
本文内容提炼:
1、如何建立图片数据与用户注意力之间的连接?
2、如何进行结构化规模化的图片生产?
2019 年双十一期间,鹿班面向集团电商场景输送了 10亿 规模的图片。从提升公域流量效率,到商家私域的表达赋能,随着场景的细分,分人群精细化运营的需求提出,对图片结构化生产,规模化生产在量和质上的要求不断提高。图像生成技术也在不断的演进,本篇将围绕鹿班最近一年的在生成能力上演进以及实践做展开,欢迎探讨交流。

上图是我们有过采访的在平台上卖姜茶的店铺的图片运营经验,可以看到不同场景下的商品图文,在内容和形式是极具多样性,这种多样性不同于海量商品的个性化多样性,这种多样性是对 C 端用户注意力更加精细的吸引,这种多样性是对 B 端商家运营能力的一个新命题。
那么如何满足这种多样性生产?如何建立图片数据与用户注意力之间的连接?如何对商家赋能?下面我会从图片生产的视角切入,尝试回答以上问题。
生产标准-图片结构化
在 C 端的商品分发链路上,得益于结构化的标准定义,使得商品的数据和特征可以被高效的传递收集处理,从而给予模型和算法充分的施展空间。
当尝试将商品图片的数据作为一个整体进特征提取计算时,无论是低层次的显示特征还是高维的语义隐式特征在基于深度神经网络处理后都变成了一个概率问题,但实际我们更希望把概率转换为确定性输入从而更准确的挖掘图片特征与用户行为之间的关联关系。
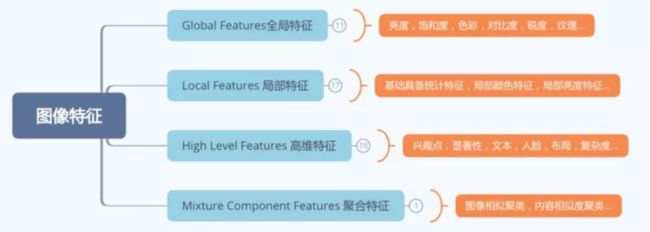
电商的图片生产除了最开始的拍摄外,更多的会依赖后期的图像处理软件,比如PS(photoshop)进行图文的创作编辑,根据图像处理软件的图层划分标准,我们对图片进行结构化的分层定义。给图片引入图层(layer)属性,从结构、色彩、文字(内容)三个维度对一张图片进行结构化的描述。通过结构化使得图片自身的属性特征可以被高效准确的传递收集处理,进而使得后续的生成加工成为可能。
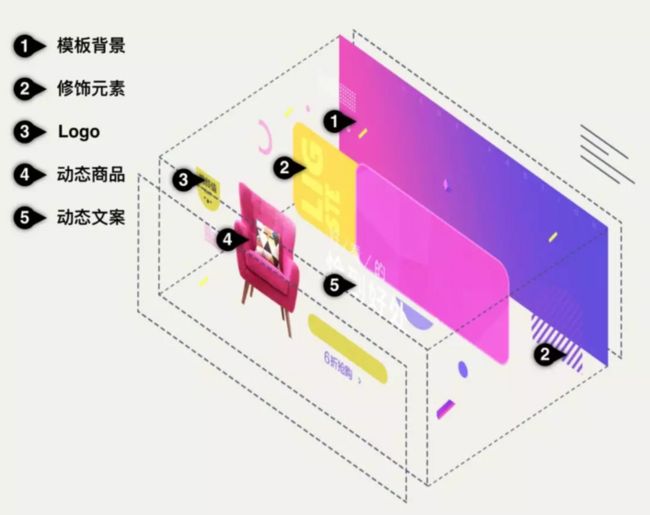
为了标准的执行,我们面向商家设计师开发了配套的生产工具,在保持设计师工作流程不变化的前提下,将原来非结构化的单张图片转换为自描述的 DSL 结构化数据,从而在生产的源头保证了图片数据结构化的执行实施。
生产工序-流程编排
当图片有了结构化的定义后,我们将图片的生成转换为成基于人机协作的数据匹配排序问题。为什么是匹配排序?
我们积累了大量的设计数据,相比之前非结构化的设计创意,通过图片结构化我们可以将设计精确解构到每一个图层,每一个元素,每一个文字。进而沉淀了可复用的数据资产。根据用户喜好,商品属性进行图片表达的好中选优,这就转化为一个数据匹配问题。
数据匹配包含两个部分:一是由设计师创作的面向特定场景或商品表达的设计数据,我们称之为模板;二是由用户属性数据以及在浏览商品图片过程中产生的的收藏、点击、购买等用户行为数据。
对于的匹配排序有两层,首先是商品图片和模板的匹配,这层通过定义设计约束进行参数化的求解实现匹配。
比如基于模板的背景色约束商品图片主色区间,根据模板结构布局约束商品图片主体形状等。通过图像检测/识别算法在线提取商品主体的图片特征,结合离线计算的模板特征进行匹配计算。
然后是用户特征与图片特征的匹配计算,在建模时我们把数据划分成三个特征组,分别是用户特征组,商品特征组合和图片特征组,通过 embedding 变换对得到特征向量进行两两交叉预测建模,之所以采用两两分别组合而不采用三组向量联合建模的原因是考虑到对于电商场景,商品特征与用户特征之间的信号更强,如果联合建模训练会导致图片的行为的关系不能有效的被学习到,而通过两两交叉建模,可以针对性的做预测结果的加权。
问题定义清楚后我们依然要面对来自业务的复杂性和快速响应问题,为此我们定义了生产 pipline,将生产流程与生产能力分而治之。面对复杂业务需求提供生产流程编排能力,为提高响应速度提供可插拔的生产算子模型。

