这周主要总结了时间复杂度的学习,跟小伙伴们分享下,欢迎指正。
一、为何需要分析算法复杂度
挺多同学本科都学习过数据结构和算法这门课,但是有没有想过这门课到底是解决什么问题?科学家设计这些数据结构和算法是要干嘛?
其实,最终的目的只有一个:让我们写的代码在计算机上运行的速度更快,使用的内存更省!,可是如何才能知道我们写的代码使用多少运行时间和内存呢?这就需要分析算法时间复杂度和空间复杂度,只有学会分析这 2 者,才能知道我们设计的算法到底有没有性能的提升,不然你费了很大功夫想了一个算法,却发现运行速度慢如乌龟,得不偿失。
如果能够在运行算法之前就能知道算法大概的执行时间那就好了,而复杂度分析恰好可以解决这个问题!复杂度分析又分为 2 种:
1.1 运行后分析
这种就是写完算法直接放到机器上面跑,统计下到底用了多少时间和内存,但是这种方法有 2 个缺点:
- 测试结果依赖运行机器:性能强的机器当然需要的时间少
- 测试结果依赖于测试用的数据:比如对无序的数组和有序的数组排序的时间大不相同
1.2 运行前分析
那既然运行后分析有不可避免的缺点,有没有办法在纸上提前计算一下算法大概的执行时间和内存用量呢?当然有,就是今天的主角大 O 复杂度表示法!
二、大 O 复杂度表示法
我用一个例子来一步步解释大 O 复杂度表示法到底是什么意思:
int cal(int n) {
int sum = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum = sum + i * j;
}
}
}对 CPU 而言执行程序分为以下 3 步:
- 读如代码指令和数据
- 计算
- 输出数据
因为我们只是在运行前粗略地估计算法的运行时间,因此可以假设每行代码在 CPU 上运行的时间都相同,为 cputime,那么我们就可以直接计算出上面函数中所有代码执行的总时间(次数 x 单位时间),n 表示输入数据的规模:
- 第 2、3、4 行:每行需要 1 个
cpu_time,共 $3 * cputime$ - 第 5、6 行:因为都是循环 n 次,所以需要 $2n * cputime$
- 第 7、8 行:因为内外一共有 2 层 n 次的循环,所以需要 $2n^2 * cputime$
那么总的运行时间 T(n) 为:
$$ T(n) = (2n^2 + 2n + 3)cputime $$
对于每个确定的算法,所有代码的执行次数一定,那么上面的 T(n) 与所有代码的执行次数 $2n^2 + 2n + 3$ 成正比关系,比例系数就是 CPU 执行每行代码的时间 cputime,因为可以把上式写成大 O 复杂度表示法:
$$ T(n) = O(f(n)) $$
其中:
-
T(n):表示算法执行的总时间 -
f(n):表示算法总的执行次数,就是 $2n^2 + 2n + 3$ -
O():表示T(n)与f(n)的正比关系,也就是大 O 的由来
所以上面函数的总的执行时间又可以写成:
$$ T(n) = O(2n^2 + 2n + 3) $$
但是要注意:大 O 复杂度表示法并不是计算代码准确的运行时间,而是表示一种代码执行时间随着数据规模 n 增长的变化趋势,记住不是准确的时间,只是一种趋势而已,因为实际工作的算法可能需要接受很大量级的数据,通过分析算法运行时间与输入数据规模的变化趋势就能大概知道一个算法能不能在实际环境中很好的工作。
但是呢,上面的大 O 表示法还是不够简洁,比如当算法代码很多的时候,那我们是不是要在后面(或者前面)加上很多项:
$$ T(n) = O(2n^2 + 2n + 3 + 4n + 5n + ...) $$
这也不方便,因此大佬们又想了方法:只需要保留最大量级的运行次数即可!这是因为当输入数据规模很大,比如 100000, 1000000 等,常数项 3、一阶项 2n 等低阶的运行次数对最高次项 $2n^2$ 的影响并不大,所有代码的运行次数基本与最高阶 $2n^2$ 的运行次数保持一致。
