- 零基础 Qt 6 在线安装教程
程序员乐逍遥
Qt框架MFC框架高级编程qt开发语言qt6C++安装
1.首先给你们Qt5.14.2的安装地址,有需要的可以安装Indexof/archive/qt/5.14/5.14.22.首先下载Qt6的在线安装包https://d13lb3tujbc8s0.cloudfront.net/onlineinstallers/qt-online-installer-windows-x64-4.10.0.exe3.安装运行程序
- Docker快速构建Hive测试环境
静谧星光
dockerhive容器编程
Docker是一种流行的容器化平台,可以帮助我们快速构建和管理应用程序的环境。在本文中,我们将学习如何使用Docker快速构建Hive测试环境。Hive是一个基于Hadoop的数据仓库基础设施,它提供了一种类似于SQL的查询语言,用于分析和处理大规模数据集。步骤1:安装Docker和DockerCompose首先,我们需要安装Docker和DockerCompose。您可以根据您的操作系统类型,从
- Docker快速部署Hive服务
长路 ㅤ
运维Docker配置Hive环境大数据远程调试
文章目录前言Docker快速配置hive环境资料获取前言博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。博主所有博客文件目录索引:博客目录索引(持续更新)CSDN搜索:长路视频平台:b站-Coder长路Docker快速配置hive环境Ap
- Android解压工具,ZArchiver,RAR for Android,iZip,The Unarchiver,解压专家
xiaopengbc
软件android
介绍手机解压缩工具种类繁多,以下为你推荐一些功能强大、操作便捷的软件,涵盖安卓和iOS平台:安装点击获取ZArchiver(Android):支持ZIP、RAR、7z、tar、gzip等多种格式的解压与压缩,还能创建7z、zip等格式的压缩包。软件体积小、运行效率高,解压速度快,可对文件进行加密压缩或解压加密文件,保护隐私。其界面简洁直观,支持中文界面,是安卓平台上受欢迎的解压软件之一。RARfo
- Apache SeaTunnel × Hive 深度集成指南:原理、配置与实践
数据库
在大数据处理的复杂生态中,数据的高效流转与整合是实现数据价值的关键。ApacheSeaTunnel作为一款高性能、分布式、易扩展的数据集成框架,能够快速实现海量数据的实时采集、转换和加载;而ApacheHive作为经典的数据仓库工具,为结构化数据的存储、查询和分析提供了坚实的基础。将ApacheSeaTunnel与Hive进行集成,能够充分发挥两者的优势,构建起高效的数据处理链路,满足企业多样化的
- 大数据平台之ranger与ldap集成,同步用户和组
无级程序员
大数据大数据hadoop
ranger可以通过ranger-usersync与linux系统同步用户,但是,还有个问题,就是我们的hiveserver一般是集群,可以是多台服务器,那么我们空间同步哪一台呢,而且如果用户多了,如何管理用户登录密码呢,所以,还是要用ldap比较合理。首先是安装openldap:yum-yinstallopenldapcompat-openldapopenldap-clientsopenldap
- Apache Iceberg数据湖基础
Aurora_NeAr
apache
IntroducingApacheIceberg数据湖的演进与挑战传统数据湖(Hive表格式)的缺陷:分区锁定:查询必须显式指定分区字段(如WHEREdt='2025-07-01')。无原子性:并发写入导致数据覆盖或部分可见。低效元数据:LIST操作扫描全部分区目录(云存储成本高)。Iceberg的革新目标:解耦计算引擎与存储格式(支持Spark/Flink/Trino等);提供ACID事务、模式
- Android导入compile 'com.roughike:bottom-bar:2.3.1'会导致V7包报错
出现问题Error:Executionfailedfortask':app:transformDexArchiveWithExternalLibsDexMergerForDebug'.>java.lang.RuntimeException:java.lang.RuntimeException:com.android.builder.dexing.DexArchiveMergerException:
- z-library 镜像网站
0x0007
linux运维服务器
基于各种你知道的,你不知道的原因,z-library的访问,尤其在国内的访问需要很多手段,没有一劳永逸的方法,只有与时俱进,不忘初心,砥砺前行,永不停歇收集了一些镜像站,随时可能失效,不定期更新:https://annas-archive.org/https://zlib.apphttps://zbook.lol/https://zlibrary.mlhttps://zlib.missuo.me/
- 各种版本Android Studio下载地址
官网各种AndroidStudio版本:https://developer.android.com/studio/archive,如下:当前(2025-07-05)官方提供的版本最旧的只能到2017年的版本了,有时候想安装旧的版本,比如我在学Gradle时,有教程在讲解时使用的AndroidStudio是较旧的版本,所以我想保持开发环境一样,这时就需要下载到旧的版本,但是官网上已经找不到下载链接了
- ubuntu 6.8.0 安装xenomai3.3
ZPC8210
ROSubuntulinux运维
通过以下步骤来获取和准备Linux内核6.8.0的源码,并应用Xenomai补丁:1.下载Linux内核6.8.0源码你可以从TheLinuxKernelArchives下载Linux内核6.8.0的源码。以下是具体步骤:访问内核官方网站:打开TheLinuxKernelArchives。找到对应版本的内核:在网站中找到内核6.8.0的下载链接。通常在v6.x目录下。下载源码:下载linux-6.
