requests模块的入门使用
注意是requests不是request.
1、为什么使用requests模块,而不是用python自带的urllib
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
- requests能够自动帮助我们解压(gzip压缩的等)响应内容
作用:发送网络请求,返回响应数据
中文文档 :http://docs.python-requests.org/zh_CN/latest/index.html
通过观察文档来学习:如何使用requests来发送网络请求
2、requests模块发送简单的get请求,获取响应。
需求:通过requests向百度首页发送请求,获取百度首页的数据
import requests
# 目标url
url = 'https://www.baidu.com'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
- response.text 响应体 str类型
- respones.content 响应体 bytes类型
- response.status_code 响应状态码
- response.request.headers 响应对应的请求头
- response.headers 响应头
- response.request.cookies 响应对应请求的cookie
- response.cookies 响应的cookie(经过了set-cookie动作)
2.1 response.text 和response.content的区别
- response.text
类型:str
解码类型:requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码 - response.content
类型:bytes
解码类型:没有指定
如果在响应的response.text出现乱码,将下面的三个方式按个试一遍,一般就能解决问题
- response.content.decode()
- response.content.decode('GBK')
- response.content.decode('unicode-escape')
2.2 把网络上的图片保存到本地
我们来把网络上的图片保存到本地
分析:
- 图片的url:https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1591375146706&di=43effd06a8da881890c639b392db48cd&imgtype=0&src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20171108%2F3fe473acfc39476db58fadd7fbaf97ff.jpeg
- 利用requests模块发送请求获取响应
- 以2进制写入的方式打开文件,并将response响应的二进制内容写入
import requests
# 图片的url
img_url = 'https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1591375146706&di=43effd06a8da881890c639b392db48cd&imgtype=0&src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20171108%2F3fe473acfc39476db58fadd7fbaf97ff.jpeg'
# 响应本身就是一个图片,并且是二进制类型
response = requests.get(img_url)
img = response.content
# 以二进制+写入的方式打开文件
with open('first.jpg', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(img)
3、发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
# 打印响应对应请求的请求头信息
print(response.request.headers)
# 打印响应的数据长度
print(len(response.content.decode()))
输出:
{'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '/', 'Connection': 'keep-alive'}
2349
可以看出,请求头是python-requests,服务器很容易就发现是python而不是浏览器在访问。所以返回的数据非常少,
3.1 为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
3.2 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
3.3 用法
requests.get(url, headers=headers)
3.4 带上请求头的完整代码
import requests
url = "https://www.baidu.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
response = requests.get(url,headers=headers)
print(response.request.headers)
print(len(response.content.decode()))
输出:
{'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': '/', 'Connection': 'keep-alive'}
286046
4、发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个 ?,那么该问号后边的就是请求参数,又叫做查询字符串
4.1 什么叫做请求参数:
例1:https://www.sohu.com/a/128244875_623785
例2:https://www.baidu.com/s?wd=python
例1中没有请求参数!例2中?后边的就是请求参数
4.2 请求参数的形式:字典
kw = {'wd':'长城'}4.3 请求参数的用法
requests.get(url,params=kw)4.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试!对应的,在后续的爬虫中,遇到很多参数的url地址,都可以尝试删除参数。
4.5 两种方式:发送带参数的请求
1.对https://www.baidu.com/s?wd=python发起请求可以使用requests.get(url, params=kw)的方式。
# 方式一:利用params参数发送带参数的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?'
# 请求参数是一个字典 即wd=python
kw = {'wd': 'python'}
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw)
# 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?wd=python&a=c'-->{'wd': 'python', 'a': 'c'}
print(response.content)2.也可以直接对https://www.baidu.com/s?wd=python完整的url直接发送请求,不使用params参数
# 方式二:直接发送带参数的url的请求
import requests
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
url = 'https://www.baidu.com/s?wd=python'
# kw = {'wd': 'python'}
# url中包含了请求参数,所以此时无需params
response = requests.get(url, headers=headers)4.6 爬取指定贴吧
import requests
# 爬取指定名称的贴吧,然后把网页保存在本地
url="https://tieba.baidu.com/f?"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"
}
word = input("请输入想保存的贴吧名称:")
for i in range(int(input("请输入需要保存的页码:"))):
params = {
"kw": word,
"pn": i*50
}
response = requests.get(url,headers=headers,params=params)
with open(f"{word}{i+1}.html",'wb') as f:
f.write(response.content)
print(f"{word}{i+1}.html保存完成")二、requests模块的深入使用
1、使用requests发送POST请求
哪些地方我们会用到POST请求?
