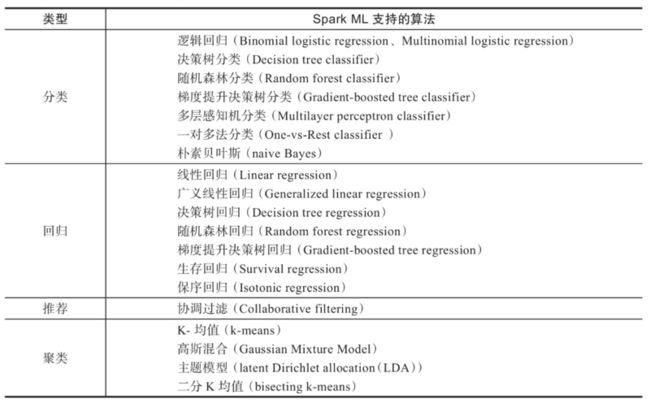
机器学习算法
Spark支持分类、回归、聚类、推荐等常用的机器学习算法。见下表:
总结
本文对机器学习进行了总体介绍,主要包括机器学习的基本概念、机器学习的基本分类、Spark机器学习库的介绍。通过本文或许已经对机器学习有了初步的了解,在下一篇,我将会分享基于Spark ML库构建一个机器学习的应用,主要涉及LDA主题模型以及K-means聚类。
公众号『大数据技术与数仓』,回复『资料』领取大数据资料包