- Hadoop核心组件最全介绍
Cachel wood
大数据开发hadoop大数据分布式spark数据库计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
- 数据仓库技术及应用(Hive 产生背景与架构设计,存储模型与数据类型)
娟恋无暇
数据仓库笔记hive
1.Hive产生背景传统Hadoop架构存在的一些问题:MapReduce编程必须掌握Java,门槛较高传统数据库开发、DBA、运维人员学习门槛高HDFS上没有Schema的概念,仅仅是一个纯文本文件Hive的产生:为了让用户从一个现有数据基础架构转移到Hadoop上现有数据基础架构大多基于关系型数据库和SQL查询Facebook诞生了Hive2.Hive是什么官网:https://hive.ap
- Log Miner 挖挖挖
|LogMiner简介LogMiner是Oracle自Oracle8i以后推出的一个可以分析数据库redolog和archivelog内容的工具,可以通过日志分析所有对数据库的DDL和DML操作,也可以分析出操作的时间与操作时的SCN和进行操作的机器,对于DML操作还可以查询出还原操作的sql。|LogMiner组成源数据库产生LogMiner分析的所有重做日志文件的数据库挖掘数据库是执行LogM
- apt-get install E: 无法定位软件包问题
欧阳秦穆
在etc/apt的sources.list添加镜像源debhttp://archive.ubuntu.com/ubuntu/trustymainuniverserestrictedmultiverse然后sudoapt-getupdate接着安装就可以了
- hive中2种常用的join方式
潘达斯奈基~
大数据hivehadoop数据仓库
在最近的项目代码review中,发现之前代码小表关联大表的业务,小表经过过滤后,数据只有400多条,而大表有1600万条,之前的逻辑是使用的是小表join大表,运行时间1小时12分钟;经过优化后,使用了mapjoin的方式,将小表放到内存中,运行时间7分钟。借此机会回顾下hive中2种常用的join方式:MapJoin、ReduceJoin(也叫CommonJoin)应对场景:MapJoin:适用
- linux安装java jdk17 ng
1、下载jdk包wget--header=“Cookie:oraclelicense=accept-securebackup-cookie”https://download.oracle.com/java/17/archive/jdk-17.0.10_linux-x64_bin.tar.gz2、解压jdk包:tar-zxvfjdk-17.0.10_linux-x64_bin.tar.gz3、编辑配
- flink数据同步mysql到hive_基于Canal与Flink实现数据实时增量同步(二)
背景在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(OperationalDataStore)数据。在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据(DB)两类。对于业务DB数据来说,从MySQL等关系型数据库的业务数据进行采集,然后导入到Hive中,是进行数据仓库生产的重要环节。如何准确、高效地把MySQL数据同步到Hive中?一般常用的解决方案是批量
- spark处理kafka的用户行为数据写入hive
月光一族吖
sparkkafkahive
在CentOS上部署Hadoop(Hadoop3.4.1)和Hive(Hive3.1.2)的详细步骤说明。这份指南面向单机安装(伪集群模式),如果需要搭建真正的多节点集群,各节点间的网络互访、SSH免密登录以及配置同步需进一步调整。注意:本指南假设你已拥有root权限或者具有sudo权限,并且系统连接Internet(用于下载安装包)。步骤中的版本号可根据实际需要进行更改。一、环境准备更新系统软件
- .NET Framework 3.5 中的功能简介
benben0701
ASP.NET3.x.netwindowswcflinqasp.netcryptography
.NETFramework3.5中的功能简介(1)我在前文《.NETFramework版本解析》(http://blog.csdn.net/johnsuna/archive/2008/03/23/2208684.aspx)中提到:.NETFramework3.5=.NETFramework3.0+.NETFramework3.0SP1.NETFramework3.0=.NETFramework2.
