Android内存优化3 了解java GC 垃圾回收机制1
开篇废话
如果我们想要进行内存优化的工作,还是需要了解一下,但这一块的知识属于纯理论的,有可能看起来会有点枯燥,我尽量把这一篇的内容按照一定的逻辑来走一遍。首先,我们为什么要学习垃圾回收的机制,我大概归纳了一下几点:
1.方便我们理解什么样的对象,什么时候,会被系统回收掉
2.有助于我们后面的内存优化
3.了解这一块的知识也能提升自己的知识广度,和同事一起装逼的时候有话题
4.如果有面试的需求的话,了解这一块,也能从容面对考官,对于内存回收能够说出个一二
好了,废话不多说了,我大概按以下这个逻辑来一个一个讲述:
1.什么是垃圾回收(GC)
2.垃圾回收机制对于我们来说有什么好处?又有什么缺点?
3.垃圾回收它是如何工作的?
技术详情
1.什么是垃圾回收(GC)
垃圾回收或GC(Garbage Collection),是一种自动的存储管理机制,它是Java语言的一大特性,方便了我们这些程序员编码,把内存释放工作的压力都转让到了系统,故而是以消耗系统性能为代价的。C++编码的时候,我们 需要自己实现析构函数来进行内存释放,很麻烦,而且非常容易遗漏而最终导致程序崩掉。所以Java语言就引入了自动内存管理的机制,也就是垃圾回收机制,针对的主要的内存的堆区域,关于内存的分配机制,请查看我的上一篇Android性能调优篇之探索JVM内存分配
2.垃圾回收机制对于我们来说有什么好处?又会带来哪些坑?
以下我列举一下系统自动垃圾回收给我们带来的一些好处:
1.让作为程序员的我们专注于逻辑实现,提高了我们的编码效率
2.能够保护程序的完整性,垃圾回收是Java语言的安全策略的一个重要部分
但是随之的,也会到来一些缺点:
1.系统层面负责垃圾回收,明显会加大系统资源的开销,从而影响程序的性能
2.垃圾回收机制也存在不完备性,并不能百分百保证回收所有的垃圾内存
3.垃圾回收它是如何工作的?
其实,GC是主要的一个流程是:先根据一定的算法判定某个对象是否存活,然后把判定是垃圾的对象进行回收。详细点说的话,GC的工作流程分以下几个步骤:
1.可回收对象的判定
2.通过某些算法回收垃圾内存
下面一个一个进行讲述
1.可回收对象的判定
我们的GC需要把某个对象回收掉,肯定是需要判断它到底是不是垃圾,是不是需要被回收,因此,就需要对每一个对象进行可回收判定。
目前,市面上存在有两种算法来判定一个对象是否是垃圾
1.引用计数算法
这种算法的工作原理是:
1.首先给每一个对象都添加一个引用计数器
2.当程序的某一个地方引用了此对象,这个计数器的值就加1
3.当引用失效的时候(例如超过了作用域),这个计数器就减1
4.当某一个对象的计数器的值是0的时候,则判定这个对象不可能被使用
这种算法对于系统来说比较简单,高效,垃圾回收器运行较快,不需要长时间中断我们的程序的执行,但是缺点是很难处理循环引用,这就导致相互引用的对象都无法被回收:
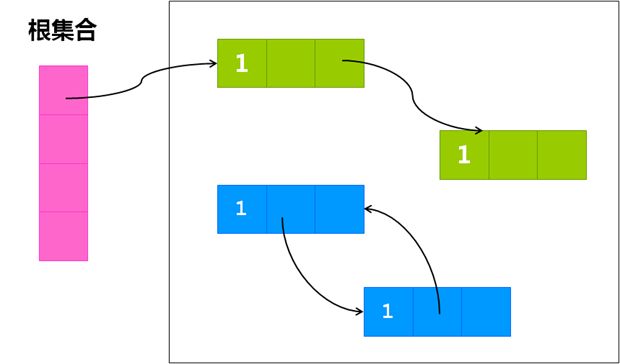
我记得OC(Objective-C)中的垃圾判定就是用的引用计数方法,引用了一个第三方变量来打破这个平衡,但OC也没有很好的解决这个问题,而是更多的依靠我们这些开发者来处理。
2.GC Root可达性分析算法
这个算法的工作原理是:
1.以称作“GC Root”的对象作为起点向下搜索
2.每走过一个对象,就生成一条引用链
3.从根开始到搜索完,生成了一棵引用树,那些到GC Root不可达的对象就是可以回收的
