(系列笔记)6.决策树(上)
决策树——既能分类又能回归的模型
1、决策树
决策树上一中非常基础又常见的机器学习模型。一颗决策树(Decision Tree) 是一个树结构(可以是二叉树或非二叉树),每个非叶节点对应一个特征,该节点的每个分支代表这个特征的一个取值,而每个叶节点存放一个类别或一个回归函数。
使用决策树进行决策的过程就是从根节点开始的,提取出待分类项中相应的特征,按照其值选择输出分支,以此向下,知道达到叶子节点,将叶子节点存放的类别或者回归函数的运算结果作为输出(决策)结果。
决策树的决策过程非常直观,容易被人理解,而且运算量相对小。它在机器学习当中非常重要。如果要列举“十大机器学习模型”,决策树当列前三。
直观理解
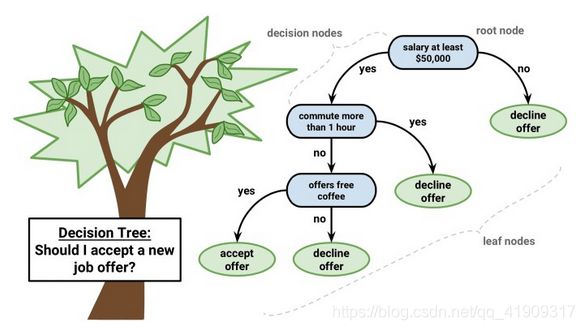
这棵树的作用,是对要不要接受一个offer做出判断:
此树一共有7个节点,其中4个叶子节点和3个非叶子节点。它是一棵分类树,每个叶子节点对应一个类别。
那么有4个叶子节点,并不是代表有4个类别,从图中可看出,一共2个类别:accept offer(接受)和dicline offer(拒绝)。
理论上讲,一棵分类树有n个叶子节点时(n>1,只有1个结果也就不用分类了),可能对应2~n个类别,不同判断路径可能得到相同的结果。如图例:拿到一个offer后,要判断3个条件:1、年薪;2、通勤时间;3、免费咖啡。这三个条件根据重要程度,越重要的越靠近根节点,即年薪低于5W美元,直接pass…以此类推。
这三个非叶子节点(含有根节点),统称决策节点,每个节点对应一个条件判断,而这个条件判断的条件,我们叫做特征。图例有3个特征。
当我们用这棵树来判断一个offer的时候,我们就需要从这个offer提取这些特征(年薪,通勤时间,是否有免费咖啡),然后将特征值输入决策树,然后按照根节点向下进行筛选,达到的叶子所对应的类别就是预测结果。
构建决策树
简单讲,有以下几步:
- 准备若干的训练数据(假设m个样本);
- 标明每个样本预期的类别;
- 人为选取一些特征(即决策条件);
- 为每个训练样本对应所有需要的特征生成相应值——数值化特征;
- 将通过上面的1-4步获得的训练数据输入给训练算法,训练算法通过一定的原则,决定各个特征的重要程度,然后按照决策重要性从高到低,生成决策树。
2、几种常用算法
决策树的构造过程是一个迭代的过程,每次迭代中,采用不同特征作为分裂点,来将样本数据划分成不同的类别。被用作分裂点的特征叫做分裂特征。
选择分裂特征的目标,是让各个分裂子集尽可能地“纯”,即尽量让一个分裂子集中的样本都属于同一类别。如何使得各个分裂子集“纯”,算法也有很多:
I.ID3算法
最直接最简单的ID3算法,核心是:以信息增益为度量,选择分裂后信息增益最大的特征进行分裂。
首先,先讲一下信息熵:
假设一个随机变量x有n种取值,分别为{ x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn},每一种取值取到的概率分别是{ p 1 , p 2 , . . . , p n p_1,p_2,...,p_n p1,p2,...,pn},那么x的信息熵定义为:
![]()
熵表示的是信息的混乱程度,信息越混乱,熵值越大。
设S为全部样本的集合,全部样本一共分为n类,则:
![]()
其中, p i p_i pi为属于第i个类别的样本,在总样本中出现的概率。
再讲一下信息增益:
信息增益的计算公式:(样本集合S基于特征T进行分裂后所获取的信息增益)
![]()
其中:
- S S S为全部样本集合, ∣ S ∣ |S| ∣S∣为 S S S的样本数;
- T T T为样本的一个特征;
- v a l u e ( T ) value(T) value(T)是 T T T的一个特征值;
- S v S_v Sv是 S S S中特征T的值为 v v v的样本的集合, ∣ S v ∣ |S_v| ∣Sv∣为 S v S_v Sv的样本数;
II.C4.5
前面提到的ID3只是最简单的一种决策树算法。它选用信息增量作为特征度量,虽然直观,但却有一个很大的缺点:ID3一般会优先选择取值种类较多的特征作为分裂特征。
因为取值种类多的特征会有相对较大的信息增益——信息增益反应的是给定一个条件以后不确定性被减少的程度,必然是分的越细数据集确定性更高。
被取值多的特征分裂,分裂成的结果也就容易细;分裂结果越细,则信息增益越大。
为了避免这个不足,在ID3算法上进行改进:C4.5算法:
C4.5选用信息增益率(Gain Ratio)——用比例而不是单纯的量作为选择分支的标准。
信息增益率通过引入一个被称作分裂信息(Split Information)的项,来惩罚取值可能性较多的特征。

ID3还有一个问题:就是不能处理取值在连续区间的特征。例如上面的例子中,假设训练样本有一个特征是年龄,取值为(0,100)区间内的实数,ID3就不知如何完成。
为此C4.5在这方面也有弥补:
- 把需要处理的样本(对应整棵树)或样本子集(对应子树)按照连续变量的大小从小到大进行排序。
- 假设所有m个样本数据在特征上的实际取值一共有k(k<=m)个,那么总共有 k-1 个可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的特征值中两两前后连续元素的中点。
- 根据这 k-1 个分割点把原来连续的一个特征,转化为 k-1 个特征的最佳划分。
但是,C4.5也有问题:当某个 ∣ S v ∣ |S_v| ∣Sv∣和 ∣ S ∣ |S| ∣S∣的大小接近的时候:
![]()
为了避免这种情况导致某个其实无关紧要的特征占据根节点,可以采用启发式的思路,对每个特征先计算信息增益量,在其信息增益量较高的情况下,才应用信息增益率作为分裂标准。
C4.5的优良性能和对数据和运算力要求都相对较小的特点,使得它成为了机器学习最常用的算法之一。它在实际应用中的地位,比ID3还高。
III.CART
ID3和C4.5构造的都是分类树,还有一种算法在决策树中应用非常广泛,他就是CART算法。
CART算法全称:Classification and Regression Tree分类和回归树,不仅可以用来分来也可以用来回归。
CART算法的运行过程和ID3及C4.5大致相同,不同之处如下:
- CART的特征选取依据不是增益量或者增益率,而是Gini系数(Gini coefficient),每次选择Gini系数最小的特征作为最优切分点。
- CART是一颗严格二叉树,每次分裂只做二分。
Gini系数
Gini系数本是统计学概念,20世纪初由意大利学者科拉多基尼提出,是用来判断年收入分配公平程度的指标。Gini系数本身是一个比例数,取值[0,1]。
当Gini系数用于评判一个国家的民众收入时,取值越小,说明年收入分配越均匀,反之则越集中。当Gini系数为0时,说明这一个国家的年收入在所有民国中平均分配,当Gini系数为1时,则说明该国该年所有收入都集中在一个人手里,其余的国民没有收入。
在Gini系数出现之前,美国经济学家马克斯 劳伦茨提出“收入分配的曲线”(劳伦茨曲线)
在这里插入图片描述
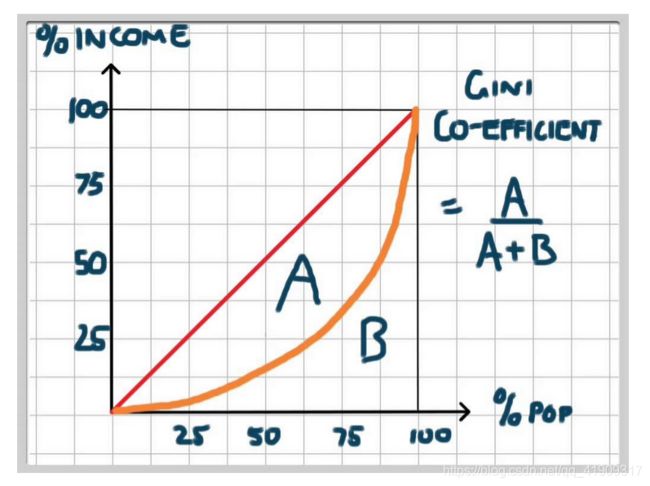
图中横轴为人口累计百分比,纵轴为该部分人的收入占全部人口总收入的百分比,红色线段表示人口收入分配处于绝对平均状态,而橘色曲线就是劳伦茨曲线,表现的是实际的收入分配情况。根据图可知,横轴75%处,如果依据红色线段,对应纵轴也应该是75%,但是按照橘色曲线,只有不到40%。
A是红色线段和橘色曲线所夹部分面积,而B是橘色曲线下的面积。Gini系数实际上就是 A A + B \frac{A}{A+B} A+BA 的比值,此概念在经济学领域远比在机器学习中有名。
Gini系数的计算方法
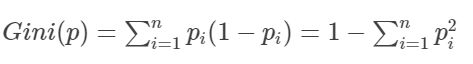
对于二分类问题,若样本属于第一类的概率是 p p p,则:
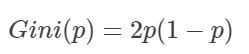
可得,若p=0.5,则Gini=0.5;若p=0.9,则Gini=0.18。0.18<0.9根据CART原则,当p=0.9时,这个特征更容易被选中作为分裂特征。由此可见,对二分类问题中,两种可能性的概率越不平均,越可能是更佳优越的切分点。
另外,还有一个Gini指数(Gini Index)经常被提及,并在CART算法中代替Gini系数,其实Gini指数就是基尼系数乘100倍作为百分比表示,两者其实是一个东西
注:回归树和分类树的区别在于最终的输出值到底是连续的还是离散的,每个特征(分裂点决策条件)无论特征值本身是连续的还是离散的,都要被当做离散的来处理,而且都是被转化为二分类特征,来进行处理:
- 如果对应的特征是连续的,处理与C4.5算法相似;
- 如果特征是离散的,若该特征共k个取值,则将这一个特征转化为k个特征,对每一个新特征按照是不是这个值来分Yes和No