单链表的基本操作-----图形解析
首先我们需要思考的是为什么需要单链表呢?
单链表和顺序表相比较,又有什么优点呢?
在顺序表中,当我们需要头插,或者在顺序表的中间位置插入元素时,就必须将后面的元素一一后移,再将需要插入的元素插入进去。
可是这样的效率明显较低,所以我们就想到了单链表这种结构,可以将在物理地址上不连续的数据连接起来,需要连接,那么就需要有一个保存下一个元素地址的指针,想了想后,发现没有这样的内置类型可供我们使用,所以这时就需要我们自定义一个类型,在c语言中我们可以使用结构体来构造。
在这里我们讨论的都是无头单链表
单链表分为两种:无头单链表和有头单链表
无头单链表,也就是phead—只是一个指针,指向链表的第一个节点。
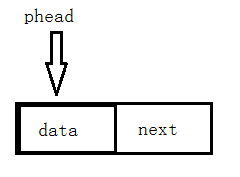
带头节点的单链表:只不过头结点的data不保存信息。

下来我们来讨论一下无头单链表的一些具体操作:为了便于理解,我会尽量用图表示出来具体的操作:
先构建一个节点:

1.初始化单链表:
代码实现:
void InitListNode(PNode *pHead)
{
assert(pHead);
*pHead = NULL;
}2.构建一个节点:
PNode BuyNode(DataType _data)
{
PNode node = (PNode)malloc(sizeof(Node));
if (node)
{
node->data = _data;
node->next = NULL;
}
return node;
}3.尾插
考虑因素:链表为空时,直接让phead指向新节点即可。
链表不空时,遍历一遍链表,找到最后一个链表,连接在最后一个链表的后面即可。
链表不空时图示:
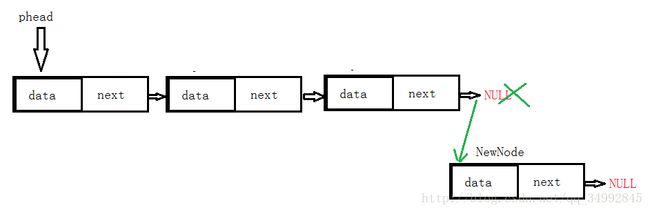
代码实现:
void PushBack(PNode *pHead,DataType _data)
{
assert(pHead);
PNode newNode = BuyNode(_data);
if (NULL == (*pHead))
{
*pHead = newNode;
return ;
}
PNode pCur = *pHead;
while (pCur->next)
{
pCur = pCur->next;
}
pCur->next = newNode;
}
4.尾删
考虑因素:链表为空时,直接返回
链表中只有一个结点时,free这个节点,并将phead置空
链表中有多个节点时,遍历一遍链表,找到最后一个节点(pCur->next == NULL),并且保存最后一个节点的前一个节点的信息,
如图所示:
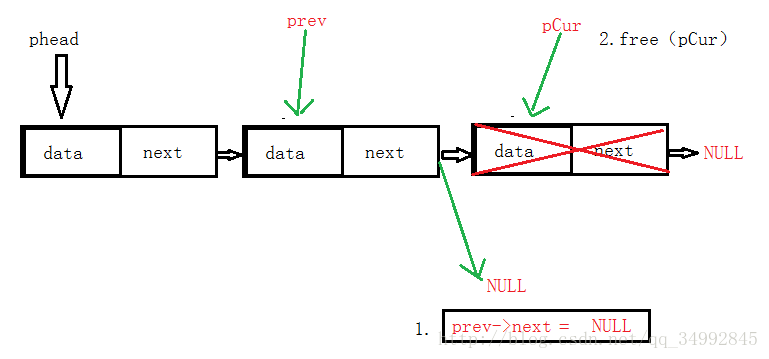
代码实现:
void PopBack(PNode *pHead)
{
assert(pHead);
if (NULL == (*pHead))
{
return ;
}
else if (NULL == (*pHead)->next)
{
free(*pHead);
*pHead = NULL;
}
else
{
PNode pCur = *pHead;
PNode prev = pCur;
while (pCur->next)
{
prev = pCur;
pCur = pCur->next;
}