► 生产流程-节点编排
将图片设计生产的理念流程化,流程系统化。通过工作流引擎实现生产节点的编排管理,从而让业务方可以灵活的按需求进行生产线的定义组装,满足多场景的生产需求。
► 生产能力-可插拔算子
算子定义了统一的输入输出以及必要的context,通过对约定输入的计算处理完成效果实现。
图像类算子:图像分割,主体识别,OCR,显著性检测等。
文本类算子:短标题生成,文字效果增强等。
规则类算子:人工干预,流程控制等。
► 通过这套生成引擎,白盒化的对生成能力进行分制管理,面向二方能力的开放友好,同时满足业务集成的灵活性。目前线上共管理了10个核心场景,33个生产节点,47种算子能力,通过编排组合实现了10亿规模图片的分场景矩阵式生成。
生产工艺-图文渲染
如果说生产架构解决了宏观的生产工序问题,那么渲染就是面向微观的工艺问题。
渲染首先要解决的是效果统一,除了直接通过服务端渲染图片以外,在商家侧需要所见即所得的二次编辑能力,也就是对于同一套 DSL 数据协议,在前后端需保证渲染效果统一,为此我们构建了前后端同构的渲染方案,开发了基于 canvas 的画布引擎,在前端通过 UI 的包装提供图片可视化编辑能力;在云端通过 puppeteer 无头浏览器加载 canvas 画布引擎实现图片生产。

其次渲染需要保证对视觉设计的还原能力,尤其是文字渲染效果。前端渲染对丰富文字效果的支持由于字体库安装问题很难完成,同时后端也缺乏对文字效果的标准协议定义。而有了同构的渲染能力后,我们可以将前端协议的优势与后端字体库的优势结合,灵活的完成视觉还原。
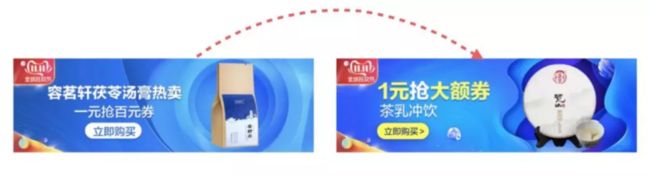
淘宝首焦 banner 场景下,单字单样式的模板较普通模板在 AB 分桶试验下点击率平均提升约 13% 。
生产保障-性能优化
在 10亿 量级的规模下,如果没有高性能的工程保障,一切效果的提升都是零,双十一期间鹿班的平均合图 RT<5ms ,从 DSL 解析到 OSS 上行链路完成平均 RT<200ms ,在没有增加机器资源的情况下,实现了相较于去年的整体系统吞吐性能提升 50% 。整个后端引擎分为两部分:
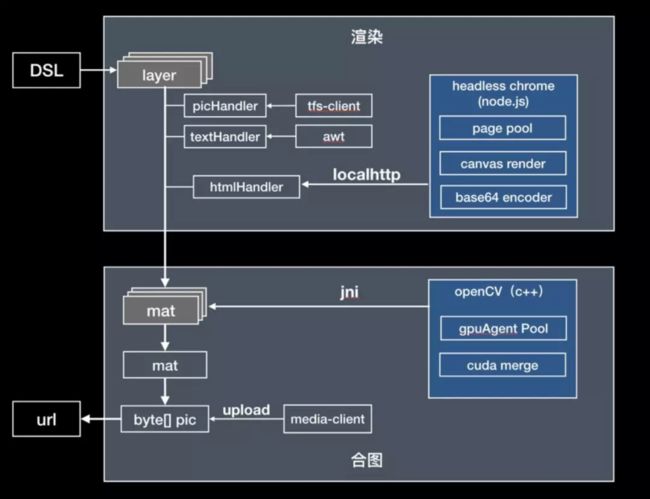
渲染:将结构化的 layer 数据转换为独立的图片数据流。不同类型图层转换交由对应的 handler 处理。执行并行化渲染。
合图:将渲染得到的多个图层数据进行图像合并计算,经过编码压缩,图片上传,得到成图。
性能优化主要分以下几点:
- 图层拉取并行化,本地采用 LRU-K 主动缓存,减少 tfs 拉图消耗。
- GPU 显存主动调度管理,对显存预先分段分片,减少频繁显存的申请分配与释放消耗。
- jpg 编码优化,通过 SIMD 进行加速,软编码的平均耗时由 70ms 下降至 20ms 。
未来展望
图片作为商品信息展示的重要载体,无论是在公域的搜索推荐还是私域的店铺详情都承担着传递商家意图与帮助消费者决策的双重作用。
对于商家:通过技术与数据赋能商家在图片生产上的持续优化,让结构化的图片能够更好的被机器理解,更高效的分发。同时增加商家的运营抓手。
对于消费者:利用更多维的图片特征获得对受众更泛化更精细的刻画能力,更好的满足甚至激发用户兴趣。
We are hiring
淘系技术部依托淘系丰富的业务形态和海量的用户,我们持续以技术驱动产品和商业创新,不断探索和衍生颠覆型互联网新技术,以更加智能、友好、普惠的科技深度重塑产业和用户体验,打造新商业。我们不断吸引用户增长、机器学习、视觉算法、音视频通信、数字媒体、移动技术、端侧智能等领域全球顶尖专业人才加入,让科技引领面向未来的商业创新和进步。
请投递简历至邮箱:[email protected]
本文作者:鲍军(推开)
本文为阿里云内容,未经允许不得转载。