
导读:作者从 17 年双十一前开始接手天猫搜索前端,开发第一个需求—— H5 凑单页,到今天已经将近两年了。在这两年里,天猫搜索的前端体系发生了比较大的变化。今天分享一篇阶段性的总结文章,记录天猫搜索前端技术的过去、现在,以及自己作为业务目前的唯一前端对未来的思考。
大体划分
首先基于前端技术的演进,大体上可以将天猫搜索前端的发展历程和未来趋势总结成几个时代:
- PC 时代
- H5 时代
- MV* 时代
- Weex 时代
- 搭建时代
- 深度搭建时代
- 智能时代
之所以这么划分,主要是基于天猫搜索的前端技术方向以及天猫乃至淘系前端技术体系发生的较大变化。而在这其中可以再提炼时代的关键词:
- 封闭:PC 时代、H5 时代、MV* 时代
- 开放:Weex 时代、搭建时代、深度搭建时代
- 智能:智能时代
下面就来介绍各个时代天猫前端的技术状态和一些思考。
1、PC时代
PC 时代可以说是天猫搜索前端的上古时代,那还是手机流量非常贵的 3g/2g 时代。因此大多还是简单的 WAP 页面,大多数人都还是习惯用 PC 进行购物。
▐ 技术方案
模块化
PC 时代的前端技术方案采用的是 KISSY + MUI 3 ,MUI 3 就是那套 KISSY 的模块规范 KMD 。页面上还有一些非常老旧的 YUI 依赖。在那个 jQuery 王霸天下的时代,基本上天猫的 PC 页面都是采用集团内部根据 YUI 自研的大而全的 KISSY 框架。KISSY框架包含了前端所需要的几乎所有基础功能:模块加载器、 DOM 操作、事件处理、异步请求等等。
页面渲染
PC 天猫搜索采用了同步渲染的方式,页面的主要内容通过 VM 模板渲染输出到前端,因此前端需要维护大量的 Velocity 模板代码以保证 HTML 中的内容和自己 JS 代码能够配合得当。需求修改一旦涉及到 HTML ,就需要改造 Velocity 模板从而陷入 aone 发布的同步模板和部署炼狱之中。
模块管理
而 PC 时代的天猫搜索前端页面的模块管理方式十分粗暴,基于业务逻辑划分的大量 KISSY 模块,他们共同操作一个统一的页面 DOM ,交叉修改时有发生。模块间的通信也是直接调用模块实例方法来实现,模块耦合非常严重。
▐ 小结
由此可以看到那个时代最主要的问题有如下几个:
- 大而全的框架使得页面笨重、依赖繁杂
- 前端花费大量成本去维护不熟悉的 Velocity 代码
- 基于应用环境,经常性需要同步模板或部署,应用不稳定时甚至无法调试
- 页面内模块化粗暴,模块耦合严重
- 重 DOM 操作,DOM 管理混乱
2、H5 时代
随着智能手机的普及,4g 技术的发展使得流量费用的大幅下降,无线端需求不断增多,流量不断增大,天猫前端也将方向定为 mobile first 。显然 PC 搜索这一套技术方案无法满足 H5 搜索需求,因此 H5 搜索采用了全新的技术方案。
▐ 技术方案
模块化
H5 搜索采用 Zepto + MUI 4 作为模块化方案,MUI 4 相对 MUI 3 主要变化是将 KMD 规范修改成了业内较为通用的 AMD 规范。同时引入了前端模板来实现 DOM 的更新,首先 Zepto 要比大而全的 KISSY 轻量许多,同时前端模板的引入使得模块自我管理了 DOM ,有效的降低了模块之间 DOM 操作交叉引发的混乱。
页面渲染
H5 搜索的页面渲染基于应用控制,但仅仅将框架、筛选等一些少量 DOM 同步渲染,大多数 DOM 如商品列表都是采用异步渲染前端模板的方式实现。因此同步模板中的内容量相对较小,维护成本大幅度降低。同时引入了前后端分离的 wormhole app ,前端不再需要维护不熟悉的 VM 模板,而是维护和异步模板语法相同的 xtpl 模板,进一步降低了模板维护的成本。
模块管理
与 PC 连翻页都是页面跳转的方式不同,如筛选、翻页等行为的渲染需要前端异步处理,模块通信的需求也相对复杂。H5 搜索采用了 MDV 框架——通过将模块封装成一个个模型,再由 MDV 建立的模型之间的订阅机制进行模块的实例管理,以此来实现模块通信。
