Python Numpy 教程
本教程介绍了Python Numpy库从安装到创建数组的过程:Numpy的数据类型,数组属性
,如何创建Numpy数组等。
文章目录
- Numpy 安装
- 1、使用已有的发行版本
- 2、使用 pip 安装
- Linux (Ubuntu & Debian)下安装
- 安装验证
- NumPy Ndarray 对象
- 实例
- 实例 1
- 实例 2
- 实例 3
- 实例 4
- NumPy 数据类型
- 数据类型对象 (dtype)
- 实例
- 实例 1
- 实例 2
- 实例 3
- 实例 4
- 实例 5
- 实例 6
- 实例 7
- 实例 8
- NumPy 数组属性
- ndarray.ndim
- 实例
- ndarray.shape
- ndarray.itemsize
- 实例
- ndarray.flags
- 实例
- NumPy 创建数组
- numpy.empty
- numpy.zeros
- 实例
- numpy.ones
- 实例
- NumPy 从已有的数组创建数组
- numpy.asarray
- 实例
- 实例
- 实例
- 实例
- numpy.frombuffer
- Python3.x 实例
- Python2.x 实例
- numpy.fromiter
- 实例
- NumPy 从数值范围创建数组
- numpy.arange
- 实例
- numpy.linspace
- numpy.logspace
Numpy 安装
Python 官网上的发行版是不包含 NumPy 模块的。
我们可以使用以下几种方法来安装。
1、使用已有的发行版本
对于许多用户,尤其是在 Windows 上,最简单的方法是下载以下的 Python 发行版,它们包含了所有的关键包(包括 NumPy,SciPy,matplotlib,IPython,SymPy 以及 Python 核心自带的其它包):
- Anaconda: 免费 Python 发行版,用于进行大规模数据处理、预测分析,和科学计算,致力于简化包的管理和部署。支持 Linux, Windows 和 Mac 系统。
- Enthought Canopy: 提供了免费和商业发行版。持 Linux, Windows 和 Mac 系统。
- Python(x,y): 免费的 Python 发行版,包含了完整的 Python 语言开发包 及 Spyder IDE。支持 Windows,仅限 Python 2 版本。
- WinPython: 另一个免费的 Python 发行版,包含科学计算包与 Spyder IDE。支持 Windows。
- Pyzo: 基于 Anaconda 的免费发行版本及 IEP 的交互开发环境,超轻量级。 支持 Linux, Windows 和 Mac 系统。
2、使用 pip 安装
安装 NumPy 最简单的方法就是使用 pip 工具:
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
–user 选项可以设置只安装在当前的用户下,而不是写入到系统目录。
Linux (Ubuntu & Debian)下安装
sudo apt-get install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-nose
安装验证
测试是否安装成功:
>>> from numpy import *
>>> eye(4)
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
from numpy import * 为导入 numpy 库。
eye(4) 生成对角矩阵。
NumPy Ndarray 对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
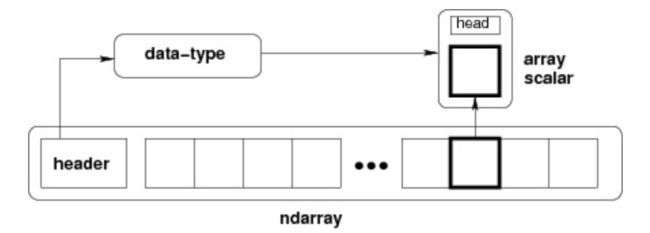
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
参数说明:
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
实例
接下来可以通过以下实例帮助我们更好的理解。
实例 1
import numpy as np
a = np.array([1,2,3])
print (a)
输出结果如下:
[1, 2, 3]
实例 2
# 多于一个维度
import numpy as np
a = np.array([[1, 2], [3, 4]])
print (a)
输出结果如下:
[[1, 2]
[3, 4]]
实例 3
# 最小维度
import numpy as np
a = np.array([1, 2, 3,4,5], ndmin = 2)
print (a)
实例 4
# dtype 参数
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print (a)
输出结果如下:
[ 1.+0.j, 2.+0.j, 3.+0.j]
ndarray 对象由计算机内存的连续一维部分组成,并结合索引模式,将每个元素映射到内存块中的一个位置。内存块以行顺序(C样式)或列顺序(FORTRAN或MatLab风格,即前述的F样式)来保存元素。
NumPy 数据类型
numpy 支持的数据类型比 Python 内置的类型要多很多,基本上可以和 C 语言的数据类型对应上,其中部分类型对应为 Python 内置的类型。下表列举了常用 NumPy 基本类型。