- ubuntu FreeRadius服务器安装
flowHEHE
ubuntu系统安装ubuntu服务器
1、获取安装源(1)wgethttps://github.com/FreeRADIUS/freeradius-server/archive/v3.0.x.zip(2)unzipv3.0.x.zip(3)cdfreeradius-server-3.0.x/2、创建ubuntu相关依赖(1)sudoapt-getinstalldevscriptsquiltdebhelperfakerootequivs
- Hbase和关系型数据库、HDFS、Hive的区别
别这么骄傲
hivehbase数据库
目录1.Hbase和关系型数据库的区别2.Hbase和HDFS的区别3.Hbase和Hive的区别1.Hbase和关系型数据库的区别关系型数据库Hbase存储适合结构化数据,单机存储适合结构化和半结构数据的松散数据,分布式存储功能(1)支持ACID(2)支持join(3)使用主键PK(4)数据类型:int、varchar等(1)仅支持单行事务(2)不支持join,把数据糅合到一张大表(3)行键ro
- 大数据基础知识-Hadoop、HBase、Hive一篇搞定
原来是猪猪呀
hadoop大数据分布式
HadoopHadoop是一个由Apache基金会所开发的分布式系统基础架构,其核心设计包括分布式文件系统(HDFS)和MapReduce编程模型;Hadoop是一个开源的分布式计算框架,旨在帮助用户在不了解分布式底层细节的情况下,开发分布式程序。它通过利用集群的力量,提供高速运算和存储能力,特别适合处理超大数据集的应用程序。Hadoop生态圈Hadoop生态圈是一个由多个基于Hadoop开发的相
- Hadoop、HDFS、Hive、Hbase区别及联系
静心观复
大数据hadoophdfshive
Hadoop、HDFS、Hive和HBase是大数据生态系统中的关键组件,它们都是由Apache软件基金会管理的开源项目。下面将深入解析它们之间的区别和联系。HadoopHadoop是一个开源的分布式计算框架,它允许用户在普通硬件上构建可靠、可伸缩的分布式系统。Hadoop通常指的是整个生态系统,包括HadoopCommon(共享库和工具)、HadoopDistributedFileSystem(
- Python 进攻性渗透测试(一)
原文:annas-archive.org/md5/dccde1d96c9ad81f97529d78e3e69c9b译者:飞龙协议:CCBY-NC-SA4.0序言Python是一种易学的跨平台编程语言,具有无限的第三方库。许多开源黑客工具都是用Python编写的,可以轻松地集成到你的脚本中。本书被分成了清晰的小部分,你可以按照自己的节奏学习,并专注于对你最有兴趣的领域。你将学会如何编写自己的脚本,并
- Python 进攻性渗透测试(二)
原文:annas-archive.org/md5/dccde1d96c9ad81f97529d78e3e69c9b译者:飞龙协议:CCBY-NC-SA4.0第四章:追捕我吧!在今天的世界里,绕过和劫持软件在互联网上到处都是。然而,明确的使用和执行方式才是让你成为一名优秀的业余黑客的关键。这可以通过正确选择工具并遵循必要的过程,完美地完成手头的任务来实现。在本章中,我们将涵盖以下主题,帮助你实现这一
- 大数据面试题之Hive(1)
小的~~
大数据大数据hivehadoop
说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?说下Hive是什么?跟数据仓库区别?Hive架构Hive内部表和外部表的区别?为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?Hive建表语句?创建表时使用什么分隔符?Hive删除语句外部表删除的是什么?Hive数据倾斜以及解决方案Hive如果不用参数调优,在map和reduce端应该做什么Hive
