jvm总结(jvm结构,jvm垃圾回收算法及收集器,jvm优化,eclipse运行调优)
一、jvm 结构
jvm总体结构
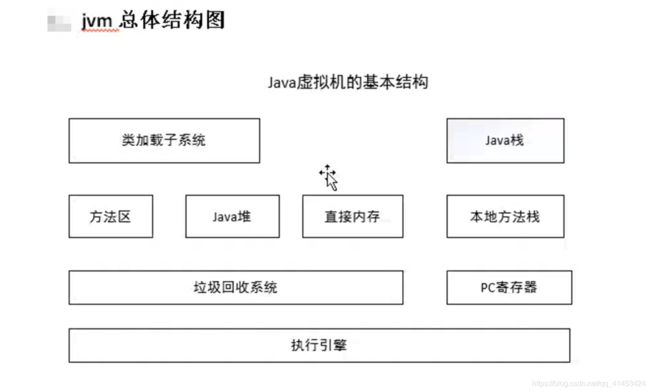
1、类加载子系统方法区:类加载子系统负责从文件系统或者网络中加载Class信息,加载的类信息存放于一块称为方法区的内存空间。除了类的信息外,方法区中可能还会放运行时常量池信息,包括字符串字面量和数字量(这部分常量信息是class文件中常量池部分的内存映射)附带朋友写的jvm类加载过程(https://blog.csdn.net/lucklilili/article/details/96969163)。
2、Java堆:在虚拟机启动的时候建立,它是Java程序最主要的内存工作区域。几乎所有的Java对象实例都存放在Java堆中。堆空间是所有线程共享的,这是一块与Java应用密切相关的内存空间。
3、直接内存:Java的NIO库允许Java程序使用直接内存。直接内存是在Java堆外的,直接向系统申请的内存空间。通常访问直接内存的速度会优于Java堆。因此出于性能的考虑,读写频繁的场合可能会考虑使用直接内存。由于直接内存在Java堆外,因此它的大小不会直接受限于xmx指定的最大堆大小(物理内存的1/4(<1GB)),但是系统内存是有限的,Java堆和直接内存的总和依然受限于操作系统能给出的最大内存。(实际大小内存取决于你的物理内存,大小肯定是大于堆的)
4、垃圾回收系统:垃圾回收系统是Java虚拟机的重要组成部分,垃圾回收器可以对方法区、Java堆和直接内存进行回收。其中Java堆是垃圾收集器的工作重点。和C/C++不同,Java中所有的对象空间释放都是隐式的,也就是说,Java中没有类似free()或者delete()这样的函数释放指定内存区域。对于不再使用的垃圾对象,垃圾回收系统会在后台默默工作,默默查找、标识并释放垃圾对象,完成包括Java堆、方法区何直接内存中的全自动化管理。
5、Java栈:每一个Java虚拟机线程都有一个私有的Java栈,一个线程的Java栈在线程创建的时候被创建,Java栈中保存着帧信息,Java栈中保存着局部变量、方法参数,同时和Java方法的调用、返回密切相关。
6、本地方法栈:本地方法栈和Java栈非常类似,最大的不同在于Java栈用于方法的调用,而本地方法栈则用于本地方法的调用,作为Java虚拟机的重要扩展,Java虚拟机允许Java直接调用本地方法(通常使用C编写)(每个操作系统都有不同的本地方法)
7、PC(Program Counter):PC寄存器也是每一个线程私有的空间,Java虚拟机会为每一个Java线程创建PC寄存器。在任意时刻,一个Java线程总是在执行一个方法,这个正在被执行的方法称为当前方法。如果方法不是本地方法,PC寄存器就会指向当前正在被执行的指令。如果当前方法是本地方法,那么PC寄存器的值就是undefined(可以理解为区分调用的是本地方法还是当前方法)
8、执行引擎:执行引擎是Java虚拟机的最核心组件之一,它负责执行虚拟机的字节码,现代虚拟机为了提高执行效率,会使用即时编译技术(just in time https://blog.csdn.net/shengzhu1/article/details/73281722)将方法编译成机器码后再执行。
2,jvm堆结构图及分代
Java虚拟机:jvm内存分代策略
Java虚拟机根据对象存活的周期不同,把堆内存划分为几块,一般分为新生代、老年代和永久代(对HotSpot虚拟机而言),这就是jvm的内存分代策略。
为什么要分代?