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
数据类型对象 (dtype)
数据类型对象是用来描述与数组对应的内存区域如何使用,这依赖如下几个方面:
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,它的形状和数据类型
字节顺序是通过对数据类型预先设定"<“或”>“来决定的。”<“意味着小端法(最小值存储在最小的地址,即低位组放在最前面)。”>"意味着大端法(最重要的字节存储在最小的地址,即高位组放在最前面)。
dtype 对象是使用以下语法构造的:
numpy.dtype(object, align, copy)
- object - 要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体。
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
实例
接下来我们可以通过实例来理解。
实例 1
import numpy as np
# 使用标量类型
dt = np.dtype(np.int32)
print(dt)
输出结果为:
int32
实例 2
import numpy as np
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
dt = np.dtype('i4')
print(dt)
输出结果为:
int32
实例 3
import numpy as np
# 字节顺序标注
dt = np.dtype('输出结果为:
int32
下面实例展示结构化数据类型的使用,类型字段和对应的实际类型将被创建。
实例 4
# 首先创建结构化数据类型
import numpy as np
dt = np.dtype([('age',np.int8)])
print(dt)
输出结果为:
[('age', 'i1')]
实例 5
# 将数据类型应用于 ndarray 对象
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)
输出结果为:
[(10,) (20,) (30,)]
实例 6
# 类型字段名可以用于存取实际的 age 列
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a['age'])
输出结果为:
[10 20 30]
下面的示例定义一个结构化数据类型 student,包含字符串字段 name,整数字段 age,及浮点字段 marks,并将这个 dtype 应用到 ndarray 对象。
实例 7
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print(student)
输出结果为:
[('name', 'S20'), ('age', 'i1'), ('marks', '实例 8
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
输出结果为:
[('abc', 21, 50.0), ('xyz', 18, 75.0)]
每个内建类型都有一个唯一定义它的字符代码,如下:
| 字符 | 对应类型 |
|---|---|
| b | 布尔型 |
| i | (有符号) 整型 |
| u | 无符号整型 integer |
| f | 浮点型 |
| c | 复数浮点型 |
| m | timedelta(时间间隔) |
| M | datetime(日期时间) |
| O | (Python) 对象 |
| S, a | (byte-)字符串 |
| U | Unicode |
| V | 原始数据 (void) |
NumPy 数组属性
本章节我们将来了解 NumPy 数组的一些基本属性。
NumPy 数组的维数称为秩(rank),一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
ndarray.ndim
ndarray.ndim 用于返回数组的维数,等于秩。
实例
import numpy as np
a = np.arange(24)
print (a.ndim) # a 现只有一个维度
# 现在调整其大小
b = a.reshape(2,4,3) # b 现在拥有三个维度
print (b.ndim)
输出结果为:
1
3
ndarray.shape
ndarray.shape 表示数组的维度,返回一个元组,这个元组的长度就是维度的数目,即 ndim 属性(秩)。比如,一个二维数组,其维度表示"行数"和"列数"。
ndarray.shape 也可以用于调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print (a.shape)
输出结果为:
(2, 3)
调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
a.shape = (3,2)
print (a)
输出结果为:
[[1 2]
[3 4]
[5 6]]
NumPy 也提供了 reshape 函数来调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2)
print (b)
输出结果为:
[[1, 2]
[3, 4]
[5, 6]]
ndarray.itemsize
ndarray.itemsize 以字节的形式返回数组中每一个元素的大小
