DRBox:可旋转边界框的旋转不变目标检测器
目录
- 论文下载地址
- 代码下载地址
- 论文作者
- 模型讲解
- [背景介绍]
- [论文解读]
- [训练网络]
- [补充细节]
- [金字塔输入]
- [卷积结构]
- [预选框设置]
- [结果分析]
- [数据集]
- [基准]
- [检测结果]
论文下载地址
[论文地址]
代码下载地址
[GitHub-official]
论文作者
模型讲解
[背景介绍]
在遥感图像目标检测领域,定向框的标注越来越收到关注,作者在论文提出了水平框的三大缺点与定向框的三大优点。
①水平框的缺点
尺寸与宽高比不能反映目标的真实形状。目标和背景像素没有有效分离。密集对象难以分离。
②定向框的优点
定向框的宽度和高度反映了目标的物理尺寸,这有助于定制预选框。定向框比水平框包含更少的背景像素,因此目标和背景之间的分类更容易。定向框可以有效地分隔目标,并且在相邻目标之间没有重叠区域。

在本文中,定义了定向框来克服上述困难。定向框是一个带有angle参数的矩形,用于定义其方向。定向框需要五个参数来回归其位置,大小和方向。与水平相比,定向框更紧密地围绕了目标的轮廓,因此克服了表中列出的所有缺点。
给定两个框,检测算法评估它们的距离非常重要,该距离用于在训练期间选择阳性样本,并抑制检测中的重复预测。水平框常用的标准是交并比(IoU),旋转框也可以使用。两个目标框 A A A和 B B B之间的 I o U IoU IoU定义如下: I o U ( A , B ) = a r e a ( A ⋂ B ) a r e a ( A ⋃ B ) IoU(A,B)=\frac{area(A \bigcap B)}{area(A \bigcup B)} IoU(A,B)=area(A⋃B)area(A⋂B)其中 ⋂ \bigcap ⋂和 ⋃ \bigcup ⋃是两个定向框之间的布尔运算。定向框之间的布尔运算比BBox更为复杂,因为两个定向框的交集可以是不超过八个边的任何多边形。定向框的另一个标准是角度相关的IoU(ArIoU),其定义如下: A r I o U ( A , B ) = a r e a ( A ^ ⋂ B ) a r e a ( A ^ ⋃ B ) cos ( θ A − θ B ) A r I o U 180 ( A , B ) = a r e a ( A ^ ⋂ B ) a r e a ( A ^ ⋃ B ) ∣ cos ( θ A − θ B ) ∣ ArIoU(A,B)=\frac{area(\hat A \bigcap B)}{area(\hat A \bigcup B)}\cos (\theta_A-\theta_B)\\ArIoU_{180}(A,B)=\frac{area(\hat A \bigcap B)}{area(\hat A \bigcup B)}| \cos (\theta_A-\theta_B) | ArIoU(A,B)=area(A^⋃B)area(A^⋂B)cos(θA−θB)ArIoU180(A,B)=area(A^⋃B)area(A^⋂B)∣cos(θA−θB)∣其中 θ A \theta_A θA和 θ B \theta_B θB是定向框 A A A和 B B B的角度, A ^ \hat A A^是与定向框 A A A保持相同参数的定向框,角度参数是 t h e t a B theta_B thetaB而不是 θ A \theta_A θA。ArIoU考虑了角度差,因此,当定向框角度差从0度变为90度时,定向框 A A A和 B B B之间的 A r I o U ArIoU ArIoU单调减小。当 ( θ A − θ B ) (\theta_A-\theta_B) (θA−θB)接近180度时,这两种定义的行为有所不同。
I o U IoU IoU和 A r I o U ArIoU ArIoU的使用方式不同。 A r I o U ArIoU ArIoU用于训练,因此它可以强制模型学习直角,而 I o U IoU IoU用于非最大抑制(NMS),因此可以有效去除角度不准确的预测。
[论文解读]
定向框使用卷积结构进行检测,如下图所示。输入图像经过多层卷积网络以生成检测结果。最后一个卷积层用于预测,其他卷积层用于特征提取。预测层包括K个通道,其中K是每个像素位置中预选框的数量。预选框是一系列预定义的定向框,对于每个预选框,预测层将输出一个表示其是否为目标对象或背景的置信度预测向量以及一个5维向量,该向量为预测目标定向框之间的参数偏移量和相应的预选框。需要进行解码处理才能将偏移量转换为准确的预测定向框。最后,对预测的定向框进行置信度排序,并通过NMS删除重复的预测。
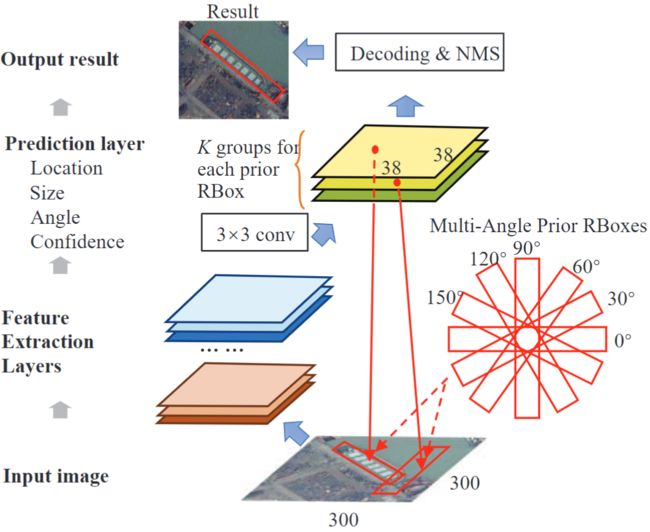
多角度预选框在中扮演重要角色。卷积结构确保预选框可以在不同位置移动以搜索目标对象。在每个像素位置上,预选框旋转角度以生成多角度预测,这是定向框与其他基于边界框的方法之间的关键区别。检测中使用的宽高比根据对象类型决定的,这减少了预选框的总数。
[训练网络]
从SSD训练过程扩展到涉及角度估计。在训练过程中,每个真实定向框根据其与预选框的 A r I o U ArIoU ArIoU分配了预选框。 A r I o U ArIoU ArIoU是非交换函数,这意味着 A r I o U ( A , B ) ArIoU(A,B) ArIoU(A,B)与 A r I o U ( B , A ) ArIoU(B,A) ArIoU(B,A)不同。当预选框 P P P与真实定向框 G G G满足 A r I o U ( P , G ) > 0.5 ArIoU(P,G)>0.5 ArIoU(P,G)>0.5则匹配成功。分配后,匹配的预选框被视为正样本,并负责计算位置损失和回归角度。 A r I o U ArIoU ArIoU的使用有助于训练过程选择具有适当角度的预选框作为正样本,因此可以在训练过程中大致了解物体的角度信息。匹配后,大多数预选框为负样本。
通过添加角度相关项,将定向框的目标损失函数从SSD的目标损失函数进行扩展。总体目标损失函数如下: L ( x , c , l , g ) = 1 N ( L conf ( c ) + L rbox ( x , l , g ) ) \mathrm{L}(x, c, l, g)=\frac{1}{N}\left(\mathrm{L}_{\text {conf }}(c)+\mathrm{L}_{\text {rbox }}(x, l, g)\right) L(x,c,l,g)=N1(Lconf (c)+Lrbox (x,l,g))
其中 N N N为匹配的预选框的数量。置信度损失 L c o n f ( c ) L_{conf}(c) Lconf(c)是所有选择的正样本和负样本的两类softmax损失。定向框回归损失 L r b o x ( x , l , g ) L_{rbox}(x,l,g) Lrbox(x,l,g)类似于SSD和Faster R-CNN,其中计算了预测定向框与地面真实定向框之间的smooth L1 loss:
L r b o x ( x , l , g ) = ∑ i ∈ P o s ∑ j ∑ m ∈ { c x , c y , w , h , a } x i j smooth L 1 ( l ^ i m − g ^ j m ) \begin{array}{l}L_{\mathrm{rbox}}(x, l, g) \\=\sum_{i \in P o s} \sum_{j} \sum_{m \in\{c x, c y, w, h, a\}} x_{i j}\operatorname{smooth}_{\mathrm{L} 1}\left(\hat{l}_{i}^{m}-\hat{g}_{j}^{m}\right)\end{array} Lrbox(x,l,g)=∑i∈Pos∑j∑m∈{cx,cy,w,h,a}xijsmoothL1(l^im−g^jm)其中 x i j ∈ { 1 , 0 } x_{ij}\in\{1,0\} xij∈{1,0}是将第 i i i个预选框与第 j j j个真实定向框进行匹配的指标。定义如下的 l ^ \hat l l^与 g ^ \hat g g^,分别是参数真实值 g g g与其相应的预选框 l l l的偏移量: t ^ c x = ( t c x − p c x ) / p w , t ^ c y = ( t c y − p c y ) / p h t ^ w = log ( t w / p w ) , t ^ h = log ( t h / p h ) t ^ a = tan ( t a − p a ) \begin{array}{c}\hat{t}^{c x}=\left(t^{c x}-p^{c x}\right) / p^{w}, \quad \hat{t}^{c y}=\left(t^{c y}-p^{c y}\right) / p^{h} \\\hat{t}^{w}=\log \left(t^{w} / p^{w}\right), \quad \hat{t}^{h}=\log \left(t^{h} / p^{h}\right) \\\hat{t}^{a}=\tan \left(t^{a}-p^{a}\right)\end{array} t^cx=(tcx−pcx)/pw,t^cy=(tcy−pcy)/pht^w=log(tw/pw),t^h=log(th/ph)t^a=tan(ta−pa)
上式中分别是位置回归,尺寸回归和角度回归。角度回归项应用正切函数以适应角度参数的周期性。
[补充细节]
[金字塔输入]
应用金字塔输入策略,即将原始图像重新缩放为不同的分辨率,并分割为重叠的300×300的patch。定向框网络将应用于每个子图像,并且该网络仅检测具有适当大小的目标。非最大抑制应用于整个图像的检测结果,这不仅抑制子图像内的重复预测,而且还抑制不同子图像的重叠区域的重复预测。金字塔输入策略可帮助检测网络在大小物体之间共享特征。此外,本文使用的卫星图像通常非常大,因此子图像的分割过程和非最大抑制有助于检测超大图像中的物体。
[卷积结构]
定向框使用删除全连接层的VGG进行检测。删除conv4_3之后的所有全连接层,卷积层和池化层。然后,在conv4_3层之后添加一个3×3卷积层。conv4_3的特征图为38×38,因此可能会出现小于8个像素的小目标漏检。
[预选框设置]
