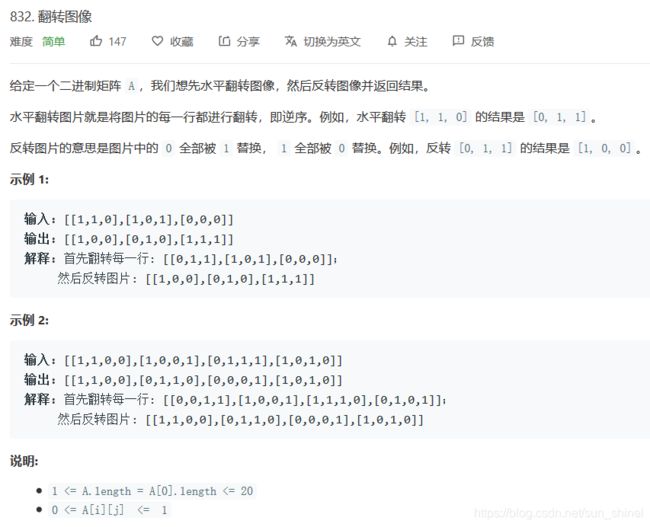
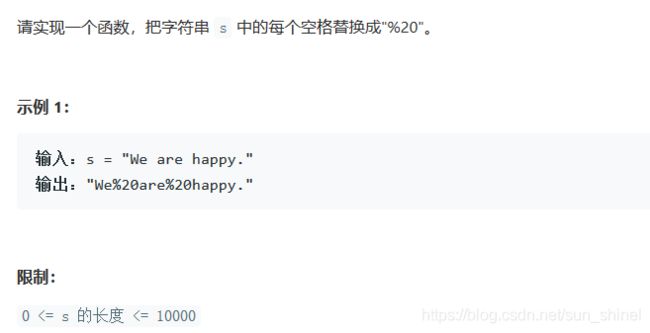
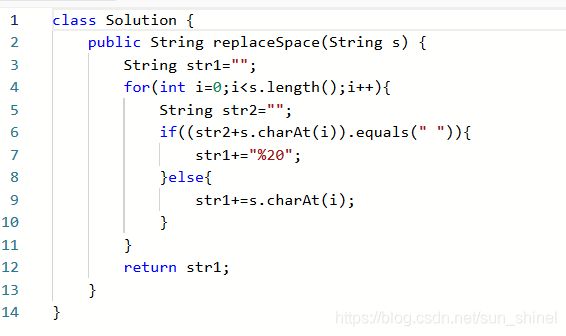
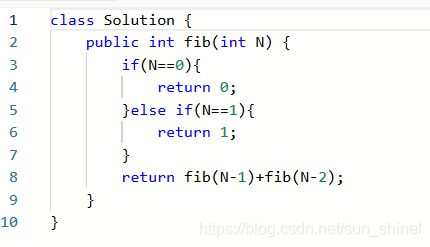
力扣练习题一
1.向一个长度为n的向量的第i个元素(1≤i≤n+1)之前插入一个元素时,需向后移动(B) 个元素。
A n-iB n-i+1C n-i-1D i
分析:在第i个元素之前插入一个数,等效于在第i-1个元素之后插入一个数,所以需要移动n-(i-1)个数。
2.在表长为n的顺序表上做插入运算,平均要移动的结点数为( C) 。
A n/4B n/3C n/2D n
分析:插入第一个元素之前需要移动n个元素,插入到第二个元素之前需要移动n-1个元素 .......插入到倒数第一个元素之前需要移动1个元素,插入到最后一个元素之后需要移动0个元素,所以全部的可能性加起来要移动(0+n)*(n+1)/2,一共有n+1种可能性,所以平均移动(0+n)*(n+1)/2/(n+1)=n/2。
3.对于长度为n的线性表,建立其对应的单链表的时间复杂度为(c)。
A O(1)B O(log2n)C O(n)D O(n^2)
分析:在建立相应的单链表时需要遍历线性表,所以时间复杂度为n。
4.以下定义和初始化的两数组a1和a2,那么下列说法正确的是( )。
char a1[]= "program";
char a2[]={'p','r','o','g','r','a','m'}a1和a2完全相同a1和a2不同,a1是指针a1和a2存储单元的数目相同a1和a2不同,a1的存储单元数目多
分析:a1初始化的是一个字符串,字符串的最后包含字符‘/0’。
5 广义表(((a,b,c),d,e,f))的长度是4(B )
A 对 B 错
分析:广义表的长度定义为最外层包含元素个数,广义表的深度定义为所含括弧的重数的最大值。其中原子的深度为0,空表的深度为1。这个题最外层只包含了一个元素((a,b,c),d,e,f)因此长度是1,他的所含括弧的重数的最大值是3,所以深度是3。
6 以下正确定义一维数组的选项是( B )
A int a[5] = {0, 1, 2, 3, 4, 5};B char a[] = {0, 1, 2, 3, 4, 5};C char a = {'A', 'B', 'C'};D int a[5] = "0123";
分析:一维数组的定义方法有三种分别是:数据类型[] 数组名=new 数据类型[]{1,2,3,4,5};
数据类型[] 数组名=new 数据类型[长度];
数据类型[] 数组名={1,2,3,4,5};
7 数组定义为“ int a [ 4 ] ; ”,表达式 (D ) 是错误的。
A *aB a [ 0 ]C aD a++
分析:a加*表示对数组起始位置按照数组元素数据类型寻址取值第一个元素。加&表示取第一个元素地址。a与&a与&a[0]相同。a是指一个地址,地址为常量,不可赋值。
8
有一随机数组(25,84,21,46,13,27,68,35,20),采用某种方法对它们进行排序,其每趟排序
结果如下,
则该排序方法是(C )。
初 始:25,84,21,46,13,27,68,35,20
第一趟:20,13,21,25,46,27,68,35,84
第二趟:13,20,21,25,35,27,46,68,84
第三趟:13,20,21,25,27,35,46,68,84
A 基数排序B 插入排序C 快速排序D 起泡排序
1设置两个变量left、right,快速排序开始的时候:i=0,j=A.length-1;
2以第一个数组元素作为关键数据,赋值给key,即key=A[0];
3从right开始向前查找,找到第一个小于key的值A[j],将A[right]和A[left]互换;
4从left开始向后搜索,找到第一个大于key的A[left],将A[left]和A[right]互换;
5重复以上3 4。
快速排序是一种不稳定的排序方法,在排序过程中相同的数字的顺序可能会发生变化。
9 若有说明:int a[3][4];,则对 a 数组元素的正确引用是( )。
A a[2][4]B a[1,3]C a[1+1][0]D a(2)(1)
分析:数组的下标是从0开始的A选项越界了,其他选项格式错误。
10 数组A的每个元素需要4个字节存放,数组有8行 10列,若数组以行为主顺序存放在内存SA开始的存储区中,则A中8行5列的元素的位置是
SA+74SA+292SA+296SA+300
分析:公式为 初始位置+((行数-1)*列数+最后一行列数)*(sizeof(类型))前7行除了第一行是从第二个数开始,其他的行都是满的因此列式为((8-1)*5+5-1)sizeof(int )=296,所以位置是SA+296。
11若有定义"char a [10], *p=a; ”,那么下列赋值语句正确的是( )。
a [] ="abcdefg";a=”abedefg";*p=”abcdefg";p=”abcdefg ";
分析:数组不能先定义在赋值,正确的方式是:char a[10]="abcdefg",
a表示的是a数组首元素的地址,地址是一个常量,不能给常量赋值。
*p是指针地址变量,里面存放的是地址
12.在定义 int a[3][4][2]; 后,第 20 个元素是( )
a[2][1][1]a[1][0][1]a[2][0][1]a[2][2][1]
分析:总共有(0~2)3层,每层可以看成是一个二维数组(如b[4][2]),有4*2=8个元素。前两层总共有16个元素,所以第20个元素应该在第三层(下标为2).20-16=4还差4个元素,所以第三层中(例如二维数组b[4][2])第四个元素的位置为b[1][1]所以第20个元素是a[2][1][1].
13 广义表中的元素或者是一个不可分割的原子,或者是一个非空的广义表(B)
A 对B 错
分析:广义表的元素可以为空。
14 下面有关数据结构的说法是正确的(A)?
A 数组和链表都可以随机访问B 数组的插入和删除可以 O(1)C 哈希表没有办法做范围检查D 以上说法都不正确
分析:
数组可以通过下标直接获取到,链表的地址存放在前一个数中,因此必须获取到前面数字的地址;
数组元素在栈区,链表元素在堆区;数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n);
在数组的最后一位的后面插入与删除可以O(1)。
15.以下能对一维数组 a 进行正确初始化的语句是(ABC)
A int a[10]={0, 0, 0, 0, 0};B int a[10]={ };C int a[]={0};D int a[10]={10*a};
分析:
1 int a[10] = {0,0,0,0,0};//随后元素补零
2 int a[10] = {1,2}//编译器自动计算元素个数,相当于a[2] = {1,2};
3 int a[] = {0}//编译器自动计算元素个数
16.
已知数组D的定义是int D[4][8];,现在需要把这个数组作为实参传递给一个函数进行处理。下列说明汇总可以作为对应的形参变量说明的是(CD)。
int D[4][]int *s[8]int(*s)[8]int D[][8]
分析:
int *s[8]; //定义一个指针数组,该数组中每个元素是一个指针,每个指针指向哪里就需要程序中后续再定义了。
int (*s)[8]; //定义一个数组指针,该指针指向含8个元素的一维数组(数组中每个元素是int型)。
区分int *p[n]; 和int (*p)[n]; 就要看运算符的优先级了。
int *p[n]; 中,运算符[ ]优先级高,先与p结合成为一个数组,再由int*说明这是一个整型指针数组。
int (*p)[n]; 中( )优先级高,首先说明p是一个指针,指向一个整型的一维数组。
C是数组指针,每个都指向对应的数组的每列,数组作为实参时必须指定列数,否则可能产生歧义。
下列叙述哪些是对的?(CD)
A 线性表的逻辑顺序与物理顺序总是一致的。B 线性表的顺序存储表示优于链式存储表示。C 线性表若采用链式存储表示时所有结点之间的存储单元地址可连续可不连续。D 二维数组是每个元素都为顺序表的顺序表 .E 每种数据结构都应具备三种基本运算:插入、删除和搜索。
分析:A:线性表分为顺序表和链表,顺序表逻辑顺序与物理顺序总是一致的,但是链表储存顺序的不一定是连续的
E:栈没有搜索操作