▐ 小结
H5 搜索采用的技术解决了几个 PC 搜索时代的问题:
- 减小依赖,满足了H5的性能要求
- 基于wormhole app的前后端分离开发,降低了模板维护成本
- 引入前端模板,降低了DOM交叉管理的混乱
- 引入MDV进一步使得模块解耦,规范了模块通信
但随着业务的发展,依然发现有一些问题:
- 虽然引入了前端模板,但所有更新和状态同步依然是手动的,依旧会频繁地 DOM 操作
- 模块划分还是基于逻辑划分,而非基于 DOM ,因此当一个逻辑模块需要操作多个 DOM 时,依然会引发交叉
- 虽然模块对外是个黑盒,但模块内部状态经常因为交互逻辑和业务逻辑繁琐导致混乱,经常出现更新了状态没更新 DOM 的情况
- 依赖应用环境,需要经常性同步模板和部署,毕竟 wormhole app 也是应用
3、MV*时代
在 all in 无线的大环境下,由于搜索结构较为固定、无线端开发资源较为充裕等等各种原因,天猫搜索业务在端内完全被 Native 承接,而 H5 更加注重端外和站外。这也导致了 H5 搜索的业务能力和 Native 脱节,仅保留核心筛选功能以及唤端功能。因此 H5 搜索很长一段时间几乎没有前端资源投入,而在 2017 年 8 月左右由于组织架构调整,我手上的天猫商品业务交接后,我开始逐步接手天猫搜索前端业务。而我要做的第一个需求,就是一个包含 H5 搜索 80% 功能的 H5 搜索凑单页。
▐ 技术方案
模块化
我和团队同学采用 Preact + MUI 5 方案来实现,MUI 5 其实就是 MUI 4 的升级,采用 CommonJS 的写法来编写模块,再经过构建工具编译封装生成 AMD 模块。其实当时会场已经大规模采用 Vue Weex 了,那我们为什么要采用 Preact 呢,主要是基于如下几点考量:
- 团队内对于 React 技术栈有相当程度的了解
- Rax 的发展和普及以及 Weex 团队的一些调整,让我们认为 Rax 是未来 Weex 的主要 DSL
- Preact 相对于其他框架更加轻量,而搜索的页面虽然有一定交互,但比较简单,刚好能满足需求
- H5 是未来大的趋势,当时兄弟团队在天猫超市的极致 H5 体验和沉淀给了我们充足的信心
因此在这个阶段,我们使用 Preact 做了很多的搜索周边的功能页面,如上面提到的 H5 凑单、还有猫搜的领券弹层、凑单领券页面、搜索分类页面等等。
页面渲染
由于 Preact 的异步渲染特性,页面渲染我们直接抛弃了应用,而是采用斑马源码页面的方式。这样的好处是,前端不再需要和 aone 频繁的打交道,服务端只需要封装一个 mtop 接口给前端,前端在斑马上创建基础 HTML 引入资源并调用接口获取数据渲染即可,前端自己完全掌控了调试、开发节奏。由于对于应用的依赖仅限于一个 mtop 接口,因此前端可以提前定好数据规范,在服务端开发接口的同时基于本地调试工具进行 mock ,大大降低了联调成本。
模块管理
React 生态有非常多的模块管理方案,我们调研过的 Flux、Redux、Reflux 等等都可以满足我们的需求。但经过仔细的思考我们选择直接撸,不使用任何框架来管理模块通信。如此考量的原因主要遵循如下理念:
- 首先我们需要规划页面的模块结构和通信结构
- 若通信结构与模块结构有较大的出入,且通信结构并非扁平,那么我们就需要引入模块通信框架来实现通信结构的扁平化
- 若通信结构与模块结构出入不大,且通信结构本身扁平,那么我们就没有必要引入通信框架
- 保持模块结构清晰、分离,面向未来,若未来业务发展逐渐繁琐,可以再引入框架来处理模块通信
▐ 小结
引入 MV* 框架后,我们的技术方案又得到了一些提升:
- 由于引入 MV* 框架,模块的划分不再基于逻辑而是基于 DOM,DOM 的操作不再需要手动处理, DOM 交叉操作被彻底杜绝;
- 使用斑马源码页面,不再依赖应用环境,更方便的数据模拟和调试。不再需要维护模板;