本文对三个DRBox网络分别进行了车辆检测,船舶检测和飞机检测的训练。比例和输入分辨率设置相同确保现有RBox的区域充分覆盖目标,因此可以有效地捕获不同大小的对象。在船舶检测中,很难区分目标的头和尾。在这种情况下,真实定向框和多角度预选框的角度在0度到180度之间变化。用预选框检测舰船目标,定向框的大小为 20 × 8 , 40 × 14 , 60 × 17 , 80 × 20 , 100 × 25 20×8,40×14,60×17,80×20,100×25 20×8,40×14,60×17,80×20,100×25像素,角度为 0 : 30 : 150 0:30:150 0:30:150。使用尺寸为 25 × 9 25×9 25×9像素且角度为 0 : 30 : 330 0:30:330 0:30:330的现有RBox来检测车辆对象;预选框尺寸为 50 × 50 , 70 × 70 50×50,70×70 50×50,70×70像素,角度为 0 : 30 : 330 0:30:330 0:30:330,可以检测出飞机物体。用于舰船,车辆和飞机检测的每个图像的预选框的总数分别为43320、17328和34656。
在NVIDIA GTX 1080Ti和Intel Core i7上DRBox达到70-80 fps。输入金字塔策略产生的时间成本不超过 4 / 3 4/3 4/3倍。考虑到子图像之间的 1 / 3 1/3 1/3重叠,DRBox达到了每秒1600×1600像素的处理速度。使用相同的卷积网络架构,在作者的数据集上,SSD和更快的R-CNN的速度分别为70 fps和20 fps。
[结果分析]
[数据集]
作者的方法应用于卫星遥感图像的目标检测。作者的数据集包括三类对象:车辆,轮船和飞机。车辆是从中国北京的市区收集的。船只在长江,珠江和东海以外的码头和港口附近收集。飞机是从中美15个机场的图像中收集的。该数据集最近包括约12000辆汽车,3000艘船和2000架飞机。取出约2000辆汽车,1000艘船和500架飞机作为测试数据集,并使用其他数据进行训练。
图像中的每个对象都用RBox标记,该RBox不仅指示对象的位置和大小,还指示对象的角度。开发了Matlab工具以使用RBoxes标记数据。
[基准]
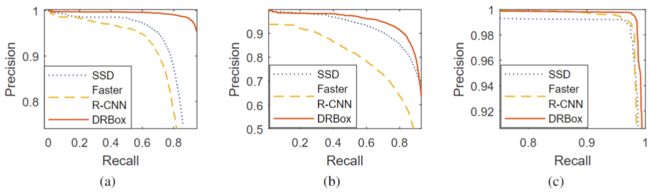
作者将DRBox的性能与使用BBox的检测器进行比较。SSD和Faster R-CNN用作基于BBox的方法的基准。所有目标检测网络使用相同的卷积架构和相同的训练数据。针对数据集优化了SSD中使用的预选框和Faster R-CNN中使用的预选框。所有其他超参数也针对数据集进行了优化。
[检测结果]
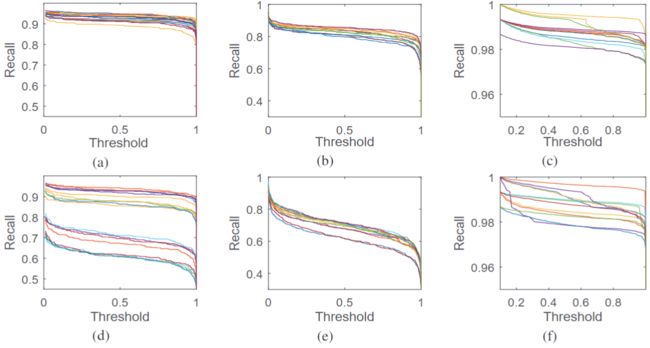
下图展示了使用RBox(DRBox)和BBox(SSD)检测到的船舶,车辆和飞机。与IoU> 0.5的真实边界框匹配的预测边界框以绿色绘制,而假阳性和假负性预测结果分别以黄色和红色绘制。DRBox可成功检测到港口区域和开阔水域中的大多数船舶,而SSD几乎无法检测到附近的船舶。车辆和飞机的检测结果还显示,与DRBox相比,SSD产生更多的虚警和误检。
下图显示了DRBox的更多结果。与开放水域相比,港口区域的船舶检测更具挑战性,而DRBox在两种情况下均能很好地完成。由于体积小且背景复杂,因此很难检测到车辆。在作者的数据集中,每辆车的长度约为20像素,宽度约为9像素。幸运的是,作者发现DRBox成功地检测了隐藏在高楼大厦阴影下或停在彼此之间非常近的车辆,还发现DRBox不仅可以输出汽车的位置,而且可以预测每辆汽车的行驶方向。