例如,一个元素类型为 float64 的数组 itemsiz 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)。
实例
import numpy as np
# 数组的 dtype 为 int8(一个字节)
x = np.array([1,2,3,4,5], dtype = np.int8)
print (x.itemsize)
# 数组的 dtype 现在为 float64(八个字节)
y = np.array([1,2,3,4,5], dtype = np.float64)
print (y.itemsize)
输出结果为
1
8
ndarray.flags
ndarray.flags 返回 ndarray 对象的内存信息,包含以下属性:
| 属性 | 描述 |
|---|---|
| C_CONTIGUOUS © | 数据是在一个单一的C风格的连续段中 |
| F_CONTIGUOUS (F) | 数据是在一个单一的Fortran风格的连续段中 |
| OWNDATA (O) | 数组拥有它所使用的内存或从另一个对象中借用它 |
| WRITEABLE (W) | 数据区域可以被写入,将该值设置为 False,则数据为只读 |
| ALIGNED (A) | 数据和所有元素都适当地对齐到硬件上 |
| UPDATEIFCOPY (U) | 这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新 |
实例
import numpy as np
x = np.array([1,2,3,4,5])
print (x.flags)
输出结果为:
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
NumPy 创建数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
下面是一个创建空数组的实例:
import numpy as np
x = np.empty([3,2], dtype = int)
print (x)
输出结果为:
[[ 6917529027641081856 5764616291768666155]
[ 6917529027641081859 -5764598754299804209]
[ 4497473538 844429428932120]]
注意 − 数组元素为随机值,因为它们未初始化。
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = 'C')
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
实例
import numpy as np
# 默认为浮点数
x = np.zeros(5)
print(x)
# 设置类型为整数
y = np.zeros((5,), dtype = np.int)
print(y)
# 自定义类型
z = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')])
print(z)
输出结果为:
[0. 0. 0. 0. 0.]
[0 0 0 0 0]
[[(0, 0) (0, 0)]
[(0, 0) (0, 0)]]
numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = 'C')
参数说明:
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
实例
import numpy as np
# 默认为浮点数
x = np.ones(5)
print(x)
# 自定义类型
x = np.ones([2,2], dtype = int)
print(x)
输出结果为:
[1. 1. 1. 1. 1.]
[[1 1]
[1 1]]
NumPy 从已有的数组创建数组
本章节我们将学习如何从已有的数组创建数组。
numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 只有三个,比 numpy.array 少两个。
numpy.asarray(a, dtype = None, order = None)
参数说明:
| 参数 | 描述 |
|---|---|
| a | 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组 |
| dtype | 数据类型,可选 |
| order | 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
实例
将列表转换为 ndarray:
import numpy as np
x = [1,2,3]
a = np.asarray(x)
print (a)
输出结果为:
[1 2 3]
将元组转换为 ndarray:
实例
import numpy as np
x = (1,2,3)
a = np.asarray(x)
print (a)
输出结果为:
[1 2 3]
将元组列表转换为 ndarray:
实例
import numpy as np
x = [(1,2,3),(4,5)]
a = np.asarray(x)
print (a)
输出结果为:
[(1, 2, 3) (4, 5)]
设置了 dtype 参数:
实例
import numpy as np
x = [1,2,3]
a = np.asarray(x, dtype = float)
print (a)
输出结果为:
[ 1. 2. 3.]
