BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库。
软件:python 3.6 、beautifulsoup 4.6.0 、lxml 4.2.1
参考:Beautiful Soup 4.2.0 文档
安装
pip install beautifulsoup4
导入
BeautifulSoup已被移植到bs4
from bs4 import BeautifulSoup
使用
BeautifulSoup对象实例化
可以传入.html文件,一段字符串,或者由网络请求下来的html文档。
BeautifulSoup自动将输入的文档转换为Unicode编码,输出文档转换为utf-8编码。
soup = BeautifulSoup('abc','lxml')
soup = BeautifulSoup(open("index.html"))
url = 'http://www.seputu.com/'
html = urlopen(url).read().decode('utf-8')
soup = BeautifulSoup(html,'lxml')
解析器
BeautifulSoup支持python标准库中的HTML解析器,也支持第三方的解析器,推荐使用lxml效率更高

安装lxml
1.去网站下载lxml,找到对应的版本 http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
2.打开cmd到下载文件对应位置使用,pip install lxml-4.2.2-cp36-cp36m-win_amd64.whl 进行安装。
HTML DOM
在介绍BeautifulSoup工作原理前可以先了解一下HTML DOM。HTML DOM是HTML文档对象模型,浏览器接受服务器发送过来的HTML文档,将其转化为HTML DOM。HTML DOM定义了访问和操作HTML文档的标准,就是关于如何获取、修改、添加或删除HTML元素的标准。
在HTML DOM中HTML文档中的所有内容都是节点,整个文档是一个文档节点;每个HTML元素时元素节点;HTML元素内的文本是文本节点;每个HTML属性是属性节点;注释是注释节点。
HTML 节点树


父、子、同胞节点
节点树中的节点彼此拥有层级关系,父节点拥有子节点,同级的子节点称为同胞节点。
节点树中顶端节点为根节点,除根节点之外每个节点都有父节点。
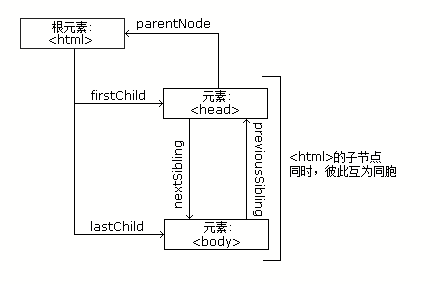
BeautifulSoup对象类型
BeautifulSoup类似于HTML DOM,将复杂的html文档转换成一个复杂的树形结构,每个节点都是python对象,Tag,NavigableString,BeautifulSoup,Comment。
Tag对象
Tag对象与XML或HTML文档中的标签相同,一个标签节点就是一个Tag对象。下面来说说Tag中的name、Attributes、多值属性。




NavigableString可遍历字符串
BeautifulSoup提取的HTML文档中包含在标签内的文本节点的对象类型为NavigableString。
一个NavigableString字符串与python中的Unicode字符串支持的操作相同,可遍历循环。

BeautifulSoup
BeautifulSoup对象代表整个HTML文档。可当做是一个特殊的Tag对象,可以获取类型、名称、及属性。

comment
Comment对象是一个特殊类型的NavigableString对象,指标签中的注释

abspath = os.path.join(os.path.abspath('.'),'t.html')
with open(abspath,'r') as f:
html = f.read()
soup = BeautifulSoup(html,'lxml')
print(soup.ul.contents,end='')
'''
以列表形式返回第一个ul标签下的所有子节点。
['\n', one ,
'\n', two ,
'\n', three ,
'\n', four ,
'\n', five ,
'\n', six ,
'\n']
'''
i = 0
for item in soup.ul.children:
i += 1
print(i,item,end='')
'''
遍历第一个ul下的子节点
1
2 one 3
4 two 5
6 three 7
8 four 9
10 five 11
12 six 13
'''
for item in soup.ul.descendants:
i += 1
print(i,item,end='')
'''
遍历第一个ul下的所有子孙节点
1
2 one 3 one4 one5
6 two 7 two8 two9
10 three 11 three12 three13
14 four 15 four16 four17
18 five 19 five20 five21
22 six 23 six24 six25
'''
for item in soup.ul.strings:
i += 1
print(i,item,end='')
'''
遍历第一个ul下的所有文本子节点
1
2 one3
4 two5
6 three7
8 four9
10 five11
12 six13
'''
for item in soup.ul.stripped_strings:
i += 1
print(i,item,end='')
'''
遍历第一个ul下的所有文本子节点,去除所有空格、空行
1 one2 two3 three4 four5 five6 six
'''