- 模块内部状态基于 MV* 管理,状态不再混乱,保证了 DOM 和模块状态的一致性;
这里还是有一些问题:
- H5 总是面对性能的挑战
- 依然是源码开发,不够灵活,也无法共建
- 每来一个需求,就需要页面整体修改和发布,有类似行业定制,只能重新开发一个
借鉴天猫超市极致 H5 经验,搜索在分类页做了非常多性能优化尝试,比如:
1、代码优化
- 列表拆分 cell 进行懒加载
- 接入 crossimage 优化图片加载的 cdn 后缀
- 自建 solution ,去除通用 solution 中各种无用依赖
- 升级最新的 loader 来提升计算性能
2、DNS优化
- dns-prefetch,提前处理dns
- 收敛图片和资源域名
3、接口优化
- 使用dlp进行mtop接口缓存
4、埋点优化
- 令箭埋点延迟到 pageload 后发布
- 采用非覆盖式的 aplus 脚本,利用浏览器缓存
- 采用 post 发送,触发 sendBeacon
5、加载优化
- 增加 service worker 层缓存 js、css 和图片
- 使用 zcache 缓存页面模板、 js 和 css
6、体感优化
- 使用 ranger 自动添加 URL 隐藏导航栏参数,防止页面加载后手动隐藏出现的抖动
4、Weex 时代
17 年双十一之后,搜索一成不变的模式也受到挑战,在这个拥有大量流量和强用户心智的场景下,搜索能够玩出更多场景化、行业化、品牌化的玩法。因此产品上需要更多快速试错的机会,也导致对于动态化的诉求则日益增加。而由于一些组织架构调整,天猫搜索的客户端缩减到 2 人—— 1 个 ios 和 1 个安卓。客户端需求开发因为需要发版而迭代缓慢。因此催生了 Native 内嵌 Weex 坑位的技术方案和 Weex 模板下发的 Oreo 平台。
▐ 技术方案
模块化
其实在我进入到搜索之前,Weex 坑位方案和 Oreo 就已经在小范围使用了,有一部分客户端同学写的 Weex 1.0 的 Vue 模块,另外还有一些 Weapp 模块。这些模块由于人员调整和离职已经很难找到仓库源码了。另外这些模块也是仅面向 Weex 的,对于 H5 来说是完全无法使用的。因此在我进入搜索之后,提出了Prax的解决方案,本质上就是使用 Rax 0.x(当时还是0.4) + Preact 通过编译转换供Weex和 Web 同时使用。之所以要用Preact,主要是考虑到我们有端外 H5 场景,但是 Rax 当时 H5 性能是真的堪忧,而且当时的Weex团队方向对H5性能优化投入并不多。另外从上面 MV* 时代可以看出我们在 Preact + MUI5 的技术方案上也有较多的沉淀。最终我们确定了采用编写 Preact 代码,通过自动化工具转换成 Rax 代码的方式来实现一份源码同时复用在 Weex 和 Web 的技术方案。前端的开发流程就变成了如下:
- 编写包含基础可复用纯 UI 代码的 Prax 模块
- 对于 Native 内嵌 Weex 坑位,编写一个 Rax 模块, Rax 模块引用 Prax 模块的 Rax 部分,并增加诸如埋点、容器联动等功能,并通过专门的模板发布系统发布上线以供坑位使用
- 对于 Prax 页面,编写一个斑马模块或页面,引用 Prax 模块。通过斑马平台发布上线,在端内使用 Prax 页面的 Weex 版本,在端外引用 Prax 页面的 H5 版本
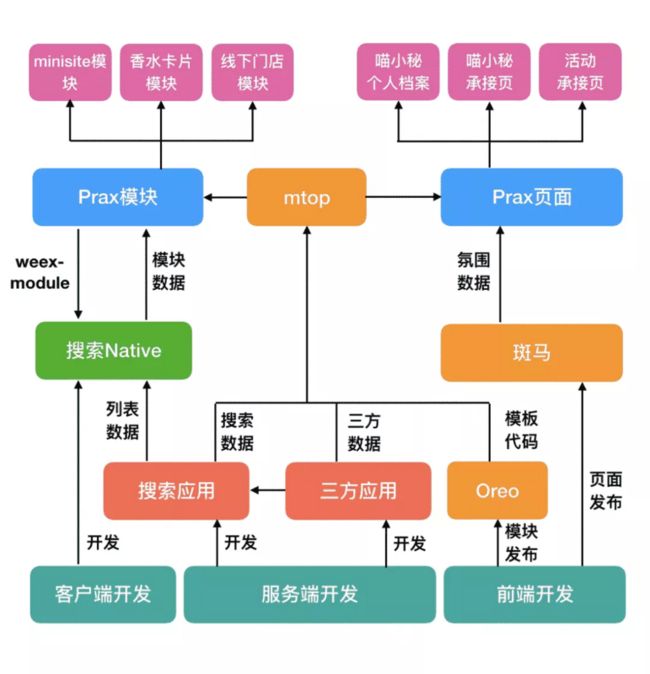
页面渲染
Prax 页面采用斑马来处理页面渲染。由于源码页面都是采用打包的方式,因此脚手架中分别有 Web 和 Rax 两个打包 webpack 配置,构建时候分别运行生成 Weex Bundle 和 Web Bundle 。由于 Web 端本质上就是之前 Preact 的方式,因此渲染沿用了过去 Preact 的页面框架。而Rax则是开发了一个全新的页面框架。斑马渲染 Weex 页面本质上是通过xtpl控制 Weex Bundle 代码生成,所以源码页面编译出来的 Weex bundle 只需要在外通过 xtpl 增加一层 Weex 的头尾就可以了。