堆内存是虚拟机管理的内存中最大的一块,也是垃圾回收最频繁的一块区域,我们程序所有的对象实例都存放在堆内存中。给堆内存分代是为了提高对象内存分配和垃圾回收的效率。试想一下,如果堆内存没有区域划分,所有的新创建的对象和生命周期很长的对象放在一起,随着程序的执行,堆内存需要频繁进行垃圾收集,而每次回收都要遍历所有的对象,遍历这些对象所花费的时间代价是巨大的,会严重影响我们的GC效率,这简直太可怕了。
有了内存分代,情况就不同了,新创建的对象会在新生代中分配内存,经过多次回收仍然存活下来的对象存放在老年代中,静态属性,类信息等存放在永久代中,新生代中的对象存活时间短,只需要在新生代区域中频繁进行GC,老年代中对象生命周期长,内存回收的频率相对比较低,不需要频繁进行回收,永久代中回收效果太差,一般不进行垃圾回收,还可以根据不同年代的特点采用合适的垃圾收集算法。分代收集大大提升了收集效率,这些都是内存分代带来的好处。
内存分代划分
Java虚拟机将堆内存划分为新生代、老年代和永久代,永久代是HotSpot虚拟机特有的概念,它采用永久代的方法来实现方法区,其他的虚拟机实现没有这一概念,而且HotSpot也有取消永久代的趋势,在JDK1.7中HotSpot已经开始了”去永久化“,吧原本放在永久代的字符串常量池移除。永久代主要存放常量、类信息、静态变量等数据,与垃圾回收关系不大,新生代和老年代是垃圾回收的主要区域。内存分代示意图如下:
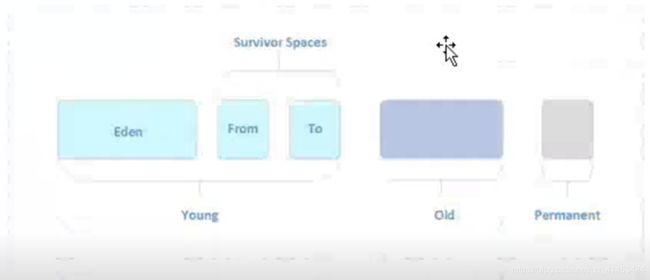
2.1新生代(Young Generation)
新生代的对象优先存放在新生代中,新生代对象朝生夕死,存活率很低,在新生代中,常规应用进行一次垃圾收集一般可以回收70%~95%的空间,回收率很高。
HotSpot将新生代分为三块,一块较大的Eden空间和两快较小的Survivor空间,默认比例为8:1:1.划分的目的是因为HotSpot采用复制算法来回收新生代,设置这个比例是为了充分利用内存空间,减少浪费。新生成的对象在Eden区分配(大对象除外,大对象直接进入老年代),当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC。GC开始时,对象只会存在于Eden区和From Survivor区时空的(作为保留区域)。GC进行时,Eden区中所有存活的对象都会被复制到To Survivor区,而在From Survivor区中,仍存活的对象会根据他们的年龄决定去向,年龄值到达年龄阀值(默认为15,新生代中的对象每熬过一轮垃圾回收,年龄值就会加1,GC分代年龄存储在对象的header中)的对象会被移到老年代中,没有达到阀值得对象都会被复制到To Survivor区。接着清空Eden区和From Survivor区,新生代中存活的对象都在To Survivor区。接着,From Survivor区和To Survivor区会交换他们的角色,也就是新的To Survivor区就是上次GC清空的From Survivor区,新的From Survivor区就是上次的GC的To Survivor区,总之,不管怎么样都会保证To Survivor区在一轮GC后是空的。GC时当To Survivor区没有足够的空间存放上一次新生代收集下来的存对象时,需要依赖老年代进行分配担保,将这些对象存放在老年代中。
2.2老年代(Oid Generationn)
在新生代中经历了多次(具体看虚拟机配置的阀值)GC后仍然存活下来的对象会进入老年代。老年代中的对象生命周期较长,存活率比较高,在老年代中进行GC的频率相对而言较低,而且回收的速度也比较慢。
2.3永久代(Permanent Generationn)
永久代存储类信息、常量、静态变量、即时编译器编译后的代码等数据,对这一区域而言,Java虚拟机规范支出可以不进行垃圾收集,一般而言不会进行垃圾回收。
二、jvm 垃圾回收算法及收集器
1,垃圾回收常见算法
1.1 引用计数(Reference Counting):
比较古老的回收算法,原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象,此算法最致命的是无法处理循环引用的问题。
1.2复制(Copying):
此算法把空间划为两个相等的区域,没次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。此算法每次只处理正在使用中的对象,因此复制成本较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
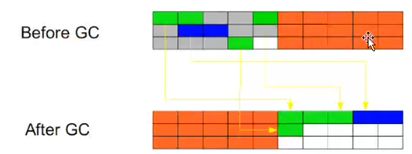
1.3标记-清除(Mark-Sweep):
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。

1.4标记-整理(Mark-Compact):
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两个阶段,第一个阶段从根节点开始标记所有被引用对象,第二阶段便利整个堆,把清除未标记对象并且把存活对象“压缩”到队的其中一块,按顺序排放,此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
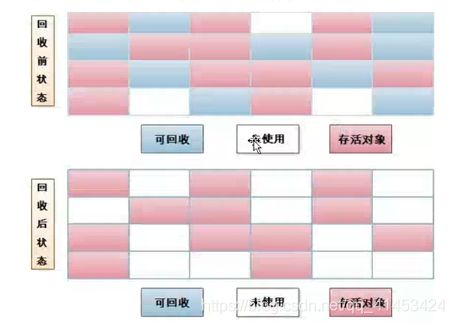
所谓的垃圾回收算法是什么呢?就是对垃圾回收的一种方式。如果说垃圾回收算法是垃圾回收的方法论的话那么垃圾收集器就是对该方法论的具体实现。
2,jvm中垃圾收集器
Scavenge GC(次收集)和Full GC 的区别(全收集)
新生代GC(Scavenge GC):Scavenge GC指发生在新生代的GC,因为新生代的java对象大多都是朝生夕死的,所以Scavenge GC 非常频繁,一般回收速度也比较快。当Eden空间不足以为对象分配内存时,会触发Scavenge GC。
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发Scavenge GC,对Eden区域进行GC,清除非存活对象,并且把尚且存货的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到老年代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
老年代GC(Full GC):Full GC指发生在老年代的GC,出现了Full GC一般会伴随着至少一次的Minor GC(老年代的对象大部分是Minor GC过程中从新生代进去老年代),比如:分配担保失败。Full GC的速度一般会比Minor GC慢10倍以上。当老年代内存不足或者显示调用System.gc()方法时,会触发Full GC。
次收集:当年轻代堆空间紧张时会被触发,相对于全收集而言,收集间隔较短。
全收集:当老年代或者持久代堆空间满了,会触发全收集操作,可以使用System.gc()方法来显示的启动全收集(不是立即启动而是优先启动Full GC),全收集一般根据堆大小的不同,需要的时间不尽相同,但一般会比较长,不过,如果全收集时间超过3到5秒钟,那就太长了。
3,分代回收器
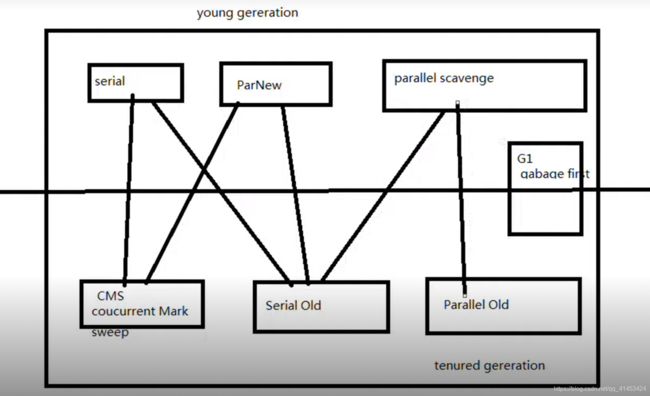
(注:连线表示可以配合着用)
新生代收集器:serial、parNew、parallel scavenge