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
1.1 requests发送post请求语法:
- 用法:
response = requests.post("http://www.baidu.com/", data = data,headers=headers)- data 的形式:字典
1.2 POST请求练习
下面我们通过百度翻译的例子看看post请求如何使用:
思路分析
1、确定请求的url地址
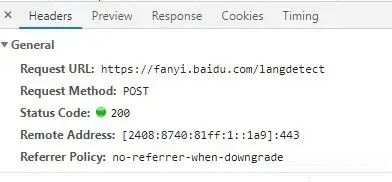
2、确定请求的参数

百度翻译获取翻译结果在另外一个url,也是post请求,但是参数很多,需要自己去构建,后面再说,这里简单的展示一个例子,获取输入的语言类型。
url = "https://fanyi.baidu.com/langdetect"
word = input("请输入查询的关键字:")
#构造表单
data = {
"query": word
}
# 发送请求
print(eval(requests.post(url,data=data).text)["lan"])
输出:
请输入查询的关键字:睡觉
zh
出现了eval,顺便说一下,eval自动调整数据的格式。
str_data = '{"name":"张三","password":"zhangsanzhenshuai"}'
print(type(str_data))
print(eval(str_data))
print(type(eval(str_data)))
输出:
<class 'str'>
{'name': '张三', 'password': 'zhangsanzhenshuai'}
<class 'dict'>2、使用代理
2.1 为什么要使用代理
- 让服务器以为不是同一个客户端在请求。
- 防止我们的真实地址被泄露,防止被追究。
2.2 理解使用代理的过程
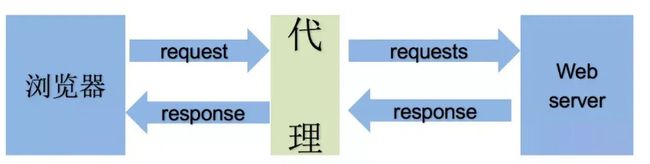
2.3 理解正向代理和反向代理的区别
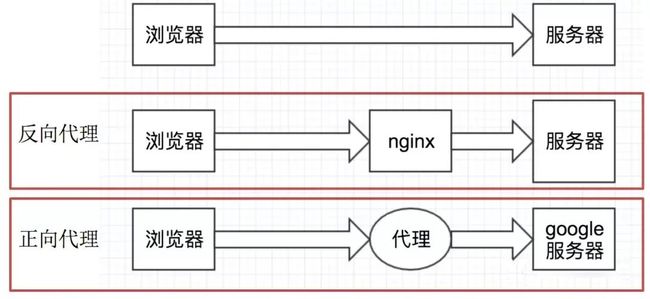
通过上图可以看出:
- 正向代理:对于浏览器知道服务器的真实地址,例如VPN
- 反向代理:浏览器不知道服务器的真实地址,例如nginx
2.4 代理的使用
- 用法:
requests.get("http://www.baidu.com", proxies = proxies)
- proxies的形式:字典
proxies = {
"http": "http://12.34.56.79:9527",
"https": "https://12.34.56.79:9527",
}
2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:
- 透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。
- 匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。
- 高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。
在使用的时候,毫无疑问使用高匿代理效果最好。
从请求使用的协议可以分为:
- http代理
- https代理
- socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择。
2.6 代理IP使用的注意点
1、反反爬
使用代理ip是非常必要的一种 反反爬 的方式
但是即使使用了代理ip,对方服务器仍然会有很多的方式来检测我们是否是一个爬虫,比如:
- 一段时间内,检测IP访问的频率,访问太多频繁会屏蔽。
- 检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽。
- 服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽。
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip。
2、代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取
可以免费领取源码、项目实战视频、PDF文件等
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
以上文章来源于海洋纪 ,作者劉夏橙