对于 Native 内嵌坑位,则是采用模板下发的方式。前端会编译生成一个自身可运行的 Weex Bundle ,包含头尾等完整信息,然后通过发布推送到搜索应用的机器上。当客户端的搜索请求到达服务端,服务端基于业务逻辑确定需要使用哪些模块,将模块相关的信息告诉客户端,这些信息包括模块名称、模块位置、模块数据。客户端渲染 Native 页面时根据模块位置创建对应容器,并根据模板名称请求 Weex 代码,最后将代码渲染到 Weex 容器中,并传入模块数据,实现模块最终渲染。而在 Rax 代码中,我们可以通过 window.__weex_data__ 拿到客户端塞给容器的数据。当然这些适配都可以在构建层面处理,一般情况下开发者只需要关注纯粹的 UI 模块编写即可。
模块管理
Prax 页面的模块管理和 Preact 开发时期基本一样。但是对于 Native 内嵌 Weex 坑位,模块管理方案就完全不同了。看起来 Native 内嵌 Weex 坑位只展示一个Weex模块,但实际上是一个只有单一模块渲染的完整 Weex 页面。因此 Weex 模块之间是无法通信的,它们甚至都不在一个 Weex 容器内。正因为如此 Native 内嵌 Weex 大多做一些纯展示的需求,对于复杂联动需求依然是交给客户端完成。另外客户端提供了一些通用能力,封装在 Weex 模块中,如:
- 获取搜索当前筛选条件
- 合并筛选条件并重新请求
- 清空筛选条件并重新请求
- Query 词替换
- 一次筛选内 mtop 缓存机制
- ...
▐ 小结
经过了 Weex 时代,我们的技术又得到了提升:
- 实现了一套代码同时复用在 Weex 和 H5
- 通过引入 Rax ,我们解决了端内的性能问题
- 对于端外场景,我们也保证了 H5 性能以及优化的抓手
- 灵活的 Weex 发布机制突破了发版限制,满足了产品的动态化诉求
- 对于搜索坑位,我们也沉淀出了一套行业前端可以参与共建的机制
但这里还是有几个问题没有解决:
- 源码页面开发的问题依旧,不够灵活,也无法共建,也不好复制多个
- 搜索坑位内模块展现逻辑是服务端硬代码控制,对于行业规模化和动态数据源接入都需要重新编码
- 当多个模块同时作用于同一场景时,模块的展示逻辑就会交叉,引入各种各样的问题
5、搭建时代
至此我们可以发现,现在搜索前端核心解决的问题逐渐变成了共建和规模化了,不再是之前单纯前端技术问题了。既然要解决共建和规模化,我们可以看看规模化成功的一个典型例子:会场。过去会场也是一个个页面前端人肉开发,到后来有了斑马就可以由运营模块化搭建了,前端只需要开发一些基础模块就可以满足所有行业的诉求,多么的美好!那么搜索是不是也能搭建呢?
答案是:“是的”,但毕竟场景不同,我们不能和会场一样楼层 duangduang 地堆砌,为什么呢?
首先在场景的层面有比较大的不同。在用户进入这个会场时,已经决定了当前的场景了,一个会场页面就是一个场景,因此在这个会场页面下,只需要圈出这个场景的模块就可以了。而对于搜索,所有的场景都需要在搜索这一个页面展示,而在搜索如何定义一个场景呢?
- Query 词:用户搜了什么词,是品类词、还是品牌词、还是宽泛词、还是一个具体的型号词
- 类目:用户搜的词所属的类目是什么?哪个一级类目?哪个叶子类目?或者说是横跨很多类目?
- 人群:用户自己是哪个人群,潮流酷女?还是居家好男人?
- 时间:用户在什么时间来的?圣诞节?新年?生日?
- LBS:用户在什么地方来的?附近是不是有提供服务的门店?
- ...
这么多维度,一个或多个交织在一起才定义了一个场景,而在这个场景下会展示一个或多个模块。
以 Query 举例:
- 用户搜索品牌词(如华为):展示品牌搭建的 Minisite
- 用户搜索特定类目词(如香水):展示行业模块
- 用户搜索礼物(宽泛词):展示礼物场景导购卡片
- ....
