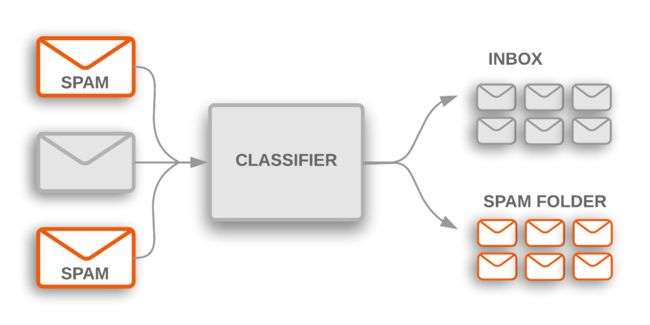
文本分类算法是一些大规模文字处理软件系统的核心。以下是两个典型的分类任务:
- 把一个文件划分到预设值的主题中:如邮件的分类。
- 情感分析:通过分析文本内容,得到主体想要表达的观点。
0 文本分类的流程
- 1:收集数据
- 2:探索你的数据
- 2.5:选择一个模型
- 3:准备你的数据
- 4:建立、训练、评估你的模型
- 5:调整参数
- 6:开发你的模型

1 收集数据
2 探索数据
列出一个表格:
| 文件个数 | a |
|---|---|
| 类数 | b |
| 每个类的样本数 | c |
| 平均每个文件的单词数 | d |
2.5 选择一个模型
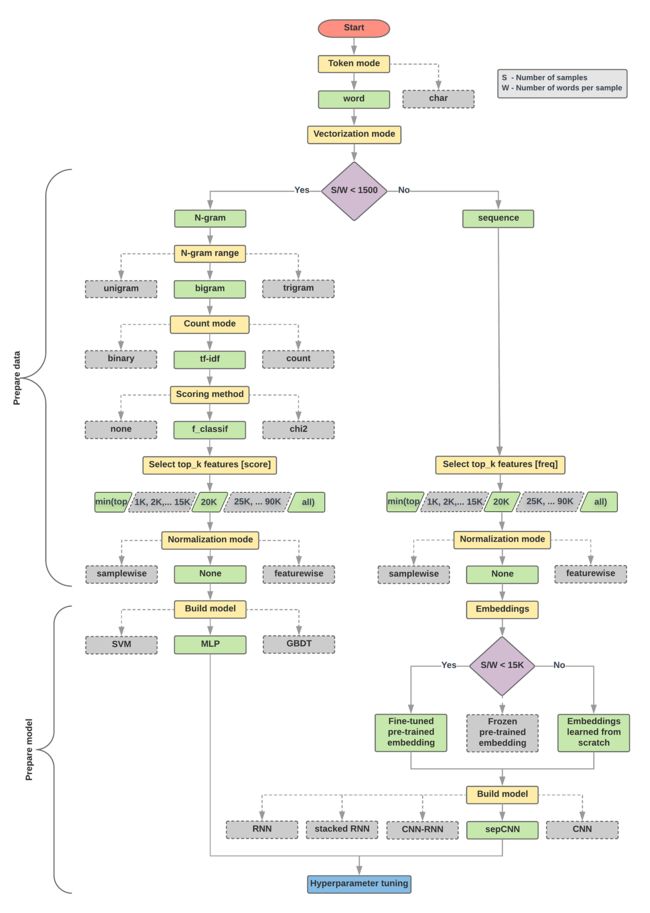
在对模型进行选择时,我们的目标是尽量获得最高的精确度和最低的时间代价。由于之前的研究,我们可以选择的模型有很多。但是,在如此多的模型中进行选择增加了选择的复杂性和对相应问题范围的扩大。
下面的流程图回答的问题有两个:
- 我们应该选什么模型?
- 如何准备数据可以高效地学习文本和标签之间的关系?
根据实验,我们可以计算一个值,来进行模型的选择。模型大致可以分为两种,一种是使用保留词序信息的,另一种直接把文本当作是“词袋”。序列模型包括CNN、RNN以及它们的变种。n-gram模型包括LR、MLPs(多层感知机,或称为全连接网络)、GDBT和SVM。
3 准备数据
首先,随机打乱数据。这样可以避免类与类之间的关系对模型造成困扰。如果数据集已经划分为训练集和测试集,则需要对两者同时进行shuffle;如果没有,可以先shuffle,再划分数据集。
其次,输入文本要转化为数字向量。这里有两个步骤:
- 分词:在这个过程会定义数据集的“字典”。这里有个小问题,应该把测试集的词也加入到字典吗?
