Python结合MySQLdb,urllib等库主要进行偏后台数据库的自动化测试,同时页面元素涉及处理表格元素,并将获取的表格内容进行处理。
u 如何遍历一个表格并获取表格中需要的内容
思路是先获得表格行(tr),再通过行遍历所有的列(td),从而获得每一行的内容放入一个列表,通过对列表的下标处理获得需要的内容。
""""""
table_tr_list=browser.find_element_by_xpath('//[@id="tab_con"]/div[1]/div[2]/table').find_elements_by_tag_name('tr')#******取得所有行*** table_list=[] #*****定义表格总内容列表* for tr in table_tr_list: table_td_list=tr.find_elements_by_tag_name('td')#****通过每一行寻找这一行中每一列的所有元素** row_list=[]
for td in table_td_list: row_list.append(td.text)#****将获得的每一个元素内容追加进****row_list****列表 table_list.append(row_list)#******将获得的每一行的列表放入******table_list******列表中*****combination_name=[]
for i in table_list:
if i==[]:
pass
else: k=i[0]
combination_name.append(k)#****取得需要的内容*
u 数据库数据获得
当处理的数据涉及多个库时,只需要连接数据库中某一个库即可对数据库中所有表格进行操作,但是此时一些存储过程,表明等都需要加上databasename,比如表明用database_name.table_name来表示具体例子如下:
from selenium import webdriver
from time import sleep
import MySQLdb
import json
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )#****使****python****可以认识非****ASC****编码,例如中文 browser=webdriver.Firefox()
browser.get("http:\master-test.simuwang.com")#****进入官网browser.maximize_window()
sleep(5) browser.find_element_by_xpath(".//[@id='input_nick_lg']").send_keys(username)#****输入账号* browser.find_element_by_xpath("//[@id='input_pwd_lg']").send_keys(passwd)#****输入密码* browser.find_element_by_xpath(".//[@id='login_lgx']").click()#****点击登录* sleep(5)
browser.find_element_by_class_name('ignore').click()#****点击按钮关闭弹窗 js="var q=document.documentElement.scrollTop=800"
browser.execute_script(js)
table_tr_list=browser.find_element_by_xpath('//[@id="tab_con"]/div[3]/div[2]/table').find_elements_by_tag_name('tr')
table_list=[]
for tr in table_tr_list:
table_td_list=tr.find_elements_by_tag_name('td')
row_list=[]
for td in table_td_list:
row_list.append(td.text)
table_list.append(row_list)
attention_company_name=[]#****取得页面表格中所有数据* for i in table_list:
if i==[]:
pass
else:
attention_company_name.append(i[0])
connect=MySQLdb.connect(host='211.154.153.13',user='rz_cm_master',passwd='TbLuENLK',db='rz_combination_master',charset='gbk')
cursor=connect.cursor()
cursor.execute("SELECT company_short_name FROM rz_data_pool.company_information WHERE company_id IN ( SELECT company_id FROM rz_combination_master.cm_user_attention_company WHERE userid=(SELECT userid FROM rz_combination_master.cm_user WHERE cellphone=rz_combination_master.func_change_number('15818650780',1,1)))")#****从数据库中获取用户关注机构名字
此处只使用一个****connect****即实现了连接多个库的效果 result=cursor.fetchall()
list=[]
for i in result:
x=i[0]
y=x.split(',')[0]
list.append(y)
match_attention_company_name=0
for i in attention_company_name:
if i in list:
match_attention_company_name+=1 else:
print "用户关注机构与数据库不匹配" break
if match_attention_company_name==len(list):
print "用户关注机构与数据库完全匹配"
u 涉及文件下载的处理
进行自动化过程中有些用例需要用到文件下载,但是下载过程中浏览器总是弹出窗口,但是这个窗口又属于系统窗口无法定位,所有只能用非常之法处理,因为我用的是火狐浏览器,所有一下火狐浏览器处理会清晰一些,谷歌浏览器只提供思路。
首先通过以下代码是没用的:
profile = webdriver.FirefoxProfile()
profile.set_preference('browser.download.dir','d:\')