- centos使用wget下载jdk8
任意放逐
centosjavalinux
首先官网找需要的的jdk版本https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html我这里选择的是弹出下载提示框:勾选点Downloadjdk…这里需要使用一个账号登录,可以自行在网上搜一个账号,我就不给了。然后退回原来的页面下载,用一个能看到下载链接的软件下载,我使用的是idm
- Qt Creator 11.0创建ROS2 Humble工程
余加木
ROS2Qtqt开发语言
QtCreator11.0创建ROS2Humble项目工程安装ROSProjectManager插件创建ROS2项目在src下添加packagegitcloneROS2功能包编译运行安装ROSProjectManager插件安装ROSProjectManager的主要流程参考官方的流程,地址(ros_qtc_plugin)。此处采用二进制安装:sudoaptinstalllibarchive-to
- ORACLE 正确删除归档日志的方法
俗尘某某
程序员记录oracle归档日志
ORACLE正确删除归档日志的方法我们都知道在controlfile中记录着每一个archivelog文件的相关信息,当然们在OS下把这些物理文件delete掉后,在我们的controlfile中仍然记录着这些archivelog文件的相关信息,在oracle的OEM管理器中有可视化的日志展现出,当我们手工清除archive目录下的文件后,这些记录并没有被我们从controlfile中清除掉,也就
- Algorithm
香水浓
javaAlgorithm
冒泡排序
public static void sort(Integer[] param) {
for (int i = param.length - 1; i > 0; i--) {
for (int j = 0; j < i; j++) {
int current = param[j];
int next = param[j + 1];
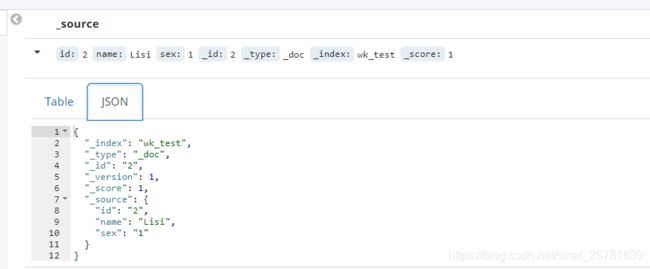
- mongoDB 复杂查询表达式
开窍的石头
mongodb
1:count
Pg: db.user.find().count();
统计多少条数据
2:不等于$ne
Pg: db.user.find({_id:{$ne:3}},{name:1,sex:1,_id:0});
查询id不等于3的数据。
3:大于$gt $gte(大于等于)
&n
- Jboss Java heap space异常解决方法, jboss OutOfMemoryError : PermGen space
0624chenhong
jvmjboss
转自
http://blog.csdn.net/zou274/article/details/5552630
解决办法:
window->preferences->java->installed jres->edit jre
把default vm arguments 的参数设为-Xms64m -Xmx512m
----------------
- 文件上传 下载 解析 相对路径
不懂事的小屁孩
文件上传
有点坑吧,弄这么一个简单的东西弄了一天多,身边还有大神指导着,网上各种百度着。
下面总结一下遇到的问题:
文件上传,在页面上传的时候,不要想着去操作绝对路径,浏览器会对客户端的信息进行保护,避免用户信息收到攻击。
在上传图片,或者文件时,使用form表单来操作。
前台通过form表单传输一个流到后台,而不是ajax传递参数到后台,代码如下:
<form action=&
- 怎么实现qq空间批量点赞
换个号韩国红果果
qq
纯粹为了好玩!!