- 向量化:定义一个好的特征可以表征文本信息。
让我们看一下,如何用这两步生成n-gram向量和序列向量。然后用特征选择和标准化技术优化向量表示。
3.1 N-gram 向量
什么是n-gram向量?本文被表示为n个相邻的词。考虑文本“The mouse ran up the clock”,这里的unigram(n=1)就是['the', 'mouse', 'ran', 'up', 'clock'],bigram(n=2)就是['the mouse', 'mouse ran', 'ran up', 'the clock'],以此类推。
分词
向量化
分词完成之后,需要把n-gram转化为数值向量。首先给词编号,然后再用one-hot表示、计数表示或TF-IDF表示。这三种方法是最常用的。通常情况下,TF-IDF比其他两种方式高0.25-15%的精确度。推荐使用这种方式编码,但是以上三种方法都需要占用大量存储空间。
特征筛选
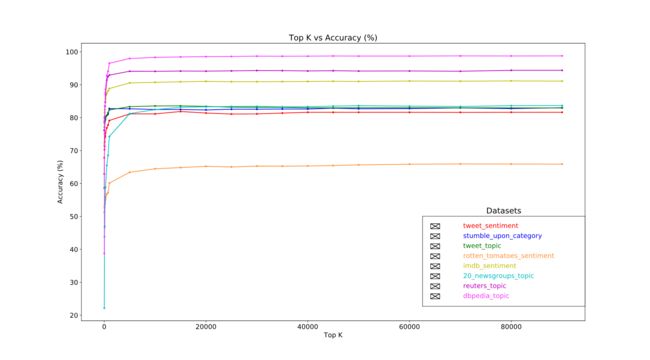
分词完成后,可能用有数万的token。但并不是都对标签预测有贡献,所以我们可以删去这部分token,例如低频词。我们也可以计算每个单词对标签预测的贡献程度,并且选出最有贡献的一些词。
有两种统计方法可以达到这个目的,F值和卡方。
更加重要的是,好多实验结果发现大约2万特征就可以达到精确度的峰值。然后再加一些特征贡献极小还有可能会带来过拟合从而影响性能。
标准化
标准化把所有的特征值转化为很小并且相近的值。这简化了学习算法中梯度下降的收敛。但是通过实验发现,标准化对文本分类影响效果比较小。
因此,对于n-gram的数据准备方面,需要我们做如下步骤:
- 分词
- 向量化为TF-IDF
- 用F值选择前两万个最有贡献的特征,并且删除出现频率低于两次的词。
小结,使用n-gram模型,我们舍弃了大量的词序和语法信息(有研究指出,占语义的20%)。因此这种方法也成为词袋模型。
3.2 序列模型
分词
可以分词也可以分字符。但实验证明分词效果会更好一点。
向量化
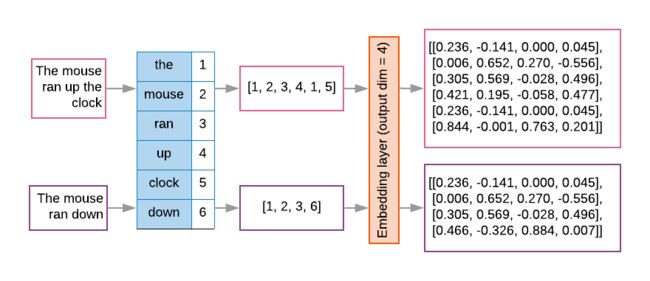
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Index assigned for every token: {'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}.
NOTE: 'the' occurs most frequently, so the index value of 1 is assigned to it.
Some libraries reserve index 0 for unknown tokens, as is the case here.
Sequence of token indexes: 'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
有两种向量化的方法。
- one-hot编码:对于每一句化都要生成一个稀疏矩阵。这种方法效率不是很高。
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
- word embedding
特征选择(同上)
小结,对于序列模型,需要做以下几步:
- 分词
- 创建2万单词的词汇表
- 向量化(word embedding)
- 把序列填充为固定长度
标签向量化
需要把标签转化为[0, num_classes-1],然后再用one-hot进行表示(以免标签之间产生关系)。
4 创建、训练和评估模型
本部分使用tf.keras API进行建模。
4.1 创建n-gram模型
n-gram没有词序信息和语法信息。这部分可以选择的模型有LR、GDBT、SVM和MLPs,一般情况下,MLPs会获得较好的性能。
4.2 创建序列模型
可以使用预训练的词向量(如Glove)作为序列模型的输入。否则的化,模型的第一层需要学习得到词向量。但是这里的实验结构发现,Glove词向量实验结果不是很好,这可能是因为训练嵌入层的上下文可能与我们使用它的上下文不同。实验发现,从头开始学习词向量与微调词向量获得了几乎相同的精确度。
我们对比了不同的序列模型,如CNN、sepCNN、RNN(LSTM&GRU)、CNN-RNN和堆叠RNN。结果发现sepCNNs比其他模型更加高效。
4.3 训练
在训练时,有三个关键的参数需要选择:
| 学习参数 | 值 |
|---|---|
| 评价矩阵 | 精确度 |
| 损失函数-二分类 | 二元交叉熵 |
| 损失函数-多分类 | 离散分类交叉熵 |
| 优化器 | adam |
真正训练的时候,使用的是fit方法。
| 训练超参数 | 值 |
|---|---|
| 学习率 | 1e-3 |
| Epochs | 1000 |
| Batch size | 512 |
| Early stopping | 参数:验证损失,patience:1 |
5 调整超参数
- 模型的层数:对于文档分类数据集,可以选择1-3层MLPs。两层的表现不错,有些三层的也可以。同样,我们也测试了4层和6层的sepCNNs,结果是4层的效果更好些。
- 每层的单元数:我们尝试了[8, 16, 32, 64],32/64效果还可以。
- 失活率:推荐值:0.2-0.5
- 学习率:从较小的值开始,如1e-4,查看训练过程,如果太慢就增加一点。如果模型不学习,尝试减少。
对于sepCNN模型,还有另外两个超参数:
- 核大小:卷积核大小。推荐值:3或5
- 词向量维度:推荐值:50-300
6 开发模型
开发模型时需要注意,训练集和测试集服从相同的分布,如果分布不一样,要重新(收集)分配数据集,然后再训练。
参考文献:
Google