如何评价1700亿参数的GPT-3?
作者:李如
链接:https://www.zhihu.com/question/398114261/answer/1253942032
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
- 对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
- 对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
为了达到上述目的,作者们用预训练好的GPT-3探索了不同输入形式下的推理效果:

这里的Zero-shot、One-shot、Few-shot都是完全不需要精调的,因为GPT-3是单向transformer,在预测新的token时会对之前的examples进行编码。
作者们训练了以下几种尺寸的模型进行对比:

实验证明Few-shot下GPT-3有很好的表现:
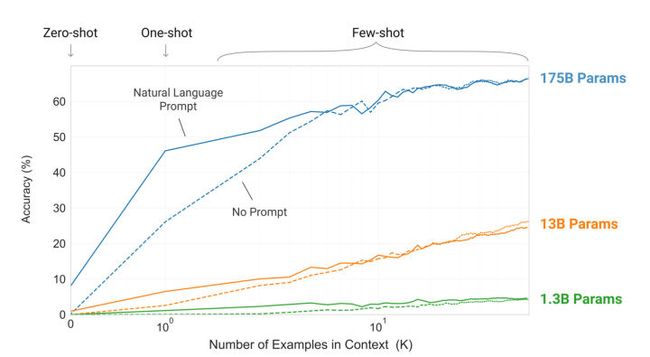
最重要的是,GPT-3的few-shot还在部分NLU任务上超越了当前SOTA。该论文长达72页(Google T5是53页),第10页之后都是长长的实验结果与分析。
显然,GPT-3的模型参数、训练数据和工作量都是惊人的,论文署名多达31个作者,所有实验做下来肯定也耗费了不少时间。虽然一直都存在对于大模型的质疑声音,但我们确确实实从T5、GPT-3这样的模型上看到了NLP领域的进步,众多业务也开始受益于离线或者线上的BERT。事物的发展都是由量变到质变的过程,感谢科研工作者们的不懈努力和大厂们的巨额投入,奥利给。
GPT-3诞生,Finetune也不再必要了!NLP领域又一核弹!mp.weixin.qq.com
编辑于 05-30
作者:李渔
链接:https://www.zhihu.com/question/398114261/answer/1275545519
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这是一件值得我们在战略上重视的事。
抛开 GPT-3 这项工作的具体发现不谈,简单说一说这项工作给我带来的担忧:
1、AI 领域的科研垄断似乎正在形成
刚听说了 OpenAI 出了 1700 亿参数的 GPT-3 时,给我的感受就好像是,我们还在琢磨怎么用好 100 nm 工艺线研发芯片时,别人已经宣布跑通 9 nm 工艺线了。这种震惊相信芯片领域的同学有切身的感受。 保守估计,GPT-3 的训练费用在数百万美金到千万美金之间,显然这样的花销国内很难有团队可以承受。那么在算力这个层面,科研垄断已经形成了。
再回到芯片领域,由于长期缺乏足够的资金支持同时很少接触到先进的工艺线,国内很多研究人员(既包括高校,也包括企业)长期只能做电路的理论分析和仿真研究,长期处在低水平的探索中,导致很难在芯片领域做出突破性的成果。
记得五年前,我在知乎上分享了一项有关世界上第一款光电混合CPU的研究,这个工作由 UC Berkeley, MIT & University of Colorado Boulder 研究人员共同完成,在当年的 Nature 上进行了报道。简而言之,他们第一次在微电子标准 CMOS 工艺下,利用IBM商用的 45 nm 工艺线实现了光电混合集成的 CPU。然而,五年过去,依然没有听到国内有哪家单位在做。而对方已经创业,开始尝试将这一技术应用到数据中心中。
如果接下来几年类似 GPT-3 这样的超大规模模型依然只是被少数几家强 AI 机构垄断,那么芯片领域的当下局面很有可能出现在 AI 领域。
2、长期的算力垄断很有可能带来系统性的AI技术垄断
可能有一些同学会说,上面说的未免有点杞人忧天,毕竟这么重的 GPT-3 在实际中连拿来 inference 都不太可能。 但是我们看 GPT-3 的文章会发现,这是一项系统工程。前面
@王星
答主也提到,单是作者贡献就单独列了一页。显然,GPT-3 是一项很有挑战的工程项目。一项有挑战的工程项目的完成,不论本身是否具有重要用途,在完成挑战过程中所突破的种种技术问题,就是一笔巨大的财富。比如,在训练过程中,如何在集群上实现超大规模参数的高效更新,如何处理梯度传播等等。
用阿波罗登月计划做一个不完全恰当的类比。抛开阿波罗登月计划对于美国在冷战期间的政治意义不谈,单就整个项目期间,研究人员在空间通信、材料科学、自动控制、集成电路、计算机科学方面所取得的种种技术突破,对后来美国多个民用领域的发展都起到了很大的推动作用。
GPT-3 仅仅只是一个开始,随着这类工作的常态化开展,类似 OpenAI 的机构很可能形成系统性的AI技术垄断。
一不留神多说了几句,总之,我们至少应该在战略上重视这个工作。
发布于 06-10
作者:袁进辉
链接:https://www.zhihu.com/question/398114261/answer/1254296176
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
英伟达副总裁 Bryan Catanzaro :computation power make human ingenuity the limiting factor for AI research & development
