Flink Jobmanager HA配置(standalone)
1、简介
当Flink程序运行时,如果jobmanager崩溃,那么整个程序都会失败。为了防止jobmanager的单点故障,借助于zookeeper的协调机制,可以实现jobmanager的HA配置—-1主(leader)多从(standby)。
这里的HA配置只涉及standalone模式,yarn模式暂不考虑。
Flink版本: 1.1.2
Hadoop版本: 2.6.0
例如,有3个jobmanager,其HA情况如下:
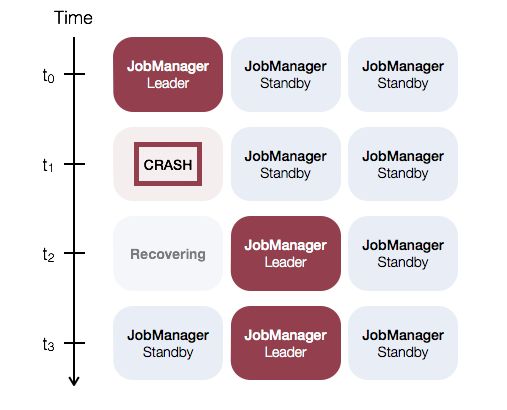
2、standalone HA的配置
由于jobmanager的HA配置依赖于zookeeper,因此,需要先配置zookeeper,可以参考我之前的文章:
zookeeper集群配置。
而且,由于Flink的state backend要依赖hdfs,因此假设Hadoop集群也已经配置完成,可参考这里
下面开始配置jobmanager的HA:
(1)flink配置文件:conf/flink-conf.yaml
#jobmanager.rpc.address: flinkHA模式下,jobmanager不需要指定,在master file中配置,由zookeeper选出leader与standby。
#==============================================================================
# Streaming state checkpointing
#==============================================================================
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs:///flink/checkpoints检查点生成的分布式快照的保存地点,默认是jobmanager的memory,但是HA模式必须配置在hdfs上,且保存路径需要在hdfs上创建并指定路径(hdfs dfs -mkdir /flink/checkpoints)。
# Path to the Hadoop configuration directory.
fs.hdfs.hadoopconf: /home/flink/hadoop/hadoop-2.6.0/etc/hadoop指定hadoop conf路径,这里需要告诉Flink,hadoop配置的路径,否则会报错,详见:这里
#==============================================================================
# Master High Availability (required configuration)
#==============================================================================
recovery.mode: zookeeper
recovery.zookeeper.quorum: flink:2181,data0:2181,mf:2181
recovery.zookeeper.storageDir: hdfs:///flink/recovery
recovery.zookeeper.path.root: /flink
recovery.zookeeper.path.namespace: /cluster_oneHA配置,storageDir存储jobmanager的元数据信息,包括用于恢复的信息;recovery.zookeeper.path.root代表zookeeper中节点信息;recovery.zookeeper.path.namespace,如果你的Flink集群有不止一个的话,那么这个值需要特殊配置,不能用默认的名字。关于这两个值的配置,我们可以在zookeeper的cli来查看路径:

(2)master file:conf/masters
ip:webUI,这里要将所有jobmanager的ip(host)与webUI(默认8081,可更改)都写好。
(3)配置zookeeper server
在zookeeper的zoo.cfg中配置,Flink之前应该已经配置好,这里忽略。
(4)启动zookeeper、Flink:
[flink@flink bin]$ start-cluster.sh
Starting HA cluster with 3 masters.
Starting jobmanager daemon on host flink.
Starting jobmanager daemon on host data0.
Starting jobmanager daemon on host mf.
Starting taskmanager daemon on host mf42.
Starting taskmanager daemon on host data1.
Starting taskmanager daemon on host s1.
Starting taskmanager daemon on host cninfo.
[flink@flink bin]$ webUI也可以看到配置信息以及log信息:
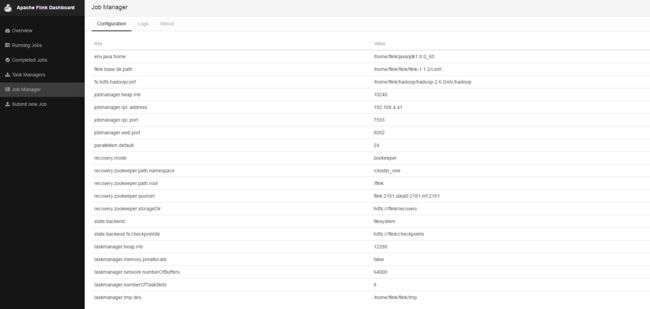
注意,当前的jobmanager的leader是192.168.4.41。
3、fail over测试
当前的jobmanager的leader是mf,程序正在运行中。
首先,我们停掉41上的jobmanager进程,模拟leader jobmanager的crash:
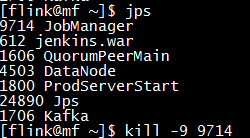
之后,webUI停止工作,此时后台进行jobmanager的failover,我们通过log文件观察failover的过程:
2016-10-31 11:44:53,801 WARN akka.remote.ReliableDeliverySupervisor - Association with remote system [akka.tcp://flink@192.168.4.41:7593] has failed, address is now gated for [5000] ms. Reason is: [Disassociated].
2016-10-31 11:45:34,030 INFO org.apache.flink.runtime.webmonitor.JobManagerRetriever - New leader reachable under akka.tcp://flink@192.168.4.22:2013/user/jobmanager:14062b96-52d9-4f7d-abda-b1b475581596.原来的leader:41连接失败,大概40秒后,恢复完成,新的leader:22.再次观察webUI:
![]()
jobmanager 的 HA大致的过程演示完毕。
https://ci.apache.org/projects/flink/flink-docs-release-1.1/setup/jobmanager_high_availability.html
http://apache-flink-user-mailing-list-archive.2336050.n4.nabble.com/writeAsCsv-on-HDFS-td1773.html
https://ci.apache.org/projects/flink/flink-docs-release-1.1/setup/config.html