说到磁盘,这是数据持久化保存的一种保存媒介,也是计算机必不可少的一种硬件设备,而想要用到磁盘就必须提到文件系统。
文件系统
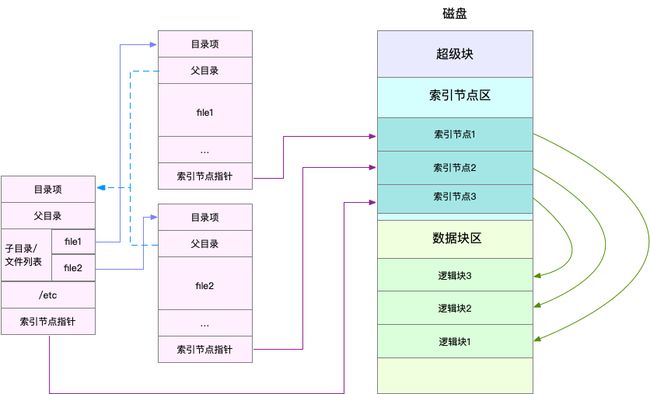
文件系统是构建在磁盘上的,用来管理文件的。为了方便管理,Linux为每个文件都分配了两个数据结构,索引节点(index node)和目录项(directory entry)他们主要用来记录文件的元信息和目录结构。
- 索引节点:又称为inode。用来记录文件的元数据,他和文件内容一样是会被持久化存储的。(存储到磁盘)
-
目录项:又称为dentry。用来记录文件的名字、索引节点指针以及与其他目录项的关联关系,目录项是由内核维护的一种内存数据结构。(内存缓存)
 文件系统.png
文件系统.png
每块磁盘在使用前都需要格式化,而格式化后就会被分成三个存储区,超级块,索引节点和数据块区。
- 超级块:存储整个文件系统的状态
- 索引节点区:用来存储索引节点
- 数据块区:存储数据。
VFS
Linux在用户进程空间与文件系统中间由引入了一个抽象层。也就是虚拟文件系统VFS。VFS定义了一组所有文件系统都支持的数据结构的标准接口。这样用户进程空间和内核只需要和VFS交互,而不需要关系各种文件系统底层的实现关系了。
如下图:
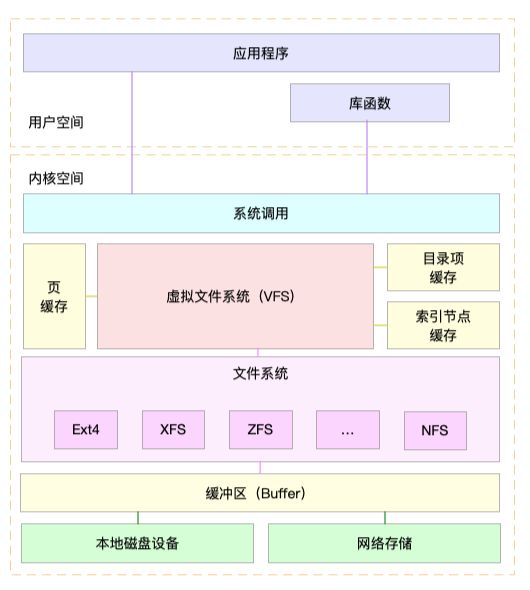
值得注意的是,文件系统不仅仅有基于磁盘的文件系统,还有基于内存的虚拟文件系统,如/proc文件系统,再比如/sys 文件系统。/sys 主要向用户空间导出层次化的内核对象。
在Linux中,磁盘是作为一个块设备来管理的,并且支持随机读写,每块设备会被赋予两个设备号,分别是主设备号和次设备号。主设备号用在驱动程序中,用来区分设备,而次设备号用来给多个同类设备编号。
通用块层
Linux通过一个通用块层来管理各种不同的设备。它会将文件系统和应用程序发来的I/O请求排队,并通过重新排序、请求合并等方式来提高磁盘的读写效率。
对于I/O请求排序的过程,也就是I/O调度算法,通常Linux支持4种调度算法,分别是NONE,NOOP,CFQ以及DeadLine。
这里不做详细的介绍。只是简单提一下。
- NONE 不做任何I/O调度,通常在虚拟机中,此时的磁盘I/O交给宿主机负责。
- NOOP 先入先出队列,只做一些简单的请求合并。
- CFQ 完全公平调度器。为每一个进程都维护一个I/O调度队列。并按事件片来均匀分布每一个进程的I/O请求。(最适合运行大量进程的系统)
- DeadLine 分别为读、写请求创建了不同的I/O队列。多用在I/O压力比较重的场景,如日志归集,数据库服务器。
Linux的I/O
Linux的I/O栈就是由 文件系统,通用块和设备层组成了。
小结一下。
- 文件系统层:包括虚拟文件系统和其他各种文件系统的实现。它为上层的应用程序提供标准的访问接口。对下层通过通用块层来存储和管理磁盘数据。
- 通用块层: 管理块设备I/O队列和I/O调度器。会对文件系统传过来的I/O 请求进行排队,再重新组合排序,发给下一层的设备层。
- 设备层:负责最终的物理设备的I/O操作。
磁盘的性能指标
最常见的指标有五种。分别是使用率,饱和度,IOPS,吞吐量以及响应时间。
- 使用率:是指磁盘处理I/O的时间百分比。一般超过80%就意味着磁盘性能瓶颈了。
- 饱和度:是指磁盘处理I/O的繁忙程度。当饱和度为100%时,磁盘无法再接受新的I/O请求。
- IOPS :每秒的I/O请求数。
- 吞吐量:每秒的I/O请求大小。
- 响应时间:是指I/O请求从发出到收到响应的间隔时间。
例如在数据库,大量小文件等这种随机读写比较多的场景,IOPS可以更好反映出系统的整体性能。而多媒体等顺序读写较多的场景中,吞吐量才是重点。
磁盘I/O状态查看工具
iostat
[root@vm1 ~] # iostat -d -x 1
Linux 3.10.0-957.el7.x86_64 (vm.oom-killer.org) 2019年04月07日 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.01 0.16 0.16 6.50 2.47 56.73 0.00 6.26 11.91 0.53 2.75 0.09
dm-0 0.00 0.00 0.13 0.17 5.29 2.39 51.92 0.00 6.50 14.24 0.55 2.91 0.09
dm-1 0.00 0.00 0.00 0.00 0.09 0.00 54.67 0.00 0.62 0.62 0.00 0.52 0.00
指标的含义:
- r/s:每秒的读请求。
- w/s:每秒的写请求。
- rkB/s:每秒从磁盘读取的数据量。单位KB。
- wkB/s:每秒往磁盘写入的数据量。单位KB。
- rrqm?s:每秒合并的读请求数。
- wrqm/s:每秒合并的写请求书。
- r_await:读请求处理完成等待时间。
- w_await:写请求处理完成等待时间。
- avgqu-sz:平均请求队列长度。
- rareq-sz:平均读请求大小。
- wareq-sz:平均写请求大小。
- svctm:处理I/O请求所需的平均时间。
- %util:磁盘处理I/O的时间百分比。