numpy.frombuffer
numpy.frombuffer 用于实现动态数组。
numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
**注意:**buffer 是字符串的时候,Python3 默认 str 是 Unicode 类型,所以要转成 bytestring 在原 str 前加上 b。
参数说明:
| 参数 | 描述 |
|---|---|
| buffer | 可以是任意对象,会以流的形式读入。 |
| dtype | 返回数组的数据类型,可选 |
| count | 读取的数据数量,默认为-1,读取所有数据。 |
| offset | 读取的起始位置,默认为0。 |
Python3.x 实例
import numpy as np
s = b'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print (a)
输出结果为:
[b'H' b'e' b'l' b'l' b'o' b' ' b'W' b'o' b'r' b'l' b'd']
Python2.x 实例
import numpy as np
s = 'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print (a)
输出结果为:
['H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd']
numpy.fromiter
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.fromiter(iterable, dtype, count=-1)
| 参数 | 描述 |
|---|---|
| iterable | 可迭代对象 |
| dtype | 返回数组的数据类型 |
| count | 读取的数据数量,默认为-1,读取所有数据 |
实例
import numpy as np
# 使用 range 函数创建列表对象
list=range(5)
it=iter(list)
# 使用迭代器创建 ndarray
x=np.fromiter(it, dtype=float)
print(x)
输出结果为:
[0. 1. 2. 3. 4.]
NumPy 从数值范围创建数组
这一章节我们将学习如何从数值范围创建数组。
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
参数说明:
| 参数 | 描述 |
|---|---|
start |
起始值,默认为0 |
stop |
终止值(不包含) |
step |
步长,默认为1 |
dtype |
返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
实例
生成 0 到 5 的数组:
import numpy as np
x = np.arange(5)
print (x)
输出结果如下:
[0 1 2 3 4]
设置返回类型位 float:
import numpy as np
# 设置了 dtype
x = np.arange(5, dtype = float)
print (x)
输出结果如下:
[0. 1. 2. 3. 4.]
设置了起始值、终止值及步长:
import numpy as np
x = np.arange(10,20,2)
print (x)
输出结果如下:
[10 12 14 16 18]
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
参数说明:
| 参数 | 描述 |
|---|---|
start |
序列的起始值 |
stop |
序列的终止值,如果endpoint为true,该值包含于数列中 |
num |
要生成的等步长的样本数量,默认为50 |
endpoint |
该值为 ture 时,数列中中包含stop值,反之不包含,默认是True。 |
retstep |
如果为 True 时,生成的数组中会显示间距,反之不显示。 |
dtype |
ndarray 的数据类型 |
以下实例用到三个参数,设置起始点为 1 ,终止点为 10,数列个数为 10。
import numpy as np
a = np.linspace(1,10,10)
print(a)
输出结果为:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
设置元素全部是1的等差数列:
import numpy as np
a = np.linspace(1,1,10)
print(a)
输出结果为:
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
将 endpoint 设为 false,不包含终止值:
import numpy as np
a = np.linspace(10, 20, 5, endpoint = False)
print(a)
输出结果为:
[10. 12. 14. 16. 18.]
如果将 endpoint 设为 true,则会包含 20。
以下实例设置间距。
import numpy as np
a =np.linspace(1,10,10,retstep= True)
print(a)
# 拓展例子
b =np.linspace(1,10,10).reshape([10,1])
print(b)
输出结果为:
(array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]), 1.0)
[[ 1.]
[ 2.]
[ 3.]
[ 4.]
[ 5.]
[ 6.]
[ 7.]
[ 8.]
[ 9.]
[10.]]
numpy.logspace
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
base 参数意思是取对数的时候 log 的下标。
| 参数 | 描述 |
|---|---|
start |
序列的起始值为:base ** start |
stop |
序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中 |
num |
要生成的等步长的样本数量,默认为50 |
endpoint |
该值为 ture 时,数列中中包含stop值,反之不包含,默认是True。 |
base |
对数 log 的底数。 |
dtype |
ndarray 的数据类型 |
import numpy as np
# 默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
print (a)
输出结果为:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
将对数的底数设置为 2 :
import numpy as np
a = np.logspace(0,9,10,base=2)
print (a)
输出如下:
[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]