老年代收集器:CMS(coucurrent Mark sweep)、Serial OId、Parallel OId
新老共同收集器:G1(gabage first)
3.1.1串行收集器(Serial)
Serial收集器是HotSpot运行在Client模式下的默认新生代收集器,它的特点是只用一个CPU/一条收集线程去完成GC工作,且在进行垃圾收集时必须暂停其他所有的工作线程(“Stop The World”)。可以使用-XX+UseSerialCG打开。
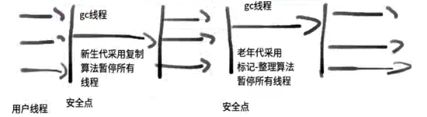
Serial收集器是单线程的。可以暂停其他所有的工作线程。
3.1.2并行收集器(ParNew)
ParNew收集器其实是前面Serial的多线程版本,除使用多条线程进行GC外,包括Serial可用的所有控制参数、收集算法、STW、对象分配规则、回收策略都与Serial完全一样(也是VM启用CMS收集器-XX:+UseConcMarkSweepGC的默认新生代收集器)

由于存在线程切换的开销,ParNew在单CPU的环境中比不上Serial,且在通过超线程技术实现的两个CPU的环境中也不能100%保证能超越Serial,但随看可用的CPU数量的增加,收集效率很定也回大大增加(parNew收集线程数与CPU的数量相同,因此在COU数量过大的环境中,可用-XX:parallelGCThreads=
3.1.3parallel Scavenge收集器
与ParNew类似,Parallel Scavenger也是使用复制算法,也是并行多线程收集器,但与其他收集器关注尽可能缩短垃圾收集时间不同,Parallel Scavenger更关注系统吞吐量:系统吞吐量-运行用户代码时间/(运行用户代码时间+垃圾收集时间)停顿时间越短就越适用于用户交互的程序-良好的响应速度能提升用户的体验;而高吞吐量则适用于后台运算而不需要太多交互的任务-可以最高效率的利用CPU时间,尽快的完成程序的运算任务,Parallel Scavenger提供了如下参数设置系统吞吐量:

3.2老年代收集器
Serial Old 是Serial收集器的老年代版本,同样是单线程收集器,适用”标记-整理“算法(因为老年代没有Survivor,更换算法);

3.2.2Parallel Old收集器
Parallel Old是Parallel Scavenge收老年代版本,使用多线程和”标记-整理“算法,吞吐量优先,主要与Parallel Scavenge配合在注重吞吐量及CPU资源敏感系统内使用:

3.2.3CMS收集器
CMS(Concurrent Mark Sweep)收集器是一款具有划时代意义的收集器,一款真正意义上的并发收集器,虽然现在已经有了理论意义上表现更好的G1收集器,但现在主流互联网企业线上选用的仍是CMS(如Taobao、微店)。
CMS是一种以获取最短回收停顿时间为目标的收集器(CMS 又称多并发低暂停的收集器),基于”标记-清除“算法实现,整个GC过程分为以下4个步骤:
(并行指的是GC的线程和用户的线程没有关系,没有用户线程的叫并行。并发是指有用户线程的叫并发)
1.初始化标记(CMS initial mark)
2.并发标记(CMS concurrent mark;GC Roots Tracing过程)
3.重新标记(CMS remark)
4.并发清除(CMS concurrent sweep;已死对象将会就地释放,注意:此处没有压缩)

3.3分区收集-G1收集器
G1(Garbage-First)是一款面向服务端应用的收集器,主要目标用于配备多颖CPU的服务器治理大内存。--XX:+UserG1GC启用G1收集器。
与其它基于分代的收集器不同,G1将整个java 堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再不再是物理隔离的了,它们都是一部分Region(不需要连续)的集合。

(因为G1比较长就不写了详细介绍可参考https://www.jianshu.com/p/0f1f5adffdc1)
三、jvm优化
1,jvm小工具




在cmd(windows) 输入 “jvisualvm” 命令就出现可视化的监控jvm了,可以根据应用配置一些参数显示如下:

完之后下载visual gc插件(https://visualvm.github.io/archive/uc/8u40/updates.html),利用这个插件就可以看得很清晰了(用的mac):

2,jvm参数介绍
详见最底部▼
3,常见配置举例
https://www.cnblogs.com/alexzhang92/p/11029492.html(可参考)
更多优化可以考虑吞吐量
4,调优总结:
年轻代大小的选择
响应时间优先的应用:尽可能设大,直到接近系统的最低响应时间限制(根据实际情况选择)。在此种情况下,年轻代收集发生的频率也是最小的。同时,减少到达年老代的对象。
吞吐量优先的应用:尽可能的设置大,可能达到Gbit的程度。因为对响应时间没有要求,垃圾收集可以并行进行,一般适合8CPU以上的应用。年代大小选择
响应时间优先的应用:老年代使用并发收集器,所以其大小需要小心设置,一般要考虑并发会话率和会话持续时间等一些参数。如果堆设置小了,可以会造成内存碎片、搞回收频率以及应用暂停而使用传统的标记清楚方式;如果堆大了,则需要较长的收集时间。最优化的方案,一般需要参考以下数据获得:
.并发垃圾收集信息
.持久代并发收集次数
.传统GC信息
.花在年轻代和老年代回收上的时间比例,减少年轻代和老年代花费的时间,一般会提高应用的效率
吞吐量优先的应用:一般吞吐量优先的应用都有一个很大的年轻代和一个较小的年老代。原因是,这样可以尽可能回收掉大部分短期对象,减少中期的对象,而年老代尽存放长期存活对象。
四、eclipse运行调优
通过上边写到的jvisualvm Visual GC插件查看eclipse的启动,修改配置提高启动速度
run运行时可以选择 run configurations,给与命令启动
;
附 JVM参数的含义(转自https://blog.csdn.net/qq_15037231/article/details/80605350)
| 参数名称 | 含义 | 默认值 | |
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 |
|
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右 一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长) 和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"” -Xss is translated in a VM flag named ThreadStackSize” 一般设置这个值就可以了。 |
|
| -XX:ThreadStackSize | Thread Stack Size | (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=2表示年轻代与年老代所占比值为1:2,年轻代占整个堆栈的1/3 Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 |
|
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大, 会影响Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | ||