上述指标中:
1 . %util 是磁盘I/O的使用率。
2 . r/s + w/s 是IOPS
3 . rkB/s + wkB/s 是吞吐量
4 . r_await + w_await 是响应时间
实际案例
-定位MySQL的慢查询原因
这里的模拟场景是mysql查询慢。相关的例子在 geektime 中有。
初始化完数据库后,并插入了10000条数据。在mysql中如何定位一个慢查询。
1.pidstat -d 1 来确认哪个进程在大量的磁盘操作
$ pidstat -d 1
平均时间: UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
平均时间: 0 6821 1.00 1.00 0.00 rsyslogd
平均时间: 0 15143 1930.17 0.00 0.00 bash
平均时间: 0 16438 0.00 2.00 0.00 dockerd
平均时间: 999 16782 216598.50 0.00 0.00 mysqld
平均时间: 0 17100 2.00 1.00 0.00 python
平均时间: 0 17525 1922.19 0.00 0.00 curl
这里可以看到是mysqld 进程一直在读磁盘请求。
追踪mysql可以看到读的文件都为/var/lib/mysql/test/products.MYD 。这是MYD文件,是MyISAM引擎来储存表数据的文件,而文件名就是数据表的名字,文件是数据库的名字。(这里需要强调以下,当使用strace的时候,对应用程序的消耗很大,所以强烈推荐perf trace)
$ perf trace -p 16782
766.518 ( 0.038 ms): mysqld/17277 read(fd: 40, buf: 0x7f2180300ab0, count: 131072) = 131072
766.574 ( 0.012 ms): mysqld/17277 read(fd: 40, buf: 0x7f2184033178, count: 24576) = 24576
766.591 ( 0.037 ms): mysqld/17277 read(fd: 40, buf: 0x7f2180300ab0, count: 131072) = 131072
766.645 ( 0.013 ms): mysqld/17277 read(fd: 40, buf: 0x7f21840338f4, count: 20480) = 20480
766.664 ( 0.037 ms): mysqld/17277 read(fd: 40, buf: 0x7f2180300ab0, count: 131072) = 131072
766.719 ( 0.012 ms): mysqld/17277 read(fd: 40, buf: 0x7f2184033070, count: 24576) = 24576
看下mysql中正在执行的命令。
mysql> show full processlist;
+-----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+-----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
| 766 | root | localhost | NULL | Query | 0 | init | show full processlist |
| 792 | root | 127.0.0.1:43134 | test | Query | 0 | Sending data | select * from products where productName='geektime' |
+-----+------+-----------------+------+---------+------+--------------+-----------------------------------------------------+
这是一个十分简单的查询语句,慢查询的问题应该是没有利用好索引导致的。
mysql> explain select * from products where productName='geektime';
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
| 1 | SIMPLE | products | ALL | NULL | NULL | NULL | NULL | 10000 | Using where |
+----+-------------+----------+------+---------------+------+---------+------+-------+-------------+
1 row in set (0.01 sec)
可以看到,这里的select_type 是简单类型的不包括子查询和UNION,type是全表查询,而不是索引查询(index)。possible_keys 可能选用的索引也是空,key 确切使用的索引更是空了。
那就手动创建索引吧。
