拿到一个文本数据集,需要查看数据集文本的基本信息,包括词频、文本长度、类别分布等。这里以文本分类的数据集为例,对数据集基本特征进行可视化显示, 作为一般性demo。使用的库包括:pandas,matplotlib,wordcloud等,展示的信息包括:
- 词频分布
- 一级分类数量分布
- 二级分类数量分布
- 一级分类文本长度分布
- 文本长度分布
- 词云
Demo源码路径:https://github.com/zqhZY/semanaly/tree/master/mobile_classify
在信息展示前对原始数据做了预处理,将语料库转化成CSV格式文件,方便处理,数据包含列:
id,text,first_class,second_class
1052353,您好 很高兴 为您 服务 哎 你好 我想 咨询 一下 就是我 之前 有 开 一个 这个 宽带 的 然后 已经 到期 了然 后 我想 换 个 低一点的 资费 的 是 要 新装 吗 还是 怎么样 嗯嗯 呃 到期 之后...,办理,变更
导入依赖
为解决代码里显示中文,和matplotlib显示中文的问题,需要指定代码为utf-8编码, 最后配置matplotlib为微软雅黑字体(需要自行安装)。
# -*- coding:utf-8 -*-
import sys
import nltk
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
reload(sys)
sys.setdefaultencoding("utf-8")
pal = sns.color_palette()
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # enable chinese
词频可视化
首先导入数据集,由于预处理过程中已经对文本进行了分词操作,这里直接使用nltk库对数据集进行词频统计。需要注意讲数据集字符串进行utf-8转换。
dataset = pd.read_csv("./data/mobile_dataset.csv")
tokenstr = nltk.word_tokenize(" ".join(dataset.text.values).decode("utf-8"))
fdist1 = nltk.FreqDist(tokenstr)
listkey = []
listval = []
print u".........统计出现最多的前40个词..............."
for key, val in sorted(fdist1.iteritems(), key=lambda x: (x[1], x[0]), reverse=True)[:40]:
listkey.append(key)
listval.append(val)
# print key, val, u' ',
df = pd.DataFrame(listval, columns=[u'次数'])
df.index = listkey
df.plot(kind='bar')
plt.title(u'词频统计')
plt.show()

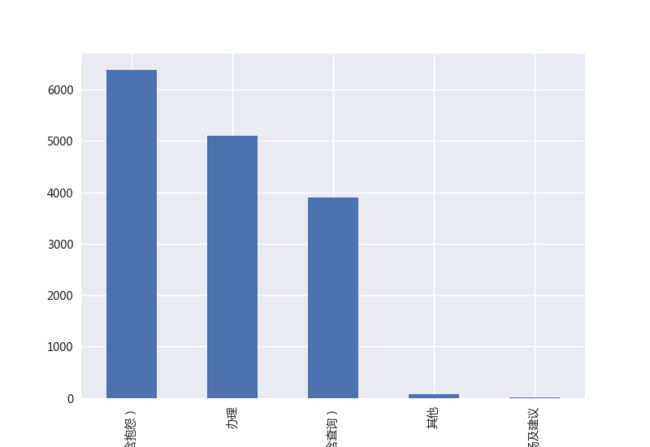
类别数目分布
这里数据集具有一级分类和二级分类两个层次的分类项目,分别对每个类别进行数目统计,之后进行直方图显示:
# plot class distribution
dataset.first_class.value_counts().plot(kind="bar")
plt.show()
dataset.second_class.value_counts().plot(kind="bar")
plt.show()

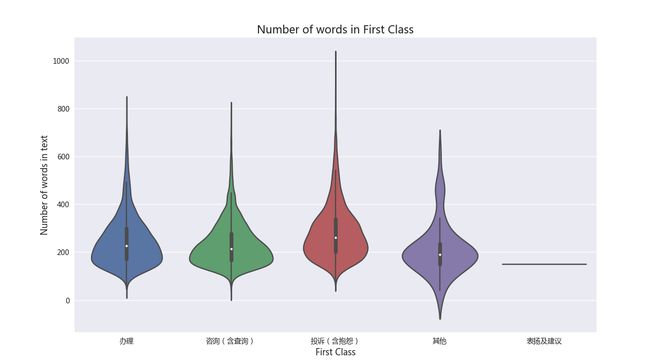
一级分类文本长度分布
这里作用为显示各个一级分类项目下的文本长度的分布情况,大于1000的文本长度直接设置为1000处理,目的在于使分布图更匀称。
# Number of words in the text ##
dataset["num_words"] = dataset["text"].apply(lambda x: len(str(x).split()))
dataset['num_words'].loc[dataset['num_words'] > 1000] = 1000 # truncation for better visuals
plt.figure(figsize=(12,8))
sns.violinplot(x='first_class', y='num_words', data=dataset)
plt.xlabel('First Class', fontsize=12)
plt.ylabel('Number of words in text', fontsize=12)
plt.title("Number of words in First Class", fontsize=15)
plt.show()

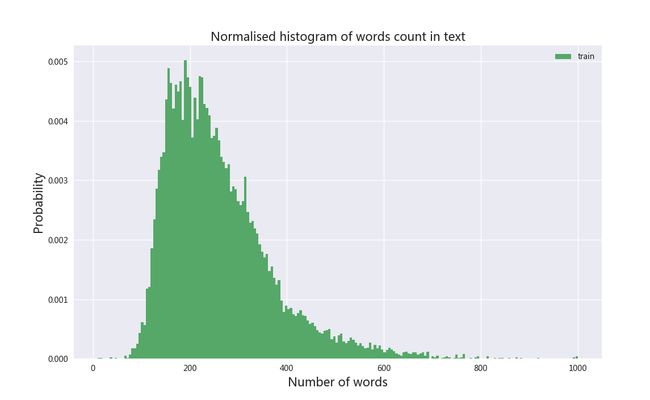
全局文本长度分布
为方便后面文本处理,文本整体的长度信息也很重要,这里使用直方图的方式展示文本长度分布,横轴为文本长度,纵轴为概率分布情况,也可以设置normed=True设置纵轴为数目。
# global len distribution.
plt.figure(figsize=(12, 8))
plt.hist(dataset["num_words"], bins=200, range=[10, 1000], color=pal[1], normed=True, label='train')
plt.title('Normalised histogram of words count in text', fontsize=15)
plt.legend()
plt.xlabel('Number of words', fontsize=15)
plt.ylabel('Probability', fontsize=15)
plt.show()
词云
词云部分遇到问题主要是汉子的显示,主要注意两点:
- 指定汉子字体
- 对字符串进行utf-8编码
如果觉得方方正正太古板,可以指定mask参数进行多样化显示。
# word cloud
# mask_img = imread("./data/images.jpg")
cloud = WordCloud(width=1440, height=1080, font_path="data/msyh.ttf").generate(" ".join(dataset.text.values).decode("utf-8"))
plt.figure(figsize=(20, 15))
plt.imshow(cloud)
plt.axis('off')
plt.show()

小结
中文文本的可视化经常会遇到汉子乱码的问题,一般都是由于字体不支持中文和字符串编码的原因。另外每次拿到新的数据想看看数据的基本信息总要重新去查具体库的用法,所以花时间整理了一下作为demo,后面继续添加更多的信息展示。
原创文章,转载注明出处。
更多关注公众号:
