JetsonTX2--环境安装合集
JetsonTX2--环境安装合集
- Jetson Tx2简介
- 刷机并且装Jetpack3.3
- Jetson TX2国内源
- TX2几种工作模式
- TX2扩充硬盘
- 更换挂载TF卡
- 方案一
- 方案二
- ubuntu增加swap
- CUDA版本之间的切换
- 查看opencv版本号
- 查看Eigen3版本
- 查看jetson系列的GPU和CPU等参数使用情况
- jetpack3.3安装pytorch
- 升级到Pyrhon3.6*
Jetson Tx2简介
TX2大体配置如下

本人想用于跑视觉slam算法,在一系列的开源算法实例中,发现性能上并不是十分满意,ORBslam2大概帧率是10fps左右,手持可能可以实现,如果放置无人机有些吃力。Vins-FUsion会比ORBSLAM2好一些。具体寒没有放置实物上测试,后期再补充。
该板子加入了GPU,所以用于深度学习可能更适合
板子的开发套件是很大的,但是核心模块是可以拆卸下来配套载板使用,我使用的载板是9003U(瑞泰科技),主要这个载板也不便宜,一千多块钱。但是瑞泰科技做这种英伟达的载板比较权威,资料也比较多。这样核心板+风扇+载板大概是银行卡的大小,200多g。适合放在无人机上
刷机并且装Jetpack3.3
根据瑞泰科技提供的刷机资料,可以一步一步进行,比较相信,坑也少。可参考
对一些细节做下总结
TX2安装ubuntu16.04
以为载板是第三方的,开发版自带的系统其实也可以在载板上面用,但是只能使用一个USB口(因为开发板上就只有一个)所以需要装载板修改后的系统才可以用载板上的两个USB口(系统其它大部分和官方系统一致)
1、首先下载的数据包相互之间版本一定要对应上,每一种数据包都对应着固定的版本不能随意。我这里安装的版本是28.2.1,那么之后对应的jetpack版本是3.3 版本对应查找
2、在数据包等按照提供的教程准备好了之后就是刷入TX2的recovery状态。
- 拔下板子的供电
- usb线将板子(type b口)和host主机(USB口)进行连接
- 重新给板子供电
- 按住载板的recovery键,同时按下reset并松开(让TX2重新启动),2s后松开recovery键
- 在host主机中lsusb看到nvidia crop的话证明成功进入recovery状态
- 进行之后的步骤
安装Jetpack
3、在主机上下载Jetpack包,最终是通过数据线对TX2进行安装。安装的Jetpack版本要与刷入的系统版本是一致的,我安装的是R28.2.1对应Jetpack3.3。下载中心
4、在安装界面中会有一个软件包选择的步骤。注意我们前面已经给TX2装过系统了,所以Linux for Tegra Host Side Image是no action.还有就是如果不需要也在host主机重安装cuda等软件,那么Host Ubuntu也是no action。那么最后也就只选择instal on Tegra部分
5、在输入nvidia的ip时,怎么查找ip也是个问题,一般的网上给出的命令行查找方法得出的ip不匹配。所以在直接通过nvdia桌面右上角网路连接处点击Connection Information打开界面,找到带有(default)的那个窗口下的ip
6、测试cuda是否安装成功 ,执行命令 nvcc -V 会得到cuda版本信息或则进行安装的sample做测试(我用sample测试没能成功)
放上外国网友刷机视频
Jetson TX2国内源
arm64的源和pc源是有区别的,在进行TX2环境搭建之前最好换上国内源,这样下载速度会变快很多,下面给出两种源,只需要把其中一种放入source.list文件中即可(发现同时放入两种源效果并不是有啥好处,甚至该巨额会慢,希望是感觉错误)
清华源
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-updates main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-security main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-security main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial-backports main restricted universe multiverse
deb http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial main universe restricted
deb-src http://mirrors.tuna.tsinghua.edu.cn/ubuntu-ports/ xenial main universe restricted
科大源