中文:计算力 让人工智能研究 只有想不到,没有做不到

原版


编辑于 05-30
简单说三点和技术关系不大的:
- GPT-3可能还是无法帮助OpenAI盈利,也无法直接上线显著造福网民,但是从中积累的大模型训练经验是OpenAI和他背后的微软Azure一笔巨大的财富。这就像,人类登上火星/月球可能并不能带来直接的资源收益,但是从中积累的科学技术却可以推动人类社会的发展。
- 我个人很喜欢大力出奇迹的工作,现在的NLP预训练如同中国的古话“熟读唐诗三百首,不会作诗也会吟”。我希望大家不要“看不上”这样的工作,并觉得给我卡我上我也行。NLP大规模预训练至少面临着:模型大了容易训崩(虽然我也不知道为什么,但是大Transformer就是会在某一个点突然模型Loss骤增)、模型并行容易有坑、训着训着机器坏了的容错问题。
- 我的回答一直强调,NLP的同学们,尤其是年轻的同学们,要去大厂、有资源的地方。虽然有了资源不一定行,但是没有资源现在肯定是不行了。
发布于 05-30
作者:Dr.Wu
链接:https://www.zhihu.com/question/398114261/answer/1254692810
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:王星
链接:https://www.zhihu.com/question/398114261/answer/1253480720
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
第一次看挂这么多名字的论文详细地写Author contributions
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, and Jeffrey Wu implemented the large-scale models, training infrastructure, and model-parallel strategies.
Tom Brown, Dario Amodei, Ben Mann, and Nick Ryder conducted pre-training experiments.
Ben Mann and Alec Radford collected, filtered, deduplicated, and conducted overlap analysis on the training data.
Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, and Girish Sastry implemented the downstream tasks and the software framework for supporting them, including creation of synthetic tasks.
Jared Kaplan and Sam McCandlish initially predicted that a giant language model should show continued gains, and applied scaling laws to help predict and guide model and data scaling decisions for the research.
Ben Mann implemented sampling without replacement during training.
Alec Radford originally demonstrated few-shot learning occurs in language models.
Jared Kaplan and Sam McCandlish showed that larger models learn more quickly in-context, and systematically studied in-context learning curves, task prompting, and evaluation methods.
Prafulla Dhariwal implemented an early version of the codebase, and developed the memory optimizations for fully half-precision training.
Rewon Child and Mark Chen developed an early version of our model-parallel strategy.
Rewon Child and Scott Gray contributed the sparse transformer.
Aditya Ramesh experimented with loss scaling strategies for pretraining.
Melanie Subbiah and Arvind Neelakantan implemented, experimented with, and tested beam search.