当然,会场模块里面的货品完全可以多样化,另外现在会场基于袋鼠也有千人千面模块的能力了,这里是拿之前的会场做例子
基于这样的思考,搜索启动了一个长颈鹿项目,以之前搜索域就有的一个产品——品牌 Minisite 作为切入点,为品牌商提供了一个全新的品牌运营阵地
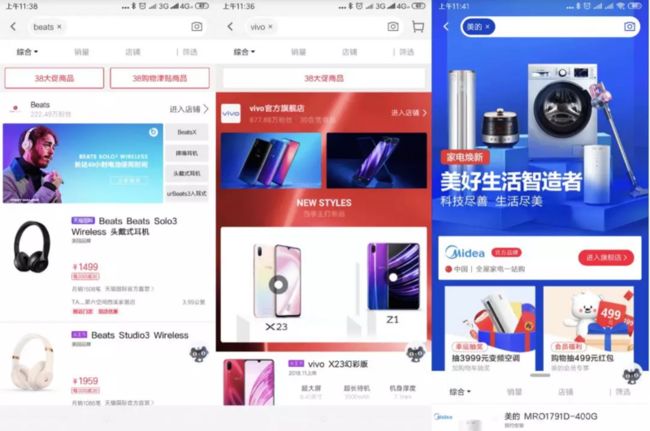
如上图,从左往右分别是三个版本的 minisite 。这里可以看到, Minisite 作为品牌在搜索的一个搭建阵地,一直采用的是提供模块让品牌商填入数据的玩法。品牌商自定义程度很低、维护欲望很低,因此导购效率一直不高。而在长颈鹿项目中,搜索在商品列表层之下又新开了一个层,在这个层里展示一个品牌商家搭建的页面,在这个页面中品牌商家可以充分的自定义。而对于一个跨品类经营的大品牌,我们也开放了品牌词+主营类目词的组合,方便其对每个主营类目去搭建自己的页面。
而在品牌词下取得成功后,我们将能力扩展到了行业侧,在搜索中台——美高上建设了心智造产品。让行业也可以基于同样的方式去经营品类词,搭建行业自己的页面。
心智造和 Minisite 分别是针对品类词和品牌词,相互不会交叉。而对于一些横跨多品类的平台级需求,比如一些频道相关的需求和拉新相关的需求,是非常容易与其他场景交叉的。为了解决这个问题,我们在美高上沉淀了一套模块定投方案——无界,通过模块级别的投放,让场景之间的交叉变成可能,只需要简单定义模块展示的规则,就能让不同场景的模块展示在同一个页面上。
▐ 技术方案
模块化
首先是心智造和 Minisite ,它们的核心技术方案是相似的——都是采用千叶(一个给商家用的页面搭建平台)作为模块搭建平台,并在千叶的搭建能力之上,包装了一层页面投放策略的管理。其实到这里,模块化方案和会场并无二致,只是模块的实现采用了 Prax 来兼容 Weex 和 H5 :
1、编码阶段
- 每个模块都会定义自己投放的数据结构
- 模块内不包含页面通用依赖(如 Rax 基础组件、 mtop 等)
2、渲染阶段
- 有一个 Solution 控制页面模板的渲染,对于Weex则是负责包裹 Weex 头尾
- Solution 将模块相关数据规整,Web模块代码可以异步获取, Weex 一般同步输出到 Bundle 中,而模块所用的数据都会放在页面上提供一个简易方法获取
- Soluiton 引入 PI(页面初始化脚本), PI 将相关模块数据取出根据模块信息获取模块代码进行渲染,并从页面上获取数据交给模块
而到了无界,这些就完全不 work 了。毕竟无界是走的模块级定投,容器只有一个,因此投放场景很可能和心智造、 Minisite 场景交叉:
- 没有模块也没有心智造和 Minisite 页面,那么我们就需要创建一个只展示无界模块的页面
- 已经有心智造或 Minisite 页面了,我们需要将当前模块插入到页面中
而我们采用了如下技术方案将无界的定投模块插入到页面中:
- 用户发起搜索,搜索请求到达服务端
- 服务端请求返回时,若命中心智造和 minisite 场景,则返回对应场景投放的千叶页面 URL
- 服务端请求返回时,若未命中心智造和 minisite 场景,且命中有无界定投的模块,则返回一个空页面 URL
- 服务端请求返回时,若命中有无界定投的模块,则返回无界定投模块信息,包括模块名称、模块版本、模块数据、展示规则
- 客户端创建长颈鹿 Weex 容器,渲染心智造、 minisite 页面,或者空页面,然后将无界定投模块数据传入 Weex 容器
- 页面渲染触发 PI 执行,PI 获取无界定投模块,拉取定投模块的代码,创建实例后基于展示规则插入到页面中
通过这样的方式,最终渲染出当前场景下所有的模块内容。另外在无界后台我们有一套场景干预规则,解决场景交叉时进行一些手动干预。与此同时我们还提供了一套动态数据源机制,方便三方 HSF、TPP 数据能直接绑定到模块上,实现模块和数据解耦。
页面渲染
页面渲染如上述所示,依旧是通过斑马。但与之前不同的是:
由于是模块化搭建,页面通过 PI 统一管控,页面渲染依赖 PI 行为控制
对于长颈鹿容器,同样是 Native 创建 Weex 容器渲染,但与之前渲染一个仅包含一个模块的 Weex 页面显然是不同的,长颈鹿容器内渲染的也是一个真正的模块化搭建的页面