逻辑很简单
1 打开浏览器console;输入以下代码。
先上添加赞的代码
var tools={};
//添加所有赞
function init(){
document.body.scrollTop=10000;
setTimeout(function(){document.body.scrollTop=0;},2000);//加
- 判断是否为中文
灵静志远
中文
方法一:
public class Zhidao {
public static void main(String args[]) {
String s = "sdf灭礌 kjl d{';\fdsjlk是";
int n=0;
for(int i=0; i<s.length(); i++) {
n = (int)s.charAt(i);
if((
- 一个电话面试后总结
a-john
面试
今天,接了一个电话面试,对于还是初学者的我来说,紧张了半天。
面试的问题分了层次,对于一类问题,由简到难。自己觉得回答不好的地方作了一下总结:
在谈到集合类的时候,举几个常用的集合类,想都没想,直接说了list,map。
然后对list和map分别举几个类型:
list方面:ArrayList,LinkedList。在谈到他们的区别时,愣住了
- MSSQL中Escape转义的使用
aijuans
MSSQL
IF OBJECT_ID('tempdb..#ABC') is not null
drop table tempdb..#ABC
create table #ABC
(
PATHNAME NVARCHAR(50)
)
insert into #ABC
SELECT N'/ABCDEFGHI'
UNION ALL SELECT N'/ABCDGAFGASASSDFA'
UNION ALL
- 一个简单的存储过程
asialee
mysql存储过程构造数据批量插入
今天要批量的生成一批测试数据,其中中间有部分数据是变化的,本来想写个程序来生成的,后来想到存储过程就可以搞定,所以随手写了一个,记录在此:
DELIMITER $$
DROP PROCEDURE IF EXISTS inse
- annot convert from HomeFragment_1 to Fragment
百合不是茶
android导包错误
创建了几个类继承Fragment, 需要将创建的类存储在ArrayList<Fragment>中; 出现不能将new 出来的对象放到队列中,原因很简单;
创建类时引入包是:import android.app.Fragment;
创建队列和对象时使用的包是:import android.support.v4.ap
- Weblogic10两种修改端口的方法
bijian1013
weblogic端口号配置管理config.xml
一.进入控制台进行修改 1.进入控制台: http://127.0.0.1:7001/console 2.展开左边树菜单 域结构->环境->服务器-->点击AdminServer(管理) &
- mysql 操作指令
征客丶
mysql
一、连接mysql
进入 mysql 的安装目录;
$ bin/mysql -p [host IP 如果是登录本地的mysql 可以不写 -p 直接 -u] -u [userName] -p
输入密码,回车,接连;
二、权限操作[如果你很了解mysql数据库后,你可以直接去修改系统表,然后用 mysql> flush privileges; 指令让权限生效]
1、赋权
mys
- 【Hive一】Hive入门
bit1129
hive
Hive安装与配置
Hive的运行需要依赖于Hadoop,因此需要首先安装Hadoop2.5.2,并且Hive的启动前需要首先启动Hadoop。
Hive安装和配置的步骤
1. 从如下地址下载Hive0.14.0
http://mirror.bit.edu.cn/apache/hive/
2.解压hive,在系统变
- ajax 三种提交请求的方法
BlueSkator
Ajaxjqery
1、ajax 提交请求
$.ajax({
type:"post",
url : "${ctx}/front/Hotel/getAllHotelByAjax.do",
dataType : "json",
success : function(result) {
try {
for(v
- mongodb开发环境下的搭建入门
braveCS
运维
linux下安装mongodb
1)官网下载mongodb-linux-x86_64-rhel62-3.0.4.gz
2)linux 解压
gzip -d mongodb-linux-x86_64-rhel62-3.0.4.gz;
mv mongodb-linux-x86_64-rhel62-3.0.4 mongodb-linux-x86_64-rhel62-
- 编程之美-最短摘要的生成
bylijinnan
java数据结构算法编程之美
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
public class ShortestAbstract {
/**
* 编程之美 最短摘要的生成
* 扫描过程始终保持一个[pBegin,pEnd]的range,初始化确保[pBegin,pEnd]的ran
- json数据解析及typeof
chengxuyuancsdn
jstypeofjson解析
// json格式
var people='{"authors": [{"firstName": "AAA","lastName": "BBB"},'
+' {"firstName": "CCC&
- 流程系统设计的层次和目标
comsci
设计模式数据结构sql框架脚本
流程系统设计的层次和目标
- RMAN List和report 命令
daizj
oraclelistreportrman
LIST 命令
使用RMAN LIST 命令显示有关资料档案库中记录的备份集、代理副本和映像副本的
信息。使用此命令可列出:
• RMAN 资料档案库中状态不是AVAILABLE 的备份和副本
• 可用的且可以用于还原操作的数据文件备份和副本
• 备份集和副本,其中包含指定数据文件列表或指定表空间的备份
• 包含指定名称或范围的所有归档日志备份的备份集和副本
• 由标记、完成时间、可
- 二叉树:红黑树
dieslrae
二叉树
红黑树是一种自平衡的二叉树,它的查找,插入,删除操作时间复杂度皆为O(logN),不会出现普通二叉搜索树在最差情况时时间复杂度会变为O(N)的问题.