mysql> create index products_index on products (productName(64));
Query OK, 10000 rows affected (2.99 sec)
Records: 10000 Duplicates: 0 Warnings: 0
之后再观察下查询的速度,能快几个量级。从400ms缩短到4ms
Got data: () in 0.42174482345581055 sec
Got data: () in 0.03160667419433594 sec
Got data: () in 0.0020470619201660156 sec
Got data: () in 0.004390239715576172 sec
除了缓存外,需要知道MyISAM的引擎,是使用操作系统缓存的,所以 buffer/cache 也是十分重要的。
- redis 的响应慢
redis 响应慢的案例同样来自geektime。首先搭建好环境,发起curl操作,然后发现响应比较慢。查看io发现有大量的读操作。
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 1592.00 0.00 4032.00 5.07 0.22 0.14 0.00 0.14 0.14 22.00
dm-0 0.00 0.00 0.00 1592.00 0.00 4032.00 5.07 0.22 0.14 0.00 0.14 0.14 22.00
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
通过perf trace发现。这里有很多的epoll_pwait read write fdatasync 的系统调用,上面观察到的写磁盘就是write或者fdatasync导致的了。
3406.417 ( 0.055 ms): redis-server/21462 write(fd: 8, buf: 0x7f146a5d8fd4, count: 10 ) = 10
3406.504 ( 0.200 ms): redis-server/21462 epoll_pwait(epfd: 5, events: 0x7f146a5ab000, maxevents: 10128, timeout: 12, sigsetsize: 8) = 1
3406.733 ( 0.011 ms): redis-server/21462 read(fd: 8, buf: 0x7f146a5de9c5, count: 16384 ) = 67
3406.771 ( 0.006 ms): redis-server/21462 read(fd: 3, buf: 0x7ffeb6f4ce97, count: 1 ) = -1 EAGAIN Resource temporarily unavailable
3406.783 ( 0.027 ms): redis-server/21462 write(fd: 7, buf: 0x7f146a498463, count: 67 ) = 67
3406.818 ( 0.446 ms): redis-server/21462 fdatasync(fd: 7
观察得知 写的文件为 /data/appendonly.aof ,相应的系统调用包括 write 和 fdatasync。
这里就要引出redis持久化配置中的 appendonly和appendfsync选项了
$ docker exec -it redis redis-cli config get 'append*'
1) "appendfsync"
2) "always"
3) "appendonly"
4) "yes"
redis 提供了两种数据持久化的方法,快照和追加文件。
- 快照方式:会按照指定的时间间隔,生成数据的快照,并且保存到磁盘文件中,为避免阻塞主进程,redis会fork出一个子进程,来负责快照的保存。
优点:性能好
缺点:数据量大的话,fork子进程需要比较大的内存,保存数据也很耗时。 - 追加文件:在文件末尾追加记录的方式,对redis写入数据,依次进行持久化。 但追加至磁盘中,具体方法有三种,1.always:每个操作都调用一次 fsync 。2.everysec:每秒钟调用一次fsync。3.no:交给操作系统来处理。
好了。现在就知道为什么有I/O的这么大量的写请求了。
$ perf trace -e fdatasync -p 21462 --tool_stats -T
? ( ? ): redis-server/21462 ... [continued]: fdatasync()) = 0
10202644.113 ( 0.455 ms): redis-server/21462 fdatasync(fd: 17 ) = 0
10202646.585 ( 0.448 ms): redis-server/21462 fdatasync(fd: 17 ) = 0
10202647.667 ( 0.535 ms): redis-server/21462 fdatasync(fd: 17 ) = 0
10202649.237 ( 0.425 ms): redis-server/21462 fdatasync(fd: 17 ) = 0