对于无界定投的模块,提供了插入机制,解决了场景交叉时的展示问题
模块管理
对于页面内的通信,由于页面通过 PI 统一管理,也就意味着模块的各种能力都需要依赖 PI 来进行实现。由于这样的楼层搭建一般通信结构都是扁平的,所以基本上通过模块冒泡给 PI , PI 下发给对应模块即可。不过一般不建议模块之间进行通信。
对于页面和容器通信,我们是在 PI 中提供了一些封装的能力,另外也可以自己调用容器提供的方法,与 Native 内嵌坑位的 weex-module 方案别无二致。
▐ 小结
由于长颈鹿内的技术方案已经脱离传统意义上的前端,更多设计客户端和服务端,是整个产品架构的设计,这里很难讲清楚,放一张图可能清晰一点:

这里前端技术又有了提升:
- 实现了可视化搭建,为商家&行业提供了运营阵地
- 为未来品牌&行业规模化提供了基础
- 提供了更好的行业共建机制
- 动态数据源+无界模块定投能力更加灵活多变
但这里我们还是有几个问题尚未解决:
- 我们和会场越来越像了,但是我们和会场模块并不互通(会场终于也用 Rax 了,但是他们用的是 Rax 1.0,我们还是 Rax 0.6)
- 搭建的粒度太粗,基于楼层的搭建不够灵活无法满足行业差异化诉求(想象一下搜索列表作为一个模块时,只是商品样式改下就要重新开发一个搜索列表)
6、深度搭建时代
搜索最擅长的显然就是搜索结果页那种商品瀑布流,将用户最想要、最有可能购买的商品推荐给他们。而这个能力也可以复用在诸如首页、频道、店铺、专辑等等地方。而当我们要在很多不同的地方去搭建这样一个列表页时,在上面所说的楼层搭建中,我们一般会怎么做呢?
- 首先,新建一个 XXX 搜索列表模块
- 找一个无尽列表组件
- 开发这个业务需要展示的商品坑位
- 将无尽列表组件里的 loadmore 中去请求 mtop 获取下一页数据
- 将模块发布供搭建使用
- 当有新的需求,就新增一个标记来判断,基于标记换一个数据和商品坑位展示
如果这么处理,若行业大面积规模化,会出现如下几个问题:
- 不同行业对于商品展示的要求不尽相同, 比如家电行业都会展示一些比较关键的产品属性,而家装行业则要更突出一些上门安装的服务,这也就导致商品坑位的展示不同,同时也意味着大量的开发成本
- 由于在一个仓库内开发,共建会更加困难,所有需求都会更容易压到自己头上
- 由于对接不同数据源,当业务逻辑出现交叉,前端代码里的各种判断也会指数级增加
这些显然都是我们不愿意看到的,我们将组件的不同场景完全剥离,可以发现一些规律:
- 无尽列表既然能抽出一个组件,那么它肯定是可以复用的
- 商品的展示和数据源的接入其实非常适合共建,让行业的前端对接行业自己的数据=专业的人做专业的事
进一步提炼:
- 交互可复用
- UI 根据场景自定义
- 数据根据场景自定义
所以我们有没有可能在这个理念上更深一步进行搭建呢?
模块化
答案显然是有的,深度搭建的概念其实就是用来解决这种问题。将页面上的模块基于功能进行了重新定义:
- 数据模块:自身没有任何 DOM 相关代码,只负责处理数据。并且监听一些事件,这些事件触发时会加载新的数据并将其交给接收其数据的下游模块,触发刷新
- 容器模块:自身其实是一个容器,负责接收数据,并将数据下发给展示模块去展示。但它自身不处理数据,而是通过触发数据模块定义的事件接口,告诉数据模块需要做什么。
- 展示模块:UI 展示模块不处理任何逻辑,唯一做的就是拿到交互容器模块给他的数据做展示。它内部甚至不处理任何事件,全都是以冒泡的方式到交互容器模块进行处理。
通过这样子的划分,容器模块控制了交互、展示模块控制了 UI 、数据模块控制了业务逻辑,比如一个包含筛选、商品流的列表更具体用 React hooks 来说就是:
- 数据模块本质上就是一个 reducer,对外暴露一个 [state, dispatch], state 包含筛选信息、商品数据,交给容器模块渲染;而 dispatch 则定义了 loadmore 、 changenav 等方法,供容器模块调用
- 容器模块将导航和商品坑位定义为纯展示区域,将筛选信息、商品数据传给关联的展示模块进行渲染,并传递给他们一些如点击事件的回调方法,当筛选发生点击时通过 dispatch 触发数据模块的 changenav ,而页面下拉到底时通过 dispatch 触发数据模块的 loadmore