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率 该参数只有在串行GC时才有效. |
|
| -XX:+AggressiveOpts | 加快编译 | ||
| -XX:+UseBiasedLocking | 锁机制的性能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1s | softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节 新生代采用Parallel Scavenge GC时无效 另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
并行收集器相关参数
| -XX:+UseParallelGC | Full GC采用parallel MSC (此项待验证) |
选择垃圾收集器为并行收集器.此配置仅对年轻代有效.即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集.(此项待验证) |
|
| -XX:+UseParNewGC | 设置年轻代为并行收集 | 可与CMS收集同时使用 JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值 |
|
| -XX:ParallelGCThreads | 并行收集器的线程数 | 此值最好配置与处理器数目相等 同样适用于CMS | |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式为并行收集(Parallel Compacting) | 这个是JAVA 6出现的参数选项 | |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) | 如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值. | |
| -XX:+UseAdaptiveSizePolicy | 自动选择年轻代区大小和相应的Survivor区比例 | 设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开. | |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 | 公式为1/(1+n) | |
| -XX:+ScavengeBeforeFullGC | Full GC前调用YGC | true | Do young generation GC prior to a full GC. (Introduced in 1.4.1.) |
CMS相关参数
| -XX:+UseConcMarkSweepGC | 使用CMS内存收集 | 测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明.所以,此时年轻代大小最好用-Xmn设置.??? | |
| -XX:+AggressiveHeap | 试图是使用大量的物理内存 长时间大内存使用的优化,能检查计算资源(内存, 处理器数量) 至少需要256MB内存 大量的CPU/内存, (在1.4.1在4CPU的机器上已经显示有提升) |
||
| -XX:CMSFullGCsBeforeCompaction | 多少次后进行内存压缩 | 由于并发收集器不对内存空间进行压缩,整理,所以运行一段时间以后会产生"碎片",使得运行效率降低.此值设置运行多少次GC以后对内存空间进行压缩,整理. | |
| -XX:+CMSParallelRemarkEnabled | 降低标记停顿 | ||
| -XX+UseCMSCompactAtFullCollection | 在FULL GC的时候, 对年老代的压缩 | CMS是不会移动内存的, 因此, 这个非常容易产生碎片, 导致内存不够用, 因此, 内存的压缩这个时候就会被启用。 增加这个参数是个好习惯。 可能会影响性能,但是可以消除碎片 |
|
| -XX:+UseCMSInitiatingOccupancyOnly | 使用手动定义初始化定义开始CMS收集 | 禁止hostspot自行触发CMS GC | |
| -XX:CMSInitiatingOccupancyFraction=70 | 使用cms作为垃圾回收 使用70%后开始CMS收集 |
92 | 为了保证不出现promotion failed(见下面介绍)错误,该值的设置需要满足以下公式CMSInitiatingOccupancyFraction计算公式 |
| -XX:CMSInitiatingPermOccupancyFraction | 设置Perm Gen使用到达多少比率时触发 | 92 | |
| -XX:+CMSIncrementalMode | 设置为增量模式 | 用于单CPU情况 | |
| -XX:+CMSClassUnloadingEnabled |
辅助信息
| -XX:+PrintGC | 输出形式: [GC 118250K->113543K(130112K), 0.0094143 secs] |
||
| -XX:+PrintGCDetails | 输出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] |
||
| -XX:+PrintGCTimeStamps | |||
| -XX:+PrintGC:PrintGCTimeStamps | 可与-XX:+PrintGC -XX:+PrintGCDetails混合使用 输出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs] |
||
| -XX:+PrintGCApplicationStoppedTime | 打印垃圾回收期间程序暂停的时间.可与上面混合使用 | 输出形式:Total time for which application threads were stopped: 0.0468229 seconds | |
| -XX:+PrintGCApplicationConcurrentTime | 打印每次垃圾回收前,程序未中断的执行时间.可与上面混合使用 | 输出形式:Application time: 0.5291524 seconds | |
| -XX:+PrintHeapAtGC | 打印GC前后的详细堆栈信息 | ||
| -Xloggc:filename | 把相关日志信息记录到文件以便分析. 与上面几个配合使用 |
||
| -XX:+PrintClassHistogram |
garbage collects before printing the histogram. | ||
| -XX:+PrintTLAB | 查看TLAB空间的使用情况 | ||
| XX:+PrintTenuringDistribution | 查看每次minor GC后新的存活周期的阈值 | Desired survivor size 1048576 bytes, new threshold 7 (max 15)
|
下面的表格是官方文档(点击打开oracle官网查看)
Behavioral Options
| Option and Default Value | Description |
|---|---|
