算法基础:图算法和广度优先搜索(基于Python)
本博客所有内容均整理自《算法图解》,欢迎讨论交流~
谈到图算法和广度优先搜索,我认为首先要明白这两种算法是用来干嘛的。在这里我引用《算法图解》一书举的一个很经典的例子来讲解。
很多时候我们希望能够找出两样东西之间的最短距离,这里的距离不是单单是相距多少米,有很多含义。我们来看看以下几个问题:
- 编写国际跳棋AI,计算最少走多少步就可获胜;
- 编写拼写检查器,计算最少编辑多少个地方就可将错拼的单词改成正确的单词;
- 根据你的人际关系网络找到关系最近的医生。
其实以上几个问题都是最短距离问题。那么如何来解决这样的最短距离问题呢?
我们从最最简单的最短距离问题开始思考。假设你生活在北京,打算出去旅游,我们在此先忽略关于旅费啊交通啊等等一系列问题,仅仅考虑唯一的一个因素——距离,在上海、南京、天津、合肥、成都、东京、纽约这几个候选城市里,去哪个城市所需要旅行的距离最短呢?
很明显,这个最短距离问题很多人可以基于经验就回答出来,因为很明显天津最近;OK,那我们如果稍稍修改一下,我们不是求去一个城市,而是上面那些城市我都必须去一遍,最后再回到北京,选择什么路线距离最短呢?
好吧,这个问题就很复杂了,其实这是一个经典的旅行商问题,我们必须罗列出所有的可能路线,再一个一个比较才可以选出最优路线来。
很明显,这里我们需要画图,因为只有把这些城市在地图中的位置全部画出来,根据比例尺去计算彼此之间的距离,然后再根据不同的距离计算来选择路线。
所以,图算法是解决最短距离问题的非常有用的算法,而图算法中的广度优先搜索算法性能非常好,是接下来要详细介绍的一种图算法。
我们用一个更明确的问题来引入这两个概念。
假设你要从北京到成都去旅游,但是已经买不到北京直达成都的火车票或者飞机票了,于是你决定中转。现在有以下几种中转方案:
1、北京-乌鲁木齐-西安-成都
2、北京-合肥-武汉-成都
3、北京-大连-上海-重庆-成都
4、北京-九江-广州-昆明-成都
我们不考虑价格,仅仅考虑距离,这几种方案哪个距离最短呢?
你需要以下两个步骤:
- 使用图来建立问题模型。
- 使用广度优先搜索解决问题。
是的,处理方案就是这么简单,下面来详细介绍图和广度优先搜索。
1、图和广度优先搜索的基本概念
图模拟一组连接,根据连接的线段有方向和无方向分为有向图和无向图。
图由节点和边组成。一个节点可能与众多节点直接相连,这样直接相连的节点称为邻居。
图算法的定义比较难给,以下是百度百科给出的关于图算法的定义:
图算法指利用特制的线条算图求得答案的一种简便算法。无向图、有向图和网络能运用很多常用的图算法,这些算法包括:各种遍历算法(这些遍历类似于树的遍历),寻找最短路径的算法,寻找网络中最低代价路径的算法,回答一些简单相关问题(例如,图是否是连通的,图中两个顶点间的最短路径是什么,等等)的算法。图算法可应用到多种场合,例如:优化管道、路由表、快递服务、通信网站等。
其实说白了就是利用图来解决问题。
而广度优先搜索,简称BFS,是从根节点开始,沿着树的宽度(广度)遍历树的节点,如果发现目标,则演算终止。
也就是说,广度优先搜索是一种对树的遍历算法,遍历方式呢就是广度优先,即遍历完根节点之后,优先把根节点的所有子节点都遍历完,再进入任一子节点的下一层子节点进行遍历。与之对应的是深度优先。
举个例子来说明吧。例如你现在想买车,所以要查找你的人际关系网中有没有朋友是汽车经销商,或者朋友的朋友是汽车经销商,更或者是更远的关系有一个人是汽车经销商。很明显,如果直接你的朋友就有一个汽车经销商,那么肯定价格会比较便宜;而如果朋友的朋友有汽车经销商,肯定也能打折,但是恐怕就没有第一种情况那么优惠了;依此类推。
所以,你需要建立一个人际关系图,其中有一度朋友关系,二度朋友关系等等,其中一度朋友关系大于二度朋友关系,依此类推。
当你冥思苦想加上打电话询问你的朋友都有哪些朋友之后,你终于建立好了这张人际关系图。
此时,你肯定是首先在所有一度朋友关系的人里面搜索,看看有没有卖汽车的,如果有,OK直接找他了;如果没有,再去找二度朋友关系的人;如果再没有再去找三度朋友关系的人;依此类推。
上面这种思路就是广度优先搜索!