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-security main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial-backports main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial main universe restricted
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ xenial main universe restricted
本人用的是清华源,感觉不错。放入源后要更新
sudo apt-get update
小补充:一般情况下如要安装一些依赖或者软件,如提示无法定位软件包的,一般情况下是当前源下没有找到对应的包,因此需要添加额外的源
TX2几种工作模式
 X2由一个GPU和一个CPU集群组成,CPU集群由双核丹佛2(Denver 2)和4核ARM A57组成
X2由一个GPU和一个CPU集群组成,CPU集群由双核丹佛2(Denver 2)和4核ARM A57组成
共5种模式,有的小伙伴可能刚看的时候不太明白,我来稍微讲一下,模式1,是TX2的默认模式,此模式丹佛2cpu不运行(模式1 Denver2下数字为0 ),ARM A57运行(数字为4,4核),ARM A57频率为1.2Ghz,GPU频率0.85G,模式0为性能最大的模式,此种情况下丹佛2处理器(双核,因此数字为2)和ARM A57均运行,丹佛2频率为2Ghz,ARM A57频率为1.2Ghz,GPU频率1.3G。其他模式以此类推。
查询当前工作模式,输入
sudo nvpmodel -q verbose
修改工作模式为0,输入
sudo nvpmodel -m 0
改变模式时候,可以通过指令cat /proc/cpuinfo查询运行状态
直接运行home下的jetson_clocks.sh,开启最大频率
sudo ~/jetson_clocks.sh (风扇转动)
原文链接:https://blog.csdn.net/qq_35239859/article/details/79825341
TX2扩充硬盘
由于TX2内置了32G的硬盘,但是一般情况安装完环境之后所剩无几,所以选择外加一个硬盘进去,我这里是通过TF卡对它内存的进行扩充,这里的扩充只能说是直接创建一个目录作为新增磁盘的访问索引,这个目录可以和系统中的任何一个已存在的目录同名,最终就是用新创建的目录替代久的同名目录,这样就改变了存储路径。
步骤如下
1.查看硬盘所有分区。
指令:
sudo fdisk -lu
会有一个/dev/mmcblk1p1就是你所接入的硬盘
2、对硬盘进行分区。
指令:
sudo fdisk /dev/mmcblk1
(如果硬盘之前存在过分区,并且内存已经被分完,那么需要输入d进行分区删除才可继续下面步骤)
在Command (m for help)提示符后面输入n,执行 add a new partition 指令给硬盘增加新分区。
出现Partition number(1-4)时,输入1表示只分一个区。(所加硬盘比较大的话可以多分几个)
后续指定起启柱面(First sector),默认起始地址为 2048,结束地址为:1953525167,不输入数字按ENTER,将填入默认值。
在Command (m for help)提示符后面输入w,保存分区表。(必须要执行w保存操作,要不然退出指令就失效了)
输入quit退出
再次输入指令:sudo fdisk /dev/mmcblk1
显示/dev/mmcblk1p1 则表示分区完成
3、格式化分区为ext4
(格式化之前要确保该硬盘之前没有进行过挂载操作,如果有则先用sudo umount sudo fdisk /dev/mmcblk1指令进行卸载磁盘挂载记录,否则格式化不成功)
(必须进行各个格式的格式化才可以完成后续的挂载命令,否则会出错)
指令:sudo mkfs -t ext4 /dev/mmcblk1p1
4、挂载硬盘分区
先把新硬盘挂在一个临时目录下
cd /mnt/
sudo mkdir home
sudo mount /dev/sda1 /mnt/home //挂载到/mnt/home
df -h //查看
sudo cp -a /home/* /mnt/home/ //其中*号的意思是把home下的东西拷到挂载的目录下,备份*/
5、设置开机挂载(修改文件)
sudo vi /etc/fstab
//末尾增加一行
/dev/mmcblk1p1 /home ext4 defaults 1 2 //这一步是让/dev/mmcblk1p1 分区挂载到旧目录(/home)
//保存退出
//为了保险一点,先进行fstab文件的编写,在进行久home磁盘文件的删除
sudo rm -rf /home/* //其中*号的意思是把home下的东西删干净*/
sudo umount /dev/mmcblk1p1 // 卸载硬盘
//这一步可能会出现桌面图标消失的情况
df -h //查看 /home是否被挂载
mount -a //挂载/etc/fstab 中未挂载的分区
df -h //查看
//最后在home目录下
ls
//能够出现全部文件时,说明系统已经能够正常访问修改后的路径
//重启
reboot
特别注意::
