【人脸识别】AirFace:Lightweight and Efficinet Model for Face Recognition
论文链接:https://arxiv.org/abs/1907.12256
作者提出该方法的动机:
- 在使用MobileFaceNet从头训练使用ArcFaceloss,使用小的输入尺寸,模型难以拟合(所以作者提出了Li-ArcFace);
- 为人脸识别设计的小网络较少;
论文的贡献:
- 基于ArcFace loss提出了Air-Face loss
- 改进了MobileFace网络结构;
- 引入了注意力机制CBAM;
- 使用蒸馏技巧;
准备工作:
Loss function(这节的内容是推理了arcFace的公式,感兴趣可以看一下)
常规的softmax loss函数:
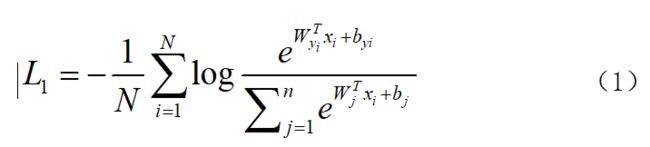

由于softmax 缺少增大类间距离,减少类内距离的能力。在sphereFace和NormFace中,移除了偏置项,并固定了以下参数:

且:


尽管(3)式能够保证同一个公式的高相似度,但是却不能很好的区分不同的类别,本文中使用了N-Softmax表示L2。
ArcFace的作者在(3)式中增加了angular margin m在 中,这样有效的增加了类类间的紧密程度和类间的差异,ArcFace公式如下:
中,这样有效的增加了类类间的紧密程度和类间的差异,ArcFace公式如下:

作者提出的方法:Li-ArcFace
ArcFace的作者增加了一个angular margin m在![]() ,将
,将![]() 作为target logit。
作为target logit。
本文方法中,作者移除了偏执项,同时通过L2回归让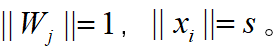
![]() 代表了
代表了![]() 和
和![]() 的角度
的角度![]() 。作者首先提出一个线性函数:
。作者首先提出一个线性函数: 同时作者也增加了angular margin m在target logit中。最终的target logit:
同时作者也增加了angular margin m在target logit中。最终的target logit:![]() 。最终的Li-ArcFace函数形式:
。最终的Li-ArcFace函数形式:

使用线性函数代替cosine函数有两个优势;
- 当角度取值在0和π+m之间时,函数结果是单调递减的。这样函数好拟合,特别是特征尺寸较小的时候。
- 提出的loss函数增加是线性的。在图二中效果比较直观:
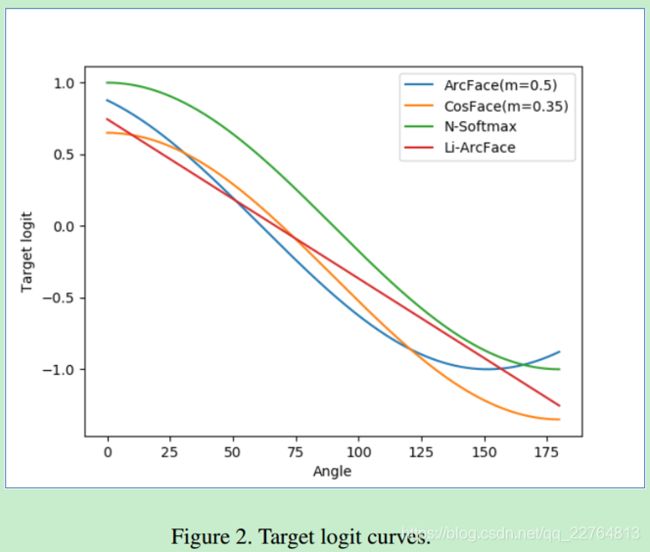
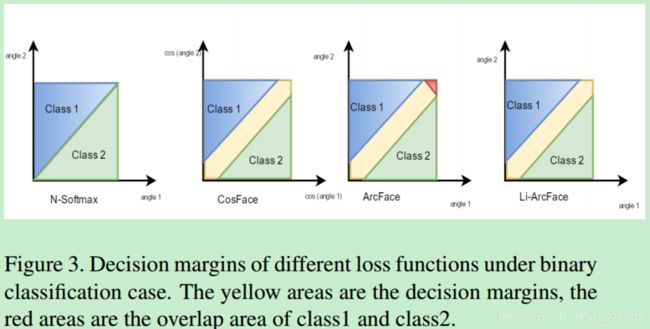
在arcface中,类别之间有重叠;(图3我也看不太懂)
Network architectures
MobileNetV1:使用depthwise separable convolution;
MobileNetV2:引入了inverted residuals和linear bottlenecks去提升网络效率;
MobileFaceNet:通过使用global depthwise conv(GDC)去代替global average pooling,原因:面部的特征学习权重应该不一样,但是global average pooling却把他们当作一样的权重去考虑了,所以使用GDC自己学习面部的不同权重。
作者是在MobileFace网络结构上进行了修改:
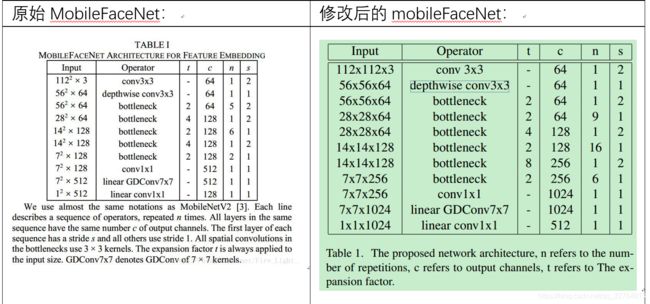
作者对于mobileFace的修改主要体现在以下几点:
1)在每个bottleneck中增加了注意力机制(CBAM【18】),并将cbam中的第二个激活sigmoid修改为1+tanh。
2)所有的mobileFace原先使用的relu,修改为prelu;
3)Expansion factor因子的变化(Expansion factor:从linear bottleneck到深度卷积之间的维度比称为Expansion factor(扩展系数),该系数控制了整个block的通道数);
Training tricks for face recognition
- 使用大量loss函数去微调模型,模型的泛化性更强(作者使用了Li-ArcFace,ArcFace);
- 作者说在512维的特征空间中,轻量级模型很难很好的拟合到分布式特征,但是可以找一个大的模型来进行引导(蒸馏)。
Experiments
Evaluation Results of Li-ArcFace
实验一:最后一层权值损耗参数的重要性:

作者通过对最后一层卷积的损耗做实验,证明了最后层权值损耗的重要性;
实验二:超参数m的重要性(Li_arcface参数m)
作者在做实验的时候,由于arcface在训练时无法拟合,所以就使用了N-softmax进行了预训练,而且在设置m时,作者发现LiArcFace的参数在0.4和0.45效果最好,ArcFace的参数在0.45和0.5效果较好,看表3。
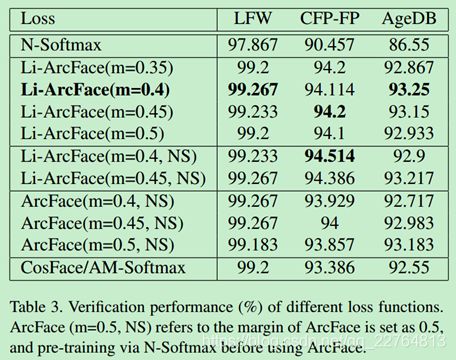
实验三:loss函数之间的比较
表3中ArcFace,Li-Arcface,CosFace在LFW上的验证精度差距都很小,但是都明显好于N-softmax;在CFP-FP测试集上,Li-ArcFace效果是优于ArcFace和cosFace;
作者重点对比了不同的loss在CFP-FP和AgeDB上的测试结果:

图4中,Li-ArcFace效果优于其他loss,在测试集AgeDB上,Li-ArcFace效果略好于其他loss函数。总言之,Li-ArcFace效果与Arc-Face等loss函数相比,效果最好,同时Li-ArcFace训练不需要预训练模型。
总结:自己使用了该文提到的注意力机制和蒸馏,效果还挺好的;