2、图算法的实现
掌握了图算法的基本概念之后,我们就需要来研究如何用代码来实现图算法了。
首先,图由多个节点组成,而每个节点又都与其邻居节点相连,那么我们如何表示“你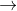 Bob”这样的关系呢?
Bob”这样的关系呢?
我们仔细看上面这样的形式,很明显这种箭头关系很像“键值”映射,所以我们可以用散列表来表示这种关系!
在这里,我们需要将节点映射到它的所有邻居节点。
表示这种映射关系的Python代码类似于下面这样:
graph = {}
graph["you"] = ["alice", "bob", "claire"]
注意,“你”被映射到了一个数组,名叫graph["you"],其中包含“你”的所有邻居。
对于只被其他节点映射,而没有映射到其他节点的节点,即树结构中的叶节点,它的邻居就是空集。
另外,散列表是无序的,所以添加键-值对的顺序无关紧要。
3、广度优先搜索的实现
接下来,我们就可以来实现一个广度优先搜索算法了。
依然沿用前面的查找汽车经销商的问题,我们按照以下步骤来实现广度优先搜索:
- 创建一个队列,用于存储要检查的人,即自己的一度朋友;
- 从队列中弹出一个人;
- 检查这个人是否是汽车经销商;
- 如果是,大功告成;如果否,将这个人的所有朋友加入队列;
- 回到第2步;
- 如果队列为空,就说明你的人际关系网中没有汽车经销商。
这里使用队列来存储朋友,是因为队列遵循先进先出(FIFO)的原理,这样就保证了广度优先,即上例中的优先检查一度朋友关系,一度朋友关系检查结束之后才会去检查二度朋友关系。
根据上面的思路,检查朋友中是否有汽车经销商的Python代码如下所示:
from collections import deque
def person_is_carseller(name):
return name == 'carseller'
def search(name):
search_queue = deque()
search_queue += graph[name]
searched = []
while search_queue:
person = search_queue.popleft()
if person not in searched:
if person_is_carseller(person):
print person + " is a car seller!"
return True
else:
search_queue += graph[person]
searched.append(person)
return False首先,我们从collections中导入deque函数,用于创建一个双端队列。
接着我们定义person_is_carseller函数用于判断一个人是否是汽车经销商,这里定义的判断方式是这个人的名字是否叫“carseller”,如果是就是汽车经销商,如果否就不是汽车经销商;虽然这种判断方法很搞笑,但是就这个示例而言是可以的,因为这个函数就只是用于判断,至于具体如何判断就不是我们需要详细思考的问题了。
接下来对于主要的search函数,我们首先创建双端队列,然后把一度朋友的姓名存储到该队列中,并创建一个名为searched的队列用于存储已经判断过的朋友名字;然后我们遍历队列,如果遍历的朋友名字不在searched队列内,且满足判断函数person_is_carseller,则查找成功;否则,如果不满足判断函数person_is_carseller,则将此人的朋友加入队列,并把此人的名字加入searched队列表明已检查过。
这样,我们就实现了一个使用广度优先搜索算法在众多朋友和多度朋友中查找汽车经销商的问题。