在挂载usr目录的时候一定要先进行备份,因为usr目录存放的东西可以说是非常重要的,已丢失路径就会出现系统用不了,指令用不了的情况,甚至需要重新刷机。出现过一次崩溃,之后没敢再试着挂载usr目录。
该教程参考这篇博客,其中自己添加了一些细节
更换挂载TF卡
上一步是在没有外扩的基础上进行的,所以直接将内嵌的文件转移到外扩的硬盘上,但是当外扩硬盘再次需要更换各大的硬盘时那么这时候就需要改变挂载路径。
需要注意几点
- 例如TX2的TF卡卡槽插入的识别的设备名称是固定的(不管插入什么样的卡,都是一样的名称),这样不可能通过USB先进性新硬盘的挂载再转移到自带的TF卡槽上去(名字发生了改变,无法访问)
- 直接弹出旧版本的扩充硬盘的话,只要之前不是挂载重要的目录(如usr等目录),挂载的是home目录的话,不会对系统造成大影响,但是在弹出之前要先把该硬盘进行umount处理,并修改或注释/etc/fstab文件,直接手动弹出会造成系统挂载状态不变,但是读取不到硬盘的情况,重新启动的话会需要等待1分30秒的开机,系统会重新在系统盘中恢复最初装机时候的home目录,但是挂载状态还保留着,这样很不好,防止出错,所以还是先umount再手动弹出
- 在进行旧硬盘向新硬盘拷贝的时候,新硬盘应定要先格式化成固定格式 ext4 ,否则无法进行挂载,严格按照上一教程进行
- 通过USB口也可以实现硬盘挂载,只是USB口识别的设备名称和自带TF卡槽有区别。两者不能随意切换
方案一
通过USB口将新硬盘进行分区,格式化,再将旧硬盘的内容cp到新硬盘的某一分区内,分别对新旧硬盘进行卸载(umount)之后把新硬盘放置TF卡槽,在进行挂载(mount)
新硬盘操作:
USB口读取
上一教程( TX2扩充硬盘)第1—4步;注意磁盘名称不一样,要该成相应名称
执行完毕之后,对旧硬盘进行卸载
sudo umount /dev/mmcblk1p1
修改文件
sudo vi /etc/fstab
//末尾注释一行
/dev/mmcblk1p1 /home ext4 defaults 1 2 //这一步是让/dev/mmcblk1p1 分区挂载到旧目录(/home)
//保存退出
把新硬盘转移到TF卡槽
继续操作
sudo vi /etc/fstab
//末尾增加一行
/dev/mmcblk1p1 /home ext4 defaults 1 2 //这一步是让/dev/mmcblk1p1 分区挂载到旧目录(/home)
//保存退出
df -h //查看 /home是否被挂载
mount -a //挂载/etc/fstab 中未挂载的分区
df -h //查看
如果home目录下出现之前文件,且磁盘容量发生相应变化,功能恢复,那么完成了
方案二
将旧磁盘先卸载弹出,再用USB口进行识别,新硬盘直接放入TF卡槽
这时会发现旧硬盘转换到了USB口识别后,识别的名称变了,而新硬盘的识别名称正是旧硬盘之前TF卡槽挂载时的名称
对新卡操作:
TK卡槽读取
执行上一教程( TX2扩充硬盘)第1—5步;注意磁盘名称一样
结论:
两个方案基本上是和上一教程( TX2扩充硬盘)一样的操作,只是注意复制路径的变化就可以了
ubuntu增加swap
参考连接
在TX2或者其它型号的板子上会出现编译过程中虚拟内存不足的情况,这时候需要把硬盘暂时的内存转化成虚拟内存,用完之后删除就可以了。
下面系统极客就为大家介绍,如何为 Ubuntu 18.04 手动创建 SWAP 交换文件。
开始之前
在开始创建之前,请先使用如下命令检查您的 Ubuntu 系统是否已经启用了 SWAP 分区:
sudo swapon --show
如果输出为空,则表示当前系统尚未启用 SWAP 空间;反之,您将看到相关反馈。
虽然可能,但在同一台 Linux 机器上有多个 SWAP 空间的情况并不常见。
创建SWAP分区文件
您可以执行以下步骤在 Ubuntu 18.04 系统中添加 SWAP 交换文件:
1、通过以下命令创建一个用于 swap 的文件:
其中1G表示需要增加的swap内存,可以自行设定,/swapfile是创建的文件名
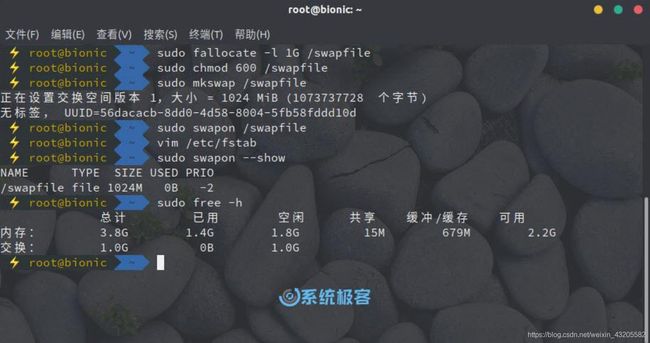
sudo fallocate -l 1G /swapfile
如果未安装 fallocate 或者收到错误提示,也可以使用以下命令创建 swap 文件:
sudo dd if=/dev/zero of=/swapfile bs=1024 count=1048576
2、执行以下命令为 swapfile 文件设置正确的权限:
sudo chmod 600 /swapfile
3、使用 mkswap 实用程序在文件上设置 Linux SWAP 区域:
sudo mkswap /swapfile
4、使用以下命令激活 swap 文件:
sudo swapon /swapfile
注意:下面的5和6是为了永久增加swap空间,如果临时使用可以跳过
5、要让创建好的 swap 分区永久生效,可以将 swapfile 路径内容写入到 /etc/fstab 文件当中:
/swapfile swap swap defaults 0 0
6、使用 swapon 或 free 命令验证 SWAP 是否处于活动状态,如下所示:
sudo swapon --show
sudo free -h
调整Swappiness值
Swappiness 是一个 Linux 内核属性,用于定义 Linux 系统使用 SWAP 空间的频率。Swappiness 值可以从 0 至 100 ,较低的值会让内核尽可能少的使用 SWAP 空间,而较高的值将让 Linux Kernel 能够更加积极地使用 SWAP 分区。Ubuntu 18.04 默认的 Swappiness 值为 60 ,您可以使用如下命令来查看:
cat /proc/sys/vm/swappiness
值为 60 对于 Ubuntu 18.04 桌面还算行,但对于 Ubuntu Server 来说,SWAP 的使用频率就比较高了,所以您可能需要设置较低的值。例如,要将 swappiness 值设置为 40,请执行:
sudo sysctl vm.swappiness=40

如果要让设置在系统重启后依然有效,则必要在 /etc/sysctl.conf 文件中添加以下内容:
vm.swappiness=40
最佳 swappiness 值取决于您系统的工作负载以及内存的使用方式,您应该以小增量的方式来调整此参数,以查到最佳值。
移除SWAP分区
Ubuntu 18.04 要停用并删除 SWAP 文件,请按照下列步骤操作:
1、首先输入以下命令停用 SWAP 空间:
sudo swapoff -v /swapfile
2、在 /etc/fstab 文件中删除有效 swap 的行。
3、最后执行以下命令删除 swapfile 文件:
sudo rm /swapfile
CUDA版本之间的切换
在系统中很可能是同时安装了两个版本的CUDA,其中可以进行切换使用

这里,cuda-9.0和cuda-9.1就是我们安装的两个cuda版本了,而cuda是一个软链接,它指向我们指定的cuda版本(注意上面在设置环境变量时,使用的是cuda,而不是cuda-9.0和cuda-9.1,这主要是为了方便我们切换cuda版本,可以让我们不用每次都去该环境变量的值)
可以使用stat命令查看当前cuda软链接指向的哪个cuda版本,如下所示:
 可以看到,文件类型是symbolic link,而指向的目录正是/usr/local/cuda-9.0,当我们想使用cuda-9.1版本时,只需要删除该软链接,然后重新建立指向cuda-9.1版本的软链接即可(注意名称还是cuda,因为要与bashrc文件里设置的保持一致)
可以看到,文件类型是symbolic link,而指向的目录正是/usr/local/cuda-9.0,当我们想使用cuda-9.1版本时,只需要删除该软链接,然后重新建立指向cuda-9.1版本的软链接即可(注意名称还是cuda,因为要与bashrc文件里设置的保持一致)
sudo rm -rf cuda
sudo ln -s /usr/local/cuda-9.1 /usr/local/cuda
想切换其他版本的cuda,只需要改动建立软链接时cdua的正确路径即可。参考
查看opencv版本号
查看linux下的opencv安装库:
pkg-config opencv --libs

查看linux下的opencv安装版本:
pkg-config opencv --modversion
![]()
查看linux下的opencv安装路径:
sudo find / -iname “opencv”
在全盘上不区分大小写,搜索带有关键字opencv的所有文件及文件夹都会输出到终端,如果输出太长建议输出到txt文件里查看,如下:
sudo find / -iname “opencv” > /home/ubuntu/Desktop/opencv_find.txt

可知opencv安装在/usr/local/lib里面。
原文链接:https://blog.csdn.net/zhenguo26/article/details/79627232
查看Eigen3版本
path
/usr/include/eigen3/Eigen/src/Core/util
文件
Macros.h
#define EIGEN_WORLD_VERSION 3
#define EIGEN_MAJOR_VERSION 2
#define EIGEN_MINOR_VERSION 92
查看jetson系列的GPU和CPU等参数使用情况
参考链接
jetpack3.3安装pytorch
首先进入pytorch的github
里面有对jetson系列的安装有特定的包,但是给出来的是要求是jetpack4.2及以上的版本,这里不用管他。亲测成功

针对当前的python版本,下载对应的包
继续github页面往下有一个安装方法的链接

通过指令进行安装
这里的安装存放的目录在
~/.local/lib/python2.7/site-packages/torch
因此在一些需要torch的cmake工程中要在CMakeLists文件中添加TORCH_PATH
set(TORCH_PATH ~/.local/lib/python2.7/site-packages/torch/share/cmake/Torch)