这个方法明显就解决了循环引用的问题,不过这个算法还是稍微有点复杂的,以下是GC Root可达性算法的一个图解:

我们程序中能够被用来当做GC Root对象的有:
1.虚拟机栈(栈帧中的本地变量表)中引用的对象
2.方法区中静态属性引用的对象
3.方法区中常量引用的对象
4.本地方法栈中JNI引用的对象
以下拿一个图来进行引用计数算法与可达性分析算法的比较:
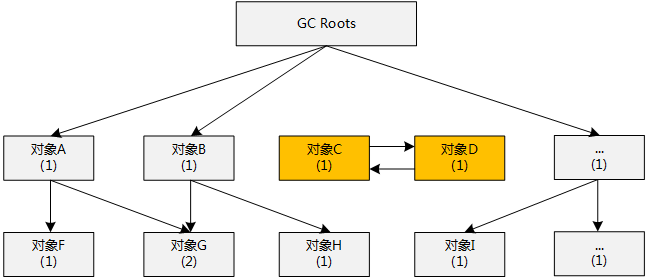
文字说明:
1.若使用引用计数算法判定,但图中的C和D对象存在相互引用,导致计数器不为0,无法回收掉
2.若使用可达性分析算法,C和D对象到GC Roots 不可达,则能够回收
关于对象可回收的判定,我们还需要注意的是,当系统开始启动GC的时候,为了保证引用链的状态不变,就需要停止该进程中所有的程序(Stop The World),我们Android中的现象就是UI卡顿了,但一般这样的卡顿时间是非常短的,当然,要是频繁的产生GC,那就另当别论了。
还有值得注意的是,不可达对象也并非立即就被回收了,还需要经过两次的标记过程后才被会被真正回收:
1.如果对象与GC Root没有连接的引用链,就会被第一次标记,随后判定该对象是否有必要执行finalize()方法
2.如果有必要执行finalize()方法,则这个对象就会被放到F-Queue的队列中,稍后由虚
拟机建立低优先级的Finalizer线程去执行,但并不承诺等待它运行结束(对象类中能够
重写finalize()方法进行自救,但系统最多只能执行一次)
3.如果没必要执行finalize()方法,则第二次标记
2.通过某些算法回收垃圾内存
以上内容讲述了系统如何去判定某一个对象是否是垃圾,是否应该被回收。接着,当判定了某一个对象为垃圾对象后,系统就要开始进行回收了,那么系统的垃圾回收算法以下几种:
1.标记清除算法(Mark-Sweep)
2.复制算法(Copying)
3.标记整理算法(Mark-Compact)
4.分代回收算法
以下进行一一讲述
1.标记清除算法(Mark-Sweep)
顾名思义,这个算法是先进行标记,然后进行清除,也正是这个算法的两个阶段:标记阶段和清除阶段,以下图解:

从图中可以看出:
这个算法的优点是易于理解,容易实现,只需要将特定地址的空间进行处理。
但缺点也比较明显,把整个内存区域弄得非常不完整,形成了很多碎片化的内存,对于
分配大内存的对象时,无法申请足够的空间,从而更多次的触发GC
2.复制算法(Copying)
复制算法,是对标记清除算法而导致内存碎片化的一个解决方案,算法原理如下:
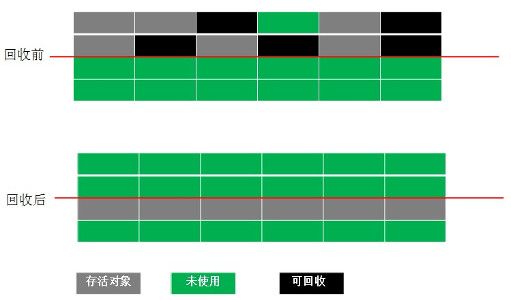
1.如图所示,复制算法将内存平均分成两个区域A (上)和 B(下)
2.将A中的存活的那些对象复制到B区域中
3.然后将A区域的所有对象都清除,这样A区域就是一个完整的内存块了,也就避免了内
存碎片化了
但是这个算法也有明显的缺点,那就是不管A区域或B区域有多少个存活对象,都需要将整块内存分成两个区域,意味着能够真正使用的内存变成了一半。
3.标记整理算法(Mark-Compact)
标记整理算法是对于标记清楚的一个优化,工作原理是:
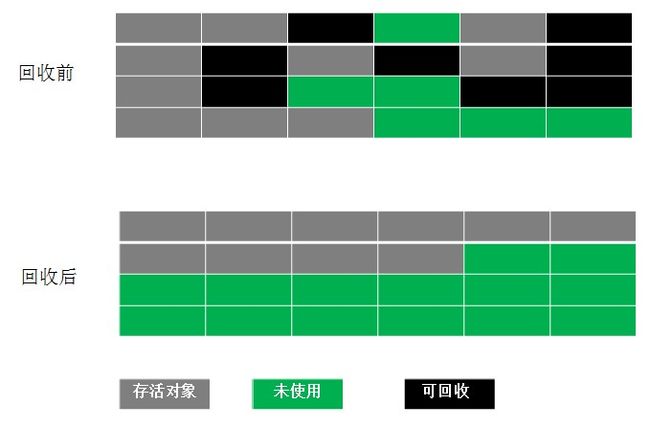
1.如图所示,第一步也需要进行存活对象的一个标记,这一步与标记清除算法一模一样