| -XX:-AllowUserSignalHandlers | Do not complain if the application installs signal handlers. (Relevant to Solaris and Linux only.) |
| -XX:AltStackSize=16384 | Alternate signal stack size (in Kbytes). (Relevant to Solaris only, removed from 5.0.) |
| -XX:-DisableExplicitGC | By default calls to System.gc() are enabled (-XX:-DisableExplicitGC). Use -XX:+DisableExplicitGC to disable calls to System.gc(). Note that the JVM still performs garbage collection when necessary. |
| -XX:+FailOverToOldVerifier | Fail over to old verifier when the new type checker fails. (Introduced in 6.) |
| -XX:+HandlePromotionFailure | The youngest generation collection does not require a guarantee of full promotion of all live objects. (Introduced in 1.4.2 update 11) [5.0 and earlier: false.] |
| -XX:+MaxFDLimit | Bump the number of file descriptors to max. (Relevant to Solaris only.) |
| -XX:PreBlockSpin=10 | Spin count variable for use with -XX:+UseSpinning. Controls the maximum spin iterations allowed before entering operating system thread synchronization code. (Introduced in 1.4.2.) |
| -XX:-RelaxAccessControlCheck | Relax the access control checks in the verifier. (Introduced in 6.) |
| -XX:+ScavengeBeforeFullGC | Do young generation GC prior to a full GC. (Introduced in 1.4.1.) |
| -XX:+UseAltSigs | Use alternate signals instead of SIGUSR1 and SIGUSR2 for VM internal signals. (Introduced in 1.3.1 update 9, 1.4.1. Relevant to Solaris only.) |
| -XX:+UseBoundThreads | Bind user level threads to kernel threads. (Relevant to Solaris only.) |
| -XX:-UseConcMarkSweepGC | Use concurrent mark-sweep collection for the old generation. (Introduced in 1.4.1) |
| -XX:+UseGCOverheadLimit | Use a policy that limits the proportion of the VM's time that is spent in GC before an OutOfMemory error is thrown. (Introduced in 6.) |
| -XX:+UseLWPSynchronization | Use LWP-based instead of thread based synchronization. (Introduced in 1.4.0. Relevant to Solaris only.) |
| -XX:-UseParallelGC | Use parallel garbage collection for scavenges. (Introduced in 1.4.1) |
| -XX:-UseParallelOldGC | Use parallel garbage collection for the full collections. Enabling this option automatically sets -XX:+UseParallelGC. (Introduced in 5.0 update 6.) |
| -XX:-UseSerialGC | Use serial garbage collection. (Introduced in 5.0.) |
| -XX:-UseSpinning | Enable naive spinning on Java monitor before entering operating system thread synchronizaton code. (Relevant to 1.4.2 and 5.0 only.) [1.4.2, multi-processor Windows platforms: true] |
| -XX:+UseTLAB | Use thread-local object allocation (Introduced in 1.4.0, known as UseTLE prior to that.) [1.4.2 and earlier, x86 or with -client: false] |
| -XX:+UseSplitVerifier | Use the new type checker with StackMapTable attributes. (Introduced in 5.0.)[5.0: false] |
| -XX:+UseThreadPriorities | Use native thread priorities. |
| -XX:+UseVMInterruptibleIO | Thread interrupt before or with EINTR for I/O operations results in OS_INTRPT. (Introduced in 6. Relevant to Solaris only.) |
Garbage First (G1) Garbage Collection Options
| Option and Default Value | Description |
|---|---|
| -XX:+UseG1GC | Use the Garbage First (G1) Collector |
| -XX:MaxGCPauseMillis=n | Sets a target for the maximum GC pause time. This is a soft goal, and the JVM will make its best effort to achieve it. |