最终要对Torch_DIR变量进行赋值
下面死编译GCNv2_SLAM的CMakeLists的片段
if( TORCH_PATH )
message("TORCH_PATH set to: ${TORCH_PATH}")
set(Torch_DIR ${TORCH_PATH})
else()
message(FATAL_ERROR "Need to specify Torch path, e.g., pytorch/torch/share/cmake/Torch ")
endif()
find_package(Torch REQUIRED)
但是存在一个问题,通过上面命令直接在jetpack3.3安装的torch版本是依赖与cuda10的以致与在
import torch
会出现以下错误
ImportError: libcudart.so.10.0: cannot open shared object file: No such file or directory
那么就是说需要安装cuda10才能找到相应的库
同样的在编译GCNv2_SLAM时候在最后添加torch库到可执行文件的时候出现类似的找不到10.0库的问题
target_link_libraries(rgbd_gcn ${PROJECT_NAME} ${TORCH_LIBRARIES})
错误如下
/usr/bin/ld: warning: libcudart.so.10.0, needed by /home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so, not found (try using -rpath or -rpath-link)
/usr/bin/ld: warning: libcusparse.so.10.0, needed by /home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so, not found (try using -rpath or -rpath-link)
/usr/bin/ld: warning: libcurand.so.10.0, needed by /home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so, not found (try using -rpath or -rpath-link)
/usr/bin/ld: warning: libcufft.so.10.0, needed by /home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so, not found (try using -rpath or -rpath-link)
/usr/bin/ld: warning: libcublas.so.10.0, needed by /home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so, not found (try using -rpath or -rpath-link)
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `__cxa_init_primary_exception@CXXABI_1.3.11'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
/home/nvidia/.local/lib/python2.7/site-packages/torch/lib/libtorch.so: undefined reference to `[email protected]'
。。。。
因此想要运行GCNv2_SLAM估计的需要安装cuda对应版本的torch,建议直接安装cuda10,因为官网提供的方法就是依赖cuda10的
升级到Pyrhon3.6*
首先通过命令查看当前python3的版本
python3 -V
我的是pyhon3.5
解释一下:其实这里的python3只是对已安装的pyhon某一个版本的软连接,是随时可以改的,其中这软连接可以在目录
/usr/bin
下找到,因此安装新版本的python并不会覆盖到旧版本
安装指令
sudo apt-get install software-properties-common //可以省略
sudo add-apt-repository ppa:jonathonf/python-3.6
sudo apt-get update
sudo apt-get install python3.6
再次輸入python3 -V發現沒有變化還是python3.5,還需要下面步驟
輸入which python3 發現python3 路徑
我的是/usr/bin/python3
cd /usr/bin/
sudo rm python3 刪除原先python3.5
sudo ln -s python3.6 python3 创建软连接
再次輸入 python3 -V
這時候是python3.6