强化学习卡之Maltab/Simulink实现
1. 建立环境
a. 建立动作和观测对象
动作和观测可以分为两种:rlNumericSpec和rlFiniteSetSpec。
- rlNumericSpec:代表连续的动作或观测数据。
- rlFiniteSetSpec:代表离散的动作或观测数据。
代码如下:
obsInfo = rlNumericSpec([3 1],… % 创建一个3x1的观测矩阵
'LowerLimit',[-inf -inf 0 ]',...
'UpperLimit',[ inf inf inf]');
obsInfo.Name = 'observations';
obsInfo.Description = 'integrated error, error, and measured height';
numObservations = obsInfo.Dimension(1); % 取观测矩阵的维度
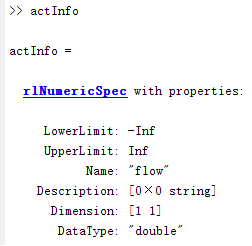
actInfo = rlNumericSpec([1 1]);
actInfo.Name = 'flow';
numActions = actInfo.Dimension(1);
在命令行窗口输入obsInfo,输出如下:

在命令行窗口输入actInfo,输出如下:
b. 建立环境交互对象
使用rlSimulinkEnv函数建立环境交互对象,使用方法如下:
env = rlSimulinkEnv(mdl,agentBlock,obsInfo,actInfo)
代码如下:
env = rlSimulinkEnv('rlwatertank','rlwatertank/RL Agent',obsInfo,actInfo);
设置一个自定义的复位函数,在每回合开始的时候给予模型一个随机的参考值。
env.ResetFcn = @(in)localResetFcn(in);
@为创建一个函数句柄
in只是localResetFcn输入和输出参数名
定义localResetFcn函数如下:
function in = localResetFcn(in)
% randomize reference signal blk = sprintf('rlwatertank/Desired \nWater Level'); % 把参考信号的地址转化为字符串
h = 3*randn + 10; % randn为符合正太分布的随机数
while h <= 0 || h >= 20
h = 3*randn + 10;
end
in = setBlockParameter(in,blk,'Value',num2str(h)); % 输出参考信号的值
% randomize initial height h = 3*randn + 10;
while h <= 0 || h >= 20
h = 3*randn + 10;
end
blk = 'rlwatertank/Water-Tank System/H'; % 把水位高度的地址赋给blk
in = setBlockParameter(in,blk,'InitialCondition',num2str(h)); % 输出
end
定义仿真时间步长和agent采样步长(单位:秒)
Ts = 1.0;
Tf = 200;
固定随机数的种子以重复生成
rng(0)
c. 创建DDPG agent
i. 首先建立一个深度神经网络,它具有2个输入(观测和动作)和1一个输出,代码如下:
1. statePath = [
2. imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
3. fullyConnectedLayer(50,'Name','CriticStateFC1')
4. reluLayer('Name','CriticRelu1')
5. fullyConnectedLayer(25,'Name','CriticStateFC2')];
6. actionPath = [
7. imageInputLayer([numActions 1 1],'Normalization','none','Name','Action')
8. fullyConnectedLayer(25,'Name','CriticActionFC1')];
9. commonPath = [
10. additionLayer(2,'Name','add')
11. reluLayer('Name','CriticCommonRelu')
12. fullyConnectedLayer(1,'Name','CriticOutput')];
13. criticNetwork = layerGraph();
14. criticNetwork = addLayers(criticNetwork,statePath);
15. criticNetwork = addLayers(criticNetwork,actionPath);
16. criticNetwork = addLayers(criticNetwork,commonPath);
17. criticNetwork = connectLayers(criticNetwork,'CriticStateFC2','add/in1');
18. criticNetwork = connectLayers(criticNetwork,'CriticActionFC1','add/in2');
查看神经网络的结构
1. figure
2. plot(criticNetwork)
ii. 创建评价表示
设置学习速度、梯度下降速率,将其与相应的动作和观察相连
1. criticOpts = rlRepresentationOptions('LearnRate',1e-03,'GradientThreshold',1);
2. critic = rlRepresentation(criticNetwork,obsInfo,actInfo,'Observation',{'State'},'Action',{'Action'},criticOpts);
iii. 创建动作表示
DDPG agent通过动作表示来决定采取哪一个动作。
首先要创建一个以观测为输入、动作为输出的深度神经网络。
1. actorNetwork = [
imageInputLayer([numObservations 1 1],'Normalization','none','Name','State')
fullyConnectedLayer(3, 'Name','actorFC')
tanhLayer('Name','actorTanh')
fullyConnectedLayer(numActions,'Name','Action')
];
2. actorOptions = rlRepresentationOptions('LearnRate',1e-04,'GradientThreshold',1);
3. actor = rlRepresentation(actorNetwork,obsInfo,actInfo,'Observation',{'State'},'Action',{'Action'},actorOptions);
iv. 创建DDPG agent
1. agentOpts = rlDDPGAgentOptions(...
2. 'SampleTime',Ts,...
3. 'TargetSmoothFactor',1e-3,...
4. 'DiscountFactor',1.0, ...
5. 'MiniBatchSize',64, ...
6. 'ExperienceBufferLength',1e6);
7. agentOpts.NoiseOptions.Variance = 0.3;
8. agentOpts.NoiseOptions.VarianceDecayRate = 1e-5;
9. agent = rlDDPGAgent(actor,critic,agentOpts);