| -XX:InitiatingHeapOccupancyPercent=n | Percentage of the (entire) heap occupancy to start a concurrent GC cycle. It is used by GCs that trigger a concurrent GC cycle based on the occupancy of the entire heap, not just one of the generations (e.g., G1). A value of 0 denotes 'do constant GC cycles'. The default value is 45. |
| -XX:NewRatio=n | Ratio of old/new generation sizes. The default value is 2. |
| -XX:SurvivorRatio=n | Ratio of eden/survivor space size. The default value is 8. |
| -XX:MaxTenuringThreshold=n | Maximum value for tenuring threshold. The default value is 15. |
| -XX:ParallelGCThreads=n | Sets the number of threads used during parallel phases of the garbage collectors. The default value varies with the platform on which the JVM is running. |
| -XX:ConcGCThreads=n | Number of threads concurrent garbage collectors will use. The default value varies with the platform on which the JVM is running. |
| -XX:G1ReservePercent=n | Sets the amount of heap that is reserved as a false ceiling to reduce the possibility of promotion failure. The default value is 10. |
| -XX:G1HeapRegionSize=n | With G1 the Java heap is subdivided into uniformly sized regions. This sets the size of the individual sub-divisions. The default value of this parameter is determined ergonomically based upon heap size. The minimum value is 1Mb and the maximum value is 32Mb. |
Performance Options
| Option and Default Value | Description |
|---|---|
| -XX:+AggressiveOpts | Turn on point performance compiler optimizations that are expected to be default in upcoming releases. (Introduced in 5.0 update 6.) |
| -XX:CompileThreshold=10000 | Number of method invocations/branches before compiling [-client: 1,500] |
| -XX:LargePageSizeInBytes=4m | Sets the large page size used for the Java heap. (Introduced in 1.4.0 update 1.) [amd64: 2m.] |
| -XX:MaxHeapFreeRatio=70 | Maximum percentage of heap free after GC to avoid shrinking. |
| -XX:MaxNewSize=size | Maximum size of new generation (in bytes). Since 1.4, MaxNewSize is computed as a function of NewRatio. [1.3.1 Sparc: 32m; 1.3.1 x86: 2.5m.] |
| -XX:MaxPermSize=64m | Size of the Permanent Generation. [5.0 and newer: 64 bit VMs are scaled 30% larger; 1.4 amd64: 96m; 1.3.1 -client: 32m.] |
| -XX:MinHeapFreeRatio=40 | Minimum percentage of heap free after GC to avoid expansion. |
| -XX:NewRatio=2 | Ratio of old/new generation sizes. [Sparc -client: 8; x86 -server: 8; x86 -client: 12.]-client: 4 (1.3) 8 (1.3.1+), x86: 12] |
| -XX:NewSize=2m | Default size of new generation (in bytes) [5.0 and newer: 64 bit VMs are scaled 30% larger; x86: 1m; x86, 5.0 and older: 640k] |
| -XX:ReservedCodeCacheSize=32m | Reserved code cache size (in bytes) - maximum code cache size. [Solaris 64-bit, amd64, and -server x86: 2048m; in 1.5.0_06 and earlier, Solaris 64-bit and amd64: 1024m.] |
| -XX:SurvivorRatio=8 | Ratio of eden/survivor space size [Solaris amd64: 6; Sparc in 1.3.1: 25; other Solaris platforms in 5.0 and earlier: 32] |
| -XX:TargetSurvivorRatio=50 | Desired percentage of survivor space used after scavenge. |
| -XX:ThreadStackSize=512 | Thread Stack Size (in Kbytes). (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] |
| -XX:+UseBiasedLocking | Enable biased locking. For more details, see thistuning example. (Introduced in 5.0 update 6.) [5.0: false] |
| -XX:+UseFastAccessorMethods | Use optimized versions of Get |
| -XX:-UseISM | Use Intimate Shared Memory. [Not accepted for non-Solaris platforms.] For details, see Intimate Shared Memory. |
| -XX:+UseLargePages | Use large page memory. (Introduced in 5.0 update 5.) For details, see Java Support for Large Memory Pages. |
| -XX:+UseMPSS | Use Multiple Page Size Support w/4mb pages for the heap. Do not use with ISM as this replaces the need for ISM. (Introduced in 1.4.0 update 1, Relevant to Solaris 9 and newer.) [1.4.1 and earlier: false] |
| -XX:+UseStringCache | Enables caching of commonly allocated strings. |
| -XX:AllocatePrefetchLines=1 | Number of cache lines to load after the last object allocation using prefetch instructions generated in JIT compiled code. Default values are 1 if the last allocated object was an instance and 3 if it was an array. |
| -XX:AllocatePrefetchStyle=1 | Generated code style for prefetch instructions. 0 - no prefetch instructions are generate*d*, 1 - execute prefetch instructions after each allocation, 2 - use TLAB allocation watermark pointer to gate when prefetch instructions are executed. |
| -XX:+UseCompressedStrings | Use a byte[] for Strings which can be represented as pure ASCII. (Introduced in Java 6 Update 21 Performance Release) |
| -XX:+OptimizeStringConcat | Optimize String concatenation operations where possible. (Introduced in Java 6 Update 20) |
Debugging Options
| Option and Default Value | Description |
|---|---|
| -XX:-CITime | Prints time spent in JIT Compiler. (Introduced in 1.4.0.) |
| -XX:ErrorFile=./hs_err_pid |
If an error occurs, save the error data to this file. (Introduced in 6.) |
| -XX:-ExtendedDTraceProbes | Enable performance-impacting dtrace probes. (Introduced in 6. Relevant to Solaris only.) |
| -XX:HeapDumpPath=./java_pid |
Path to directory or filename for heap dump.Manageable. (Introduced in 1.4.2 update 12, 5.0 update 7.) |
| -XX:-HeapDumpOnOutOfMemoryError | Dump heap to file when java.lang.OutOfMemoryError is thrown. Manageable. (Introduced in 1.4.2 update 12, 5.0 update 7.) |
| -XX:OnError=" |
Run user-defined commands on fatal error. (Introduced in 1.4.2 update 9.) |
| -XX:OnOutOfMemoryError=" |
Run user-defined commands when an OutOfMemoryError is first thrown. (Introduced in 1.4.2 update 12, 6) |
| -XX:-PrintClassHistogram | Print a histogram of class instances on Ctrl-Break.Manageable. (Introduced in 1.4.2.) The jmap -histocommand provides equivalent functionality. |
| -XX:-PrintConcurrentLocks | Print java.util.concurrent locks in Ctrl-Break thread dump. Manageable. (Introduced in 6.) The jstack -lcommand provides equivalent functionality. |
| -XX:-PrintCommandLineFlags | Print flags that appeared on the command line. (Introduced in 5.0.) |
| -XX:-PrintCompilation | Print message when a method is compiled. |
| -XX:-PrintGC | Print messages at garbage collection. Manageable. |
| -XX:-PrintGCDetails | Print more details at garbage collection. Manageable. (Introduced in 1.4.0.) |
| -XX:-PrintGCTimeStamps | Print timestamps at garbage collection. Manageable(Introduced in 1.4.0.) |
| -XX:-PrintTenuringDistribution | Print tenuring age information. |
| -XX:-PrintAdaptiveSizePolicy | Enables printing of information about adaptive generation sizing. |
| -XX:-TraceClassLoading | Trace loading of classes. |
| -XX:-TraceClassLoadingPreorder | Trace all classes loaded in order referenced (not loaded). (Introduced in 1.4.2.) |
| -XX:-TraceClassResolution | Trace constant pool resolutions. (Introduced in 1.4.2.) |
| -XX:-TraceClassUnloading | Trace unloading of classes. |
| -XX:-TraceLoaderConstraints | Trace recording of loader constraints. (Introduced in 6.) |
| -XX:+PerfDataSaveToFile | Saves jvmstat binary data on exit. |
| -XX:ParallelGCThreads=n | Sets the number of garbage collection threads in the young and old parallel garbage collectors. The default value varies with the platform on which the JVM is running. |
| -XX:+UseCompressedOops | Enables the use of compressed pointers (object references represented as 32 bit offsets instead of 64-bit pointers) for optimized 64-bit performance with Java heap sizes less than 32gb. |
| -XX:+AlwaysPreTouch | Pre-touch the Java heap during JVM initialization. Every page of the heap is thus demand-zeroed during initialization rather than incrementally during application execution. |
| -XX:AllocatePrefetchDistance=n | Sets the prefetch distance for object allocation. Memory about to be written with the value of new objects is prefetched into cache at this distance (in bytes) beyond the address of the last allocated object. Each Java thread has its own allocation point. The default value varies with the platform on which the JVM is running. |
| -XX:InlineSmallCode=n | Inline a previously compiled method only if its generated native code size is less than this. The default value varies with the platform on which the JVM is running. |
| -XX:MaxInlineSize=35 | Maximum bytecode size of a method to be inlined. |
| -XX:FreqInlineSize=n | Maximum bytecode size of a frequently executed method to be inlined. The default value varies with the platform on which the JVM is running. |
| -XX:LoopUnrollLimit=n | Unroll loop bodies with server compiler intermediate representation node count less than this value. The limit used by the server compiler is a function of this value, not the actual value. The default value varies with the platform on which the JVM is running. |
| -XX:InitialTenuringThreshold=7 | Sets the initial tenuring threshold for use in adaptive GC sizing in the parallel young collector. The tenuring threshold is the number of times an object survives a young collection before being promoted to the old, or tenured, generation. |
| -XX:MaxTenuringThreshold=n | Sets the maximum tenuring threshold for use in adaptive GC sizing. The current largest value is 15. The default value is 15 for the parallel collector and is 4 for CMS. |
| -Xloggc: |
Log GC verbose output to specified file. The verbose output is controlled by the normal verbose GC flags. |
| -XX:-UseGCLogFileRotation | Enabled GC log rotation, requires -Xloggc. |
| -XX:NumberOfGClogFiles=1 | Set the number of files to use when rotating logs, must be >= 1. The rotated log files will use the following naming scheme, |
| -XX:GCLogFileSize=8K | The size of the log file at which point the log will be rotated, must be >= 8K. |