free(pCur);
prev ->next = NULL;
}
}
5..头插
考虑因素:
链表为空时:直接让phead指向新的节点即可。
当链表有一个节点或者多个节点时:
如图示:
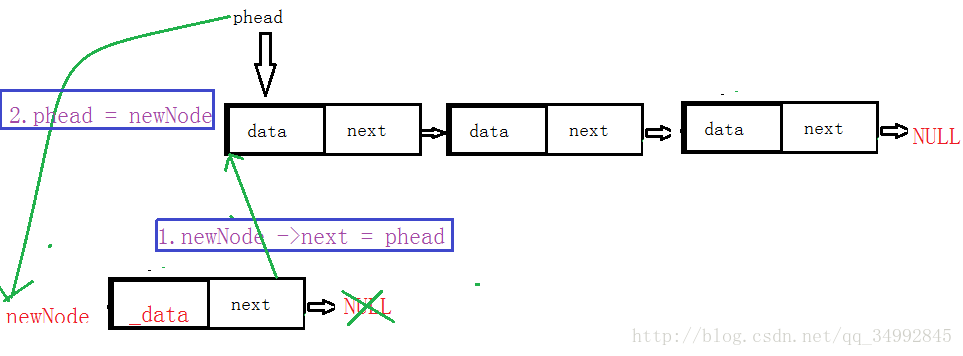
代码实现:
void PushFront(PNode *pHead,DataType _data)
{
assert(pHead);
PNode newNode = BuyNode(_data);
if (NULL == (*pHead))
{
*pHead = newNode;
}
else
{
if (newNode)
{
newNode->next = *pHead;
*pHead = newNode;
}
}
}6.头删
考虑因素:
链表为空时:直接返回,不需要删除
链表不为空时:当只有一个节点时:free掉这个节点,并将phead置空。
当有多个节点时:如图示
分析可知:有一个节点和有多个节点可以使用相同的逻辑
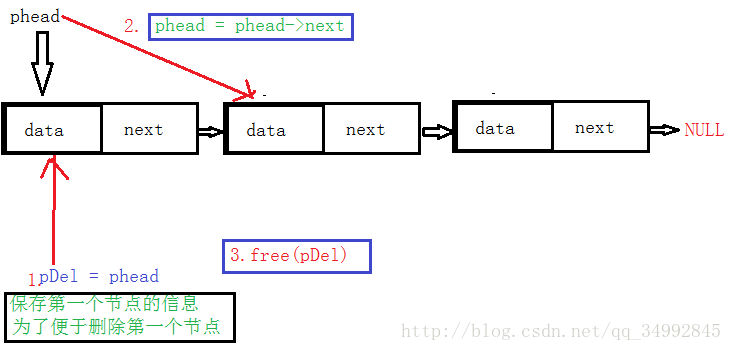
代码实现:
void PopFront(PNode *pHead)
{
assert(pHead);
if (NULL == (*pHead))
{
return ;
}
PNode pDel = *pHead;
*pHead = (*pHead)->next;
free(pDel);
}
7.逆序打印单链表(递归):
使用递归时,函数执行的流程:

代码实现:
void printFromTailToFront(PNode pHead)
{
if (pHead)
{
printFromTailToFront(pHead->next);
printf("%d->",pHead->data);
}
}
8.查找一个值为data的节点,如果存在,返回所在位置,否则,返回NULL
只需要遍历一遍链表即可。
代码实现:
PNode Find(PNode pHead, DataType _data)
{
if (NULL == pHead)
{
return NULL;
}
PNode pCur = pHead;
while (pCur)
{
if (pCur->data == _data)
{
return pCur;
}
pCur = pCur->next;
}
return NULL;
}
//插入一个节点
void InsertNode(PNode pos,DataType _data)
{
if (pos)
{
PNode newNode = BuyNode(_data);
if (newNode)
{
newNode->next = pos->next;
pos->next = newNode;
}
}
}
9.插入一个节点(由于是单链表,所以只能插在pos位置的后面)
需考虑的因素:
①检查参数(链表是否存在,pos位置是否为空)
②当pos位置不空时:如图示
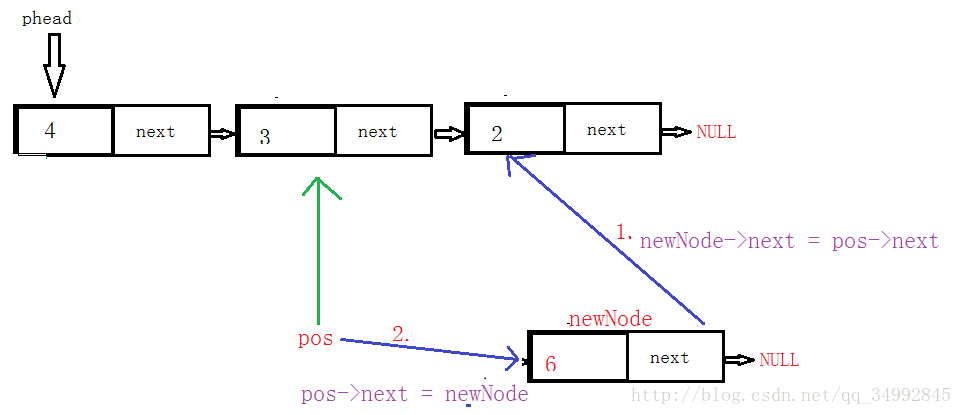
代码实现:
void InsertNode(PNode pos,DataType _data)
{
if (pos)
{
PNode newNode = BuyNode(_data);
if (newNode)
{
newNode->next = pos->next;