红黑树必须遵循红黑规则,规则如下
1、每个节点不是红就是黑。 2、根总是黑的 &
- C语言homework3,7个小题目的代码
dcj3sjt126com
c
1、打印100以内的所有奇数。
# include <stdio.h>
int main(void)
{
int i;
for (i=1; i<=100; i++)
{
if (i%2 != 0)
printf("%d ", i);
}
return 0;
}
2、从键盘上输入10个整数,
- 自定义按钮, 图片在上, 文字在下, 居中显示
dcj3sjt126com
自定义
#import <UIKit/UIKit.h>
@interface MyButton : UIButton
-(void)setFrame:(CGRect)frame ImageName:(NSString*)imageName Target:(id)target Action:(SEL)action Title:(NSString*)title Font:(CGFloa
- MySQL查询语句练习题,测试足够用了
flyvszhb
sqlmysql
http://blog.sina.com.cn/s/blog_767d65530101861c.html
1.创建student和score表
CREATE TABLE student (
id INT(10) NOT NULL UNIQUE PRIMARY KEY ,
name VARCHAR
- 转:MyBatis Generator 详解
happyqing
mybatis
MyBatis Generator 详解
http://blog.csdn.net/isea533/article/details/42102297
MyBatis Generator详解
http://git.oschina.net/free/Mybatis_Utils/blob/master/MybatisGeneator/MybatisGeneator.
- 让程序员少走弯路的14个忠告
jingjing0907
工作计划学习
无论是谁,在刚进入某个领域之时,有再大的雄心壮志也敌不过眼前的迷茫:不知道应该怎么做,不知道应该做什么。下面是一名软件开发人员所学到的经验,希望能对大家有所帮助
1.不要害怕在工作中学习。
只要有电脑,就可以通过电子阅读器阅读报纸和大多数书籍。如果你只是做好自己的本职工作以及分配的任务,那是学不到很多东西的。如果你盲目地要求更多的工作,也是不可能提升自己的。放
- nginx和NetScaler区别
流浪鱼
nginx
NetScaler是一个完整的包含操作系统和应用交付功能的产品,Nginx并不包含操作系统,在处理连接方面,需要依赖于操作系统,所以在并发连接数方面和防DoS攻击方面,Nginx不具备优势。
2.易用性方面差别也比较大。Nginx对管理员的水平要求比较高,参数比较多,不确定性给运营带来隐患。在NetScaler常见的配置如健康检查,HA等,在Nginx上的配置的实现相对复杂。
3.策略灵活度方
- 第11章 动画效果(下)
onestopweb
动画
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- FAQ - SAP BW BO roadmap
blueoxygen
BOBW
http://www.sdn.sap.com/irj/boc/business-objects-for-sap-faq
Besides, I care that how to integrate tightly.
By the way, for BW consultants, please just focus on Query Designer which i
- 关于java堆内存溢出的几种情况
tomcat_oracle
javajvmjdkthread
【情况一】:
java.lang.OutOfMemoryError: Java heap space:这种是java堆内存不够,一个原因是真不够,另一个原因是程序中有死循环; 如果是java堆内存不够的话,可以通过调整JVM下面的配置来解决: <jvm-arg>-Xms3062m</jvm-arg> <jvm-arg>-Xmx
- Manifest.permission_group权限组
阿尔萨斯
Permission
结构
继承关系
public static final class Manifest.permission_group extends Object
java.lang.Object
android. Manifest.permission_group 常量
ACCOUNTS 直接通过统计管理器访问管理的统计
COST_MONEY可以用来让用户花钱但不需要通过与他们直接牵涉的权限
D