2.将存活的对象向一端移动,例如图中是往左上角那一端进行移动
3.然后把另一端的内存进行清理
从图中也可以看出,这个算法也能避免内存碎片化的问题,但是效率确实不怎么样,毕竟相较于复制算法, 多了一步效率同样比较低的标记过程,而与标记清除算法相比,多了一步内存整理(往一端移动)的过程,效率上明显就更低了。
毕竟世界是公平的,任何算法都有两面性,我们开发者只能具体情况具体分析,使用最适合的算法。因此标记整理算法从图中可以看出,这个算法适合存活对象多的,回收对象少的情况。
4.分代回收算法
鉴于以上三种算法都存在自己的缺陷,然后大神们就提出了根据不同对象的不同特性,使用不同的算法进行处理,所以严格来讲并不是一个新的算法,而是属于一种算法整合方案,我们知道:
1.复制算法适用于存活对象少,回收对象多的情况
2.标记整理算法适用于存活对象多,回收对象少的情况
这两种算法刚好互补,因此只要将这两个算法作用于不同特性的对象,就完美了。。
那么我们就应该知道,哪个区域的对象是什么样的特性,根据我的上一篇的内存分配模型,堆内存中的新生代有很多的垃圾需要回收,老年代有很少的垃圾需要回收,那么刚好能够根据这个特点使用不同的算法进行回收,具体使用的方式为:
1.对于新生代区域采用复制算法,因为新生代中每次垃圾回收都要回收大部分对象,那么也就意味着复制次数比较少,因此采用复制算法更高效
2.而老年代区域的特点是每次回收都只能回收很少的对象,一般使用的是标记整理或者标记清除算法
通过以上的方式,使得GC的整个过程达到了最高效的状态。
这里需要注意的是分代回收算法的中的复制算法的使用。
之前说的复制算法是将内存均分为二,但是在分代回收中,并不是这样,而是根据Eden:Survivor A:Survivor B= 8:1:1,具体的过程是(简化版):
1.新创建一个对象,默认是分在Eden区域,当Eden区域内存不够的时候,会触发一次Min
or GC(新生代回收),这次回收将存活的对象放到Survivor A区域,然后新的对象继续放在Eden区域
2.再创建一个新的对象,要是Eden区域又不够了,再次触发Minor GC,这个时候会把Eden区域的存活对象以及
Survivor A区域的存活的对象移动到Survivor B区域,然后清空Eden区域以及Survivor A区域
3.如果继续有新的对象创建,不断触发Minor GC,有些对象就会不断在Survivor A区域以及Survivor B区域
来回移动,但移动次数超过15次后,这些对象就会被移动到老年代区域
4.如果新的对象在Minor GC后还是放不下,就直接放到老年代
5.如果Survivor区域放不下该对象,这直接放到老年代
6.如果老年代也满了,就会触发一次Full GC(major gc)
干货总结
通过以上的讲述,我们了解了什么是GC,它的优缺点,它是如何工作的,整过过程下来,脑子里也算有了一个GC的概率模型在了。
本文参考了以下博客:
理解Android Java垃圾回收机制
JAVA垃圾回收机制
掌握好GC策略和原理,对于我们编码来说能够避免一些不必要的内存泄露,我们使用Java语言进行开发,不要一味的去追求各种牛逼的框架或者酷炫的业务实现,有的时候,还是需要我们沉下心来,好好了解一下底层系统的一些机制,个人觉得还是很有必要的。
本文转自 一点点征服 博客园博客,原文链接:http://www.cnblogs.com/ldq2016/p/8469853.html,如需转载请自行联系原作者