pos->next = newNode;
}
}
}10.删除pos位置上的一个节点:
需要考虑的因素:
①链表为空和pos为空,直接返回
②pos不为空且pos为1时,这时就可以转化为删除第一个节点,操作步骤同上面的头删
③当pos不是第一个节点时,分析如图示:
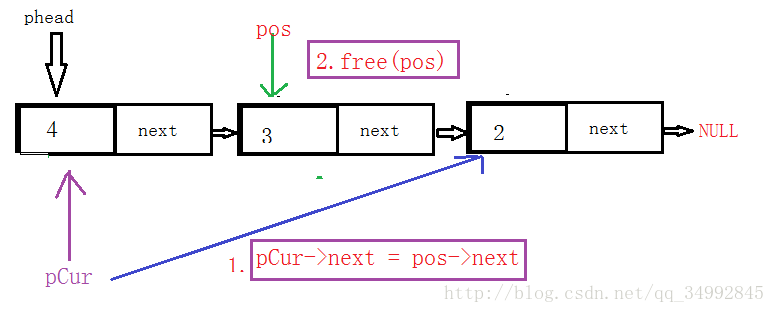
代码实现:
void Erase(PNode* pHead, PNode pos)
{
assert(pHead);
if ((NULL == (*pHead)) && (NULL == pos))
{
return ;
}
if((*pHead) == pos)
{
*pHead = pos->next;
free(pos);
}
else
{
PNode pCur = *pHead;
while (pCur ->next != pos)
{
pCur = pCur->next;
}
pCur->next = pos->next;
free(pos);
}
}
11.删除单链表中值为_data的节点:
代码实现:
void Remove(PNode* pHead, DataType _data)
{
assert(pHead);
Erase(pHead, Find(*pHead,_data));
}
12删除单链表中所有值为_data的节点:
需考虑:
①第一个节点的值是_data,因为删除第一个节点需要修改phead的值,所以需要单独处理第一个节点的值是_data的时候。
删除第一个节点就是上面所说的头删。
②如果第一个节点的值不是_data,直接处理即可。
下面处理第一个值不是_data(这里的_data为2)的情况:
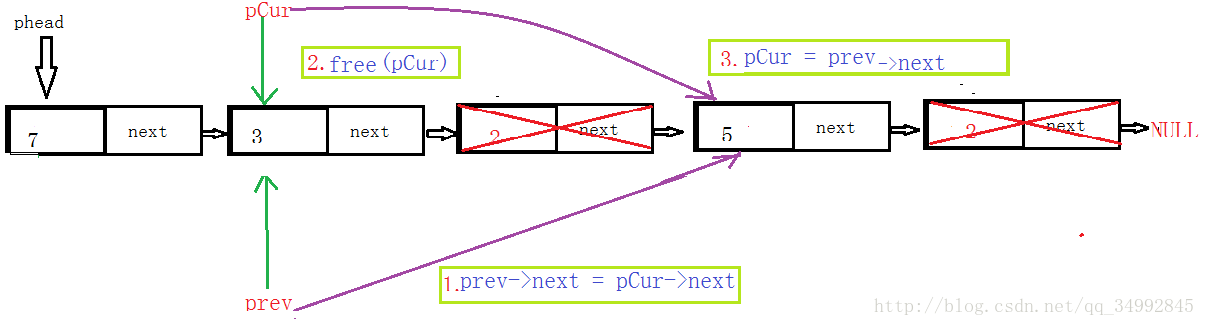
代码实现:
void RemoveAll(PNode *pHead, DataType _data)
{
assert(pHead);
if (NULL == (*pHead))
{
return ;
}
PNode pDel = *pHead;
if ((*pHead)->data == _data)
{
*pHead = (*pHead)->next;
free(pDel);
}
PNode pCur = *pHead;
PNode prev = pCur;
while (pCur)
{
if (pCur->data == _data)
{
prev->next = pCur->next;
free(pCur);
pCur = prev->next;
}
else
{
prev = pCur;
pCur = pCur->next;
}
}
}13.打印单链表:
代码实现:
void printList(PNode phead)
{
PNode pCur = phead;
while (pCur)
{
printf("%d ",pCur->data);
pCur = pCur->next;
}
printf("\n");
}
14.得到单链表中节点的个数:
代码实现:
size_t Size(PNode pHead)
{
size_t count = 0;
while (pHead)
{
pHead = pHead->next;
count++;
}
return count;
}单链表的排序等问题会在后续的单链表面试题中总结出来~