- 展示模块就是纯粹的无状态 UI 组件,不同的组件用来展示不同的区域
合理的场景划分至关重要,不同业务场景应该是数据模块+容器模块+展示模块的组合,大多数情况下容器模块和展示模块可以复用,但数据模块都是需要重新开发的。尽可能让数据模块来适配容器模块和展示模块,不改变交互就不改变容器模块,不改变UI就不改变展示模块。
在这里模块的编写切换到了 Rax 1.0,与会场的开发方式一致以实现复用。Rax 1.0 针对 Web 做了很多优化,打出来的 bundle 也更加轻量,性能也好了很多,已成为天猫前端业务开发主要方式,因此不再需要使用 Prax 了。
页面渲染
这里和传统搭建有个很重要的不同,模块之间出现了关联关系。比如如下关联:
- 数据模块需要和容器模块&展示模块相关联,需要将 state 和 dispatch 交给对应模块
- 展示模块与容器模块管理,容器模块定义了区域,不同区域使用不同的展示模块
- 容器模块甚至能和容器模块做关联,实现多层嵌套展示,这种情况一般用于纯展示,不涉及交互(比如搜索列表筛选栏和商品瀑布流中间的空白区域)
那么我们就需要一个全局方式来处理这些关联。首先需要在搭建模块的时候去指明模块之间的关联关系,比如我自己是定义了三个字端:
- key :模块的唯一标识,给容器和数据模块使用
- data :如果是容器或展示模块,在其中填入所使用数据模块的 key
- container :如果模块在另外一个容器之内,则在其中填入所在容器模块的 key
data 和 container 都是二段结构的,比如 data 的 a:b 代表使用 key 为 a 的数据模块的 b 字端内的数据,而 container 的 a:b 则代表使用key为a的容器模块,并将自己作为其 b 区域的展示模块使用。
这几个字端都会在脚手架里,初始化时生成到 schema.$attr 中。而真正负责识别这些字端并将模块串起来的自然是页面初始化脚本—— PI ,PI 干了如下事情:
- 扫描所有数据模块,并将其实例化,存放在一起,并从渲染模块中将其剔除
- 将剩余的渲染模块基于 container 组织成一个树形结构,并对每个节点基于 data 关联数据模块,并将最上层进行渲染
- 将子模块相关数据传递给容器模块,并提供一个默认渲染方法。容器模块可以自己决定如何处理这些子模块相关数据,可以修改、合并、覆盖,修改完后使用渲染方法渲染即可。若其中还有还有下一级子模块,重复进行如下操作
模块管理
这里模块的通信有两种,一种是基于公用数据模块的通信,一种是基于 PI 的通信。
一个页面上可以有多个数据模块,而每个数据模块都可以对接到多个容器/展示模块(这也是为什么 data 是二段结构的原因)。因此当多个模块需要通信的时候,可以通过dispatch触发数据模块行为,数据模块刷新数据影响另外一个模块。
基于PI的通信一般都是针对一些特殊场景,比如一个很经典的例子——筛选列表筛选栏变形吸顶:当页面有很多模块,筛选列表并不是全屏大小而是跟着整个页面一起滚动,当筛选栏滚出视野外,它需要变成一个相对简单的结构吸顶。在这种场景下,由于吸顶层本身是一个绝对定位的层,而页面文档流也是一个层,两个层之间不基于 DOM 操作的话,最合理的方式就是基于一个数据模块进行状态共享。如吸顶组件定义了吸顶时的样式和正常的样式,并且暴露一个创建数据模块的方法, PI 在渲染吸顶组件时会单独为其创建一个数据模块来共享筛选栏状态。
▐ 小结
为什么要搞的这么复杂?其实就是希望能将 UI 和交互做的更加纯粹,当 UI 和交互都是针对单一场景、足够简单的时候,我们就能引入一些产品来进行提效,比如:
- 使用描述式的方式来零开发定义交互,生成容器模块,如 domagic
- 使用描述式的方式来零开发定义 UI ,生成展示模块,如 imgcook /魔切
通过这这样的方式,最终页面上大多数内容都变得可以复用,规模化的成本也就大大降低了。
7、智能时代
由于搜索还在深度搭建时代探索,以下是我基于团队方向 YY 的,但我相信这个时代很快就会到来
但上述的各种方式终究还是人肉的,需要人力投入的。既然工具能让我们以配置的方式解决交互和 UI ,那么有没有可能连配置都不需要,机器自动帮我们生成一个数据模块或者交互呢?