因此我们只需要保留最高阶的运行次数就行,并且系数也可以去掉,因为我们表示的是变化趋势,常量系数并不影响变化趋势:
$$ T(n) = O(n^2) $$
这样最终的大 O 复杂度表示法就成型了!这里之所以写的那么详细是因为这个复杂度分析真的非常重要,因为我们只把算法写出来还不够,我们还要能够分析算法的优劣,并且以后的工作中如果需要选择数据结构来完成指定的功能,你也必须要提前考虑自己选择的数据结构的运行时间,这是非常重要的,你做的不是玩具,而是要能给用户提供体验良好的产品。
三、时间复杂度分析
学完大 O 表示法后,分析时间空间复杂度就很容易了,就是把前面的推导过程在不同的算法上计算一下,不过常见的复杂度分析分为这 3 种。
3.1 只分析循环次数最多的一段代码
前面说过,大 O 表示法只需要关注最高阶运行次数,而在实际的代码中最高阶运行次数的代码往往是嵌套循环的最内层代码,也就是循环执行次数最多的一段代码,这种情况我们就只需要分析它就可以:
int cal(int n) {
int sum = 0;
int i = 1;
for (; i <= n; ++i) {
sum = sum + i;
}
return sum;
}可以发现执行次数最多的代码是 sum = sum + i,利用前面的大 O 分析法,很容易得出 T(n) = O(n)
3.2 加法法则
加入我们的程序有 2 个单层的 n 次 for 循环,还有一个 2 层的 n x n 的 for 循环,注意这里每个循环的数据规模是一样的,都是 n,必须保证这一点:
int cal(int n) {
int sum_1 = 0;
int p = 1;
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}这种情况下我们只需要分别求出每个 for 的时间复杂度,然后加起来取最大的量级就行:
- $T1(n) = O(n)$
- $T2(n) = O(n)$
- $T3(n) = O(n^2)$
总的 T(n):
$$ T(n) = T1(n) + T2(n) + T3(n) = O(n) + O(n) + O(n^2) $$
因为我们取最大量级,所以如果忽略数据规模 n 的特殊情况,我们可以取上面 3 个复杂度的最大值为最终结果:
$$ T(n) = max[T1(n), T2(n), T3(n)] = max[O(n), O(n), O(n^2)] = O(n^2) $$
上面算法最终的时间复杂度即为 $O(n^2)$,加法法则一般的公式如下,就是上面过程的一般情况,只不过用数学化的表示而已,很容易理解:
$$ T(n) = T1(n) + T2(n) = max[O(f(n)), O(g(n))] = O(max[f(n), g(n)]) $$
3.3 乘法法则
类比加法法则,乘法法则就很好理解,加法是相加,乘法就是多个复杂度相乘,体现在代码中就是有多个嵌套的循环调用,比如:
int cal(int n) {
int ret = 0;
int i = 1;
for (; i < n; ++i) {
ret = ret + f(i);
}
}
int f(int n) {
int sum = 0;
int i = 1;
for (; i < n; ++i) {
sum = sum + i;
}
return sum;
}在 cal 函数的循环中每次都调用 f 函数来计算,所以总的时间复杂度是这两个函数的乘积:
$$ T(n) = T1(n) * T2(n) = O(n) * O(n) = O(n ^ 2) $$
注意不同与加法,乘法法则不是取最大的量级,而是直接幂次累加,要注意这点!
常用的时间复杂度
@(Google 王争)总结的几乎所有的复杂度如下图:

相信你应该听过 28 法则,20% 的技术能解决 80% 的问题,同样对复杂度分析,工作中常用就如下几个:
O(1)
代码中不含有循环、递归外的代码执行时间都为 O(1),记住 O(1) 并不是表示所有代码只执行一次,而是表示这些代码的执行次数不会随着输入数据规模 n 的变化而变化,即变化趋势是一个常量:
int i = 8;
int j = 6;
int sum = i + j;不管有多少行上面这样的代码,他们的时间复杂度都是 O(1)。
O(logn), O(nlogn)
这两种称为对数阶复杂度,在排序算法中比较常见,比如归并排序,快速排序的复杂度都是 O(nlogn),但是这种复杂度分析相对难一点,看个例子:
i=1;
while (i <= n) {
i = i * 2;
}这段代码的复杂度就是分析 i = i * 2 的执行次数,只要求出执行次数就搞定了,学过等比数列的很容易看出,$i = 2^x$,所以当:
$$ 2^x = n $$
求出:x = log2(n),则时间复杂度就是 O(log2n),依葫芦画瓢:
i = 1;
while (i <= n) {
i = i * 3;
}同理 x = log3(n),复杂度为 O(log3n),但是如果有很多不同的代码是不是都要改变底数呢?并不用,因为对数有个换底公式,可以把一个对数换成指定的底数:
$$ log_a^b = \frac { log_c^b } { log_c^a } $$
比如:
$$ log_3^n = \frac { log_2^n } { log_2^3 } = log_3^2 * log_2^n $$
其中 $log_3^2$ 是常数:
$$ log_3^n = C * log_2^n $$
因为大 O 表示法可以省略系数,所以:
$$ O(log_3^n) = O(C * log_2^n) = O(log_2^n) $$
可以看出 $log_3^n$ 求出的复杂度也可以表示为 $O(log_2^n)$,所以我们统一忽略对数阶的底数,都表示为 $O(logn)$ ,那么对于 $O(nlogn)$ 就很好理解了,就是利用乘法法则把 $O(logn)$ 复杂度的代码执行 n 次即可。
O(m + n), O(m * n)
这种复杂度有 2 个输入数据规模 m 和 n,这表示我们的算法接收 2 个数据的输入,但是因为数据规模不一定相同,所以不能简单的利用加法法则:
int cal(int m, int n) {
int sum_1 = 0;
int i = 1;
for (; i < m; ++i) {
sum_1 = sum_1 + i;
}
int sum_2 = 0;
int j = 1;
for (; j < n; ++j) {
sum_2 = sum_2 + j;
}
return sum_1 + sum_2;
}这种情况下,不能取最大的量级,因为数据规模不一样,我们只需要做复杂度的相加即可:T(n) = O(m + n),一般性的公式如下:
T1(m) + T2(n) = O[f(m) + g(n)]但乘法规则仍然有效,如果两个嵌套循环的数据规模不同也成立:
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
...T1(m) * T2(n) = O[f(m) * g(n)]四、空间复杂度分析
与时间复杂度类似,(渐进)空间复杂度表示的是算法的存储空间随着数据规模变化的趋势,空间复杂度分析比较容易:
void print(int n) {
int i = 0;
int[] a = new int[n];
for (i; i = 0; --i) {
print out a[i]
}
} 比如:
- 第二行:申请的 int 内存与数据规模 n 无关,空间复杂度为 O(1)
- 第三行:申请的 int 数组内存与数据规模有关,规模越大申请的内存就越多,空间复杂度为 O(n)
所以根据大 O 表示法,最终的空间复杂度就是 O(n),常用的空间复杂有:
- $O(1)$
- $O(n)$
- $O(n^2)$
空间复杂度分析比较简单,只需要看看有没有与数据规模相关的内存申请操作即可,我们的重点还是放在时间复杂度分析,不管是面试还是考试,时间复杂度都是必定会问到的。
五、不同情况下的复杂度分析
除了以上各种情况的复杂度分析外,还需知道不同情况下的复杂度,主要分为 4 种情况:
- 最好、最坏
- 平均
- 均摊
下面简单总结下,都挺好理解的。
5.1 最好、最坏情况时间复杂度
比如这个例子,在数组中查找元素 x 并返回索引:
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}假如要查找的元素 X 是数组的第一个元素,那么我们只需要循环一次就可以结束算法,此时的时间复杂度为 O(1),也即最好情况时间复杂度,但是假如我们要查找的元素 x 不在数组中,那么我们就需要循环 n 次结束算法,此时的时间复杂度为 O(n),对应的是最坏情况时间复杂度。
5.2 平均情况时间复杂度
通常情况下,最好或者最坏时间复杂度情况发生的概率不大,所以为了表示一般情况下的复杂度,我们使用平均情况时间复杂度,这种情况需要简单的计算,不过很容易,还以上面的例子:
// n 表示数组 array 的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}因为是平均情况所以可以做个假设,假设要查找的变量 x:
- 在数组中的概率为
1/2 - 不在数组中的概率也为
1/2 - 出现在 0 - n-1 这 n 个数组位置的概率相同,即为
1/n
所以根据概率乘法:要查找的数据 x 出现在数组中的任意位置的概率为 1/2n,先出现在数组中的概率乘以任意位置的概率,然后我们就可以将每个元素被找到时要查找的次数和对应概率相乘,最后再相加就得到算法的平均时间复杂度:
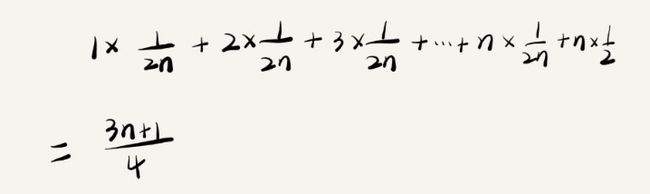
简单解释下:
-
1 x 1/2n表示数组第一个元素只需要循环查找一次 -
n x 1/2n表示数组最后一个元素需要循环查找 n 次 -
n x 1/2表示不在数组中的元素也需要查找 n 次,因为你必须把数组元素都遍历完后才能知道当前要查找的 x 不在数组中,那肯定就在数组外面喽,前面说过在数组外面的概率也是1/2
那么最后的结果就是全部想加,因为可以省略系数,所以上面查找元素 x 算法的时间复杂度也是 $O(n)$。虽然存在这 3 种情况,但是实际工作中分析算法的时间复杂度时并不需要严格分析这 3 种不同情况。一般情况下,使用前面讲的复杂度分析方法得出复杂度即可,如果要详细推导的话,可以计算下平均时间复杂度。
5.3 均摊时间复杂度
这是一种特殊情况下的复杂度,并不是很常见,但还是了解下,它的主要思想是:把运行时间多的情况下的复杂度拆分,并均摊到运行时间少的情况下,看个例子:
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0;
void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}这个算法实现如下功能,往数组中插入一个元素 val:
- 当数组满了后,对数组求和并把结果放到数组第一个元素的位置上,O(n)
- 当数组没满,直接插入元素 val 到空闲的位置上,O(1)
利用前面学习的复杂度分析可以很容易知道这两种情况的时间复杂度分别为:O(n) 和 O(1),但是考虑实际运行情况,我们总是先把数组一个个位置存满 O(1),然后满了之后再执行求和的操作 O(n),并且这两种情况的发生是有规律的。
因此我们可以把比较耗时 O(n) 复杂度的求和操作的均摊到不太耗时的 O (1) 插入操作上,这样总体的时间复杂度就会变成 O(1),这就是均摊的思想,总结下均摊时间复杂度的应用场景:
- 大多数情况 1 是不耗时的操作
- 个别情况 2 是耗时操作
- 情况 1 和情况 2 的操作在时间和逻辑上都是连续的,有清晰的前后执行顺序,就类似上面这个例子
如果你工作中的算法满足这 3 个条件,那么可以尝试用均摊时间复杂度来分析,这种情况比较少见,但还是要知道有这样一种类型。
六、复杂度分析总结
今天学习的时空复杂度分析是数据结构和算法学习中非常重要的一环,只有学会分析时空复杂度,我们才能知道自己写的算法到底能够提升多快,如果不会分析复杂度,那只会盲目地选择数据结构,盲目地设计算法,时间复杂度就是我们设计算法的指标。
我们学习数据结构和算法的目的就是为了写出运行速度更快,存储用量更低的代码,如果都不会分析算法的执行时间和内存用量,那最后何谈学过这门课或者学会这门课呢?请务必重视复杂度分析,后面设计算法会经常用到。
OK,大家下个专题见:)
本文来自我学习极客时间中「王争 数据结构与算法之美」的个人总结,文中的代码和文章的框架参考的原文,内容是一些我自己的理解,欢迎小伙伴们一起加入学习。