profile.set_preference('browser.download.folderList',2)
profile.set_preference('browser.download.manager.showWhenStarting',False)
profile.set_preference('browser.helperApps.neverAsk.saveToDisk','application/zip')
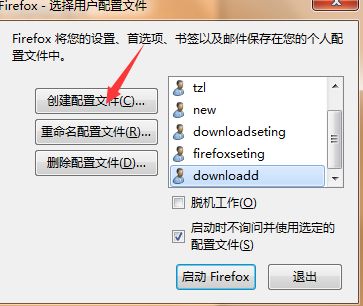
几经周折,最后找到的方法是重新建立一个firefox配置文件,使用配置文件打开浏览器并手动进行一次下载,下载后进去浏览器设置,改变下载路径和对应需下载文件类型的下载不提示设置,完了关闭。
建立配置文档流程如下:
开始à运行à输入firefox.exe –ProfileManagerà创建配置文件à设置配置文件路径(这里需要将配置文件路径记下来,最好手动输入吧- -!,页面整个路径就是配置文档的完整路径,后面需要用到)à保存à使用配置文件打开浏览器à下载与需要自动化验证下载的文件类型à点开浏览器设置à设置路径并查看对应文件类型是否已经默认不提示下载à关闭浏览器

编辑test:
profile = webdriver.FirefoxProfile('C:\Users\Administrator\AppData\Roaming\Mozilla\Firefox\Profiles\se3w4tfi.downloadd')#****配置文件路径 browser=webdriver.Firefox(profile)#****使用配置文件路径打开浏览器 browser.get("http://master-test.simuwang.com")#****进入官网****
browser.maximize_window()
需要注意的是,如果脚本中存在有登录过程,账号密码可能已经被配置文件记住,所以会直接跳过登录过程,因此脚本中也需要删除登录代码。
Google浏览器处理方式:
from selenium import webdriver
from time import sleep
options = webdriver.ChromeOptions()
prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': 'd:\'} #download.default.dorectory****:设置下载路径
#profile.default content settings.popups:****设置为****0****禁止弹窗 options.add_experimental_option('prefs', prefs)#****将设置导入新打开的浏览器 driver = webdriver.Chrome(executable_path='D:\chromedriver.exe', chrome_options=options)
driver.get('http://master-test.simuwang.com')
就完事了
u 数据格式处理
在用例编写过程中,很多时候需要进行断言,一般我是使用的self.assertEqual()方法。此间涉及很多数据格式处理,因为表面相同的数据当格式不同时,也会比较成为不同。
在进行数据处理之前可以对取得数据使用print type()查看数据类型。
实例一:
在写脚本过程中我需要进行文件下载验证,但是下载路径是中文名字
---C:\用户中心\下载--- 文件名字是从页面取得的unicode类型
在脚本书写时涉及到两个部分的处理:1、因为系统只认识gbk编码的中文,所以需要将路径中的中文目录进行gbk转码,2、文件名是从页面取得,也需要转码为gbk,具体代码如下:
import os.path
file_name="****基金组合****"#****默认导出文件名称 file='D:\'+u'****用户目录****'.encode('gbk')+'\'+u'****下载****'.encode('gbk')+'\'+file_name.decode('utf-8').encode('gbk')+'.csv'#****对中文文件名进行转码 result=os.path.exists(file)
self.assertEqual(result,True,'****导出文件失败****')#****断言导出文件存在
Unicode转GBK----str.encode(‘gbk’)
Str格式转换GBK---str.decode(‘utf-8’).encode(‘gbk’)
实例二:
在写脚本过程中我经常会需要验证数据库中数据与页面表格中数据的一致性,但是数据库中数据直接用MysqlDb取得后格式是(‘data’,),无法用于数据比对,另外存在一些Decimal数据,格式为decimal(‘data’,),为处理这些数据,使之成为可以比对的整型或浮点型,有一下两个方法
方法1(主要用于取得一些字符串数据):
def Obtain_database_data(sql_string):
import MySQLdb
connect=MySQLdb.connect(host='****数据库地址****',user='username',passwd='passwd',db='databasename',charset='gbk')
cursor=connect.cursor()
cursor.execute(sql_string)#****从数据库中获取用户自定义组合名字 result=cursor.fetchall()
list=[]
for i in result:
x=i[0]
y=x.split(',')[0]
list.append(y)
return list
方法2(主要用于处理decimal类型数据):
def Get_decimal_data(sql_string):#****获得数据库中****decimal****数据类型并进行转化 import MySQLdb
connect=MySQLdb.connect(host='****数据库地址****',user='username',passwd='passwd',db='databasename',charset='gbk')
cursor=connect.cursor()
cursor.execute(sql_string)
result=cursor.fetchall()
list=[]
for i in result:
for j in i:
if len(str(j))==4:
list.append('None')#****数据库中为空时的处理 else:
m=float(str(float(j))[:-2])#****数据库中不为空时处理 list.append(m)
return list