Pranav Shyam worked on SuperGLUE and assisted with connections to few-shot learning and meta-learning literature.
Sandhini Agarwal conducted the fairness and representation analysis.
Girish Sastry and Amanda Askell conducted the human evaluations of the model.
Ariel Herbert-Voss conducted the threat analysis of malicious use.
Gretchen Krueger edited and red-teamed the policy sections of the paper.
Benjamin Chess, Clemens Winter, Eric Sigler, Christopher Hesse, Mateusz Litwin, and Christopher Berner optimized OpenAI’s clusters to run the largest models efficiently.
Scott Gray developed fast GPU kernels used during training.
Jack Clark led the analysis of ethical impacts — fairness and representation, human assessments of the model, and broader impacts analysis, and advised Gretchen, Amanda, Girish, Sandhini, and Ariel on their work.
Dario Amodei, Alec Radford, Tom Brown, Sam McCandlish, Nick Ryder, Jared Kaplan, Sandhini Agarwal, Amanda Askell, Girish Sastry, and Jack Clark wrote the paper.
Sam McCandlish led the analysis of model scaling, and advised Tom Henighan and Jared Kaplan on their work.
Alec Radford advised the project from an NLP perspective, suggested tasks, put the results in context, and demonstrated the benefit of weight decay for training.
Ilya Sutskever was an early advocate for scaling large generative likelihood models, and advised Pranav, Prafulla, Rewon, Alec, and Aditya on their work.
Dario Amodei designed and led the research.
发布于 05-29
作者:量子超感
链接:https://www.zhihu.com/question/398114261/answer/1253410132
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. 炼丹师们以后连自黑调参侠也不敢了。
GPT-2 (参数15 亿)、Megatron-BERT(80 亿参数)、Turing NLG(170 亿参数),而GPT-3直接1700亿个参数。
当然,GPT-3不需要fine-tune,就能具有非常好的效果。
2. 当下入坑DL建议:穷搞理论,富搞预训练。(雾)
Google的T5论文的一页实验烧了几百万美元,当时看起来已经是壕无人性了,但背靠MS的OpenAI的GPT-3需要的GPU算力是BERT的近2000倍,训练成本保守估计一千万美元,以至于训练出了一个bug也无能无力,论文只能拿出一部分篇幅研究了这个bug会有多大影响。
Unfortunately, a bug in the filtering caused us to ignore some overlaps, and due to the cost of training it was not feasible to retrain the model.
不幸的是,过滤中的一个bug导致我们忽略了一些(训练集与测试集的)重叠,由于训练的成本的原因,重新训练模型是不可行的。
3. GPT-3对NLP和DL的意义还是非常重大的。
NLP可以说是实现AGI的最大难题,NLP的突破需要一个效果很好且通用的模型,GPT-3依凭借巨大的参数与算力已经极力接近这样的性质,在许多任务上(如翻译、QA和文本填空任务)拥有出色的性能甚至取得了SOTA。
然而,GPT-3还是存在一些局限,论文作者给出了未来有前景的方向:
- 建立GPT-3尺度的双向模型。
- 使双向模型能在少样本、零样本学习上工作。
4. 数据、模型、算力,三大要素,缺一不可,但算力还是王道:
畅想一下:几十年后,算力暴涨,如同今天的入门DL的本科生训练MNIST一样,那时的本科生深度学习第一章课后作业:复现一下T5和GPT-3。
NVIDIA YES!