这就是我们团队正在做的,目前团队的同学正在尝试基于机器学习训练模型实现智能化UI。只需要给出一些关键信息(比如要展示商品的哪些字端),就会自动化的生成对应的展示模块或交互模块。这些模块使用到深度搭建之中,前端就只需要通过数据模块定义展示的内容来源就能完成整个页面的搭建。实现UI零成本。
而我们进一步扩展去思考,把大象装冰箱分为三步,那么把搜索智能化应该也只需要三步:
- 第一步,我们告诉机器要展示什么内容,它用最高效的方式展示给用户
- 第二部,我们告诉机器要展示哪一类的内容,它找出这一类内容最高效的方式展示给用户
- 第三部,我们告诉机器我们的场景,它找出符合该场景的内容展现给用户
具体一点可能是:
- 第一步,我们有了商品,让模型去训练出最好的商品展示方式
- 第二步,我们定义了说这里要展示一个权益模块,那么模型会给出最合适的展示内容,比如说展示一张店铺券,是展示店铺券的同时展示几个爆款商品诱导用户去下单,还是站在一个商品的维度将店铺券结合品类券、津贴一起给出一个惊人的折扣价诱导用户下单,抑或是找出当前用户期望购买的商品总价最接近的店铺券展示并诱导其凑单等等
- 第三步,我们定义了一个场景,比如告诉机器这是一个 XX 频道,那么机器自动能分析母婴频道的主力消费人群类型,然后针对这个人群类型去推荐最合适的内容。比如假设我们要搭建一个母婴频道,机器会自动基于母婴频道主力消费人群是宝妈,而宝妈养娃最痛苦的是需求商品种类繁多、同时质量担心得不到保证,因此给她推荐内容导购为主,同时穿插着一些品质上的背书比如用户评价、品牌保证、平台服务等等。
因此,我们可能需要一个三层的模型:
1、第一层基于不同的内容,找出最合理的UI界面来进行展示,也就是智能UI模型。
2、第二层则是需要产出这些内容,这里分了三个维度:行业&平台+品牌&店铺+货品。
- 针对行业差异化的诉求,行业运营决定这里需要展示的行业内容的类型和形式,比如刚才说的权益带商品的模式,那么就要通过行业表达模型找到最合适的权益以及结合这个权益之下最合适的货品;
- 针对纯粹的商品展示,则是将人货场的匹配做到极致,找到这个用户目前最想要的商品;
- 针对品牌&店铺,品牌需要塑造品牌在消费者侧的心智,对应的品牌会有自己的表达,比如品牌想要将一个新品打造成爆款,那么对于这个爆款的打造就需要一个品牌表达模型来辅助他们运营;
3、第三层则更为复杂
- 行业内容模型其实就是行业运营经验的沉淀,将运营目标具像成不同的场景,再将该场景下的运营经验具像化成内容,这里就需要行业侧各种类型的内容作为输入,而模型则需要基于以往的各种组合后的运营经验,给出最合适当前场景的内容组合;
- 品牌内容模型也是类似的,整合吸收品牌在整个淘系体系下的各种资源投放,为品牌&店铺的运营提供一些行之有效的运营建议(推荐模块),提升品牌运营的效率,降低运营成本;
- 对于人货匹配则是再拆分了三个模型,分别去处理货品、场景和用户;
货品模型:从货品中提炼出货品中的最吸引人的一些特质,比如卖点、好评、销量,以及将货品结构化,方便货品在不同的地方展示;
场景模型:基于用户的实时行为来定义当前用户的购买场景,他可能想买一台电视所以浏览了很多电视,抑或是在一家卖电视的专卖店里面找同型号线上价格,抑或是在过年准备给父母购置一台电视作为年货等等;
用户模型:基于用户的历史行为,将用户划归某个类型的人群,进行人群精细化运营。比如一个用户经常购买年轻人的潮流酷玩,但每到父亲母亲节或者特定时间就会购买一些长辈礼物的品类,说明是个有孝心的boy/girl,那么针对这类孝顺宝宝就可以在不同的节日或其他重要日子推荐一些给长辈送礼的内容
那么我们都有哪些数据呢?
- 行业&平台:行业有自己的沉淀,平台有各种营销玩法
- 品牌&店铺:品牌同样有主打新品、限时优惠、专题活动、线下门店等等
- 货品:各种商品沉淀下来的属性、评价、卖点等等
- 用户离线:用户的各种行为历史,以及手动收集的一些用户档案
- 用户实时:比如它最近的一些行为,从哪进入页面,在什么地理位置,什么时间点
One More Thing
由于我们不是活在未来,因此无法断定前端的未来到底是怎样的,但前端不会停止对于未来的探索。而这个未来不只是技术的未来,也是业务的未来。技术和业务是我们前进的两条腿,业务的诉求推动技术迈向新的高度,而更先进的技术也为业务带来更多的想象空间。
如果你不想再沉溺于过去,不想再埋头做为业务切页面的工具人,那就加入频道与 D2C 智能团队吧。有意向者请发送简历到 :[email protected]
本文作者:王令宇(天镶)
本文为云栖社区原创内容,未经允许不得转载。