编辑于 06-04
作者:二元倒回改造架构
链接:https://www.zhihu.com/question/398114261/answer/1264613526
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
看了些GPT3的文本生成样例,还挺有意思的。不过生成的东西还是漏洞频频,没有大家想象的那么强。
https://raw.githubusercontent.com/openai/gpt-3/master/175b_samples.jsonlraw.githubusercontent.com
GPT-3总体上来说,写的故事还是不错了。看起来比较真实,读起来也很有感觉。以下我仔细分析了GPT-3的几篇文章。第一篇讲中国的文章中,拿中国治安很好和美国枪支泛滥做对比,读起来好像作者真的是美国人似的。第三篇的推特爱情故事,真实地展现了Brandon Flowers几天的推文。虽然日期有些杂乱,但是大体上的内容非常真实。除了情情爱爱的套话之外,还刻画了邀请朋友来婚礼等生活细节,看起来饶有趣味。
GPT-3写的一个文章最大优点是都紧扣了主题。之前GPT-2的文章有时候写着写着就讲到另外一件事去了,而GPT-3改善了很多,至少在我看的几篇文章中都没有出现这种情况。
模型的好坏还和我们的评判标准有关。假如我们把GPT-3看成是一个小孩子,那么它能写出如此流畅、真实的文章,已经是令人惊喜了。但是,联想到其1000万美元的训练价格,我还是想严苛那么一下下,仔细找些文章挑出骨头来。
以下是文章展示和挑刺环节。其中我认为有问题的部分用黑体标出:
- GPT-3也是个“中吹”
GPT-3讲述了一个外国人对中国人的喜爱和夸赞:
Trixie Textured - My cat licked my thumb.
Join Date: Nov 2006 Posts: 4,592
I have not been to China, though I have been to Japan and love it.
I have friends in China who have also been to Japan, and they both love it, and neither of them think of it as a \"poor\" country. In fact, a lot of people who have been there say that China is much nicer.
China is not a poor country. They have tons of money and resources. Their problem is that they do not spend enough on infrastructure and don't value education as highly as they could. So their people do not make as much money as they could. And they don't have nice things. It is much nicer than India, but not as good as Japan. I would like to visit it, because I do not think I would be disappointed, but I don't expect it to be better than Japan.
They have a different mindset than us, and do things differently. Their government is not a democracy. It is a communist government. I think that is not a bad thing, and has it's benefits. They have much fewer guns and gun crime than we do. They are, for the most part, more honest than we are. Their infrastructure, while not as nice as ours, is very good. They spend more on infrastructure than we do. They have much more public transportation, and better public transportation. They are working on their environmental problems, and they have made more progress than we have. They have fewer social problems, and less crime than we do. They have a very good education system, especially compared to India.
They spend more money on schools and education, and invest more in their future, than we do.
China is a country that is far more well developed than many people in the US would think.
The fact that they have fewer guns, and better education and fewer social problems is probably why they have fewer school shootings than we do. I think we have way too many guns in this country, and that is a big part of the problem.
Just my thoughts.
乍一看挺流畅的,不过仔细琢磨还是能看出不少前后不一致的地方。例如一开始讲到中国和日本两个国家时,指代有些杂乱。第一次讲"poor country"指代日本,第二次讲的时候不知怎么又拿来指代中国了。后面讲到infrastructure和education,前面一顿贬,后面竟然又自相矛盾地跨起来了。说明GPT-3虽然有一千多亿参数,但是文字功底还是只停留在符号层面,逻辑基础比较差。
2. GPT-3也会Arduino
GPT-3写了一篇Arduino教程:
Arduino
The Arduino is a small microcontroller, the key component for any hardware project. It allows you to interact with the real world with the help of sensors.
As you might know, the Arduino doesn’t come alone, it needs a small piece of hardware called the USB/serial converter to be able to interact with your computer and communicate with the Arduino.
By default the Arduino only comes with an Atmega328. This is a pretty good chip, as it can run up to 20MHz, has lots of RAM (32kB), lots of IO pins ( 20) and lots of serial ports (4).
We can still upgrade the Arduino with a more powerful chip, like the Atmega2560 ( 60MHz, lots of RAM, lots of IO pins and serial ports), the Atmega1280 ( 80MHz, lots of RAM, lots of IO pins and serial ports) or the Atmega2561 ( 62.5MHz, lots of RAM, lots of IO pins and serial ports).
As you can see, the difference between these chips is the speed (Mhz) and the amount of RAM.
The choice between the other 3 chips depends on the project you’re going to use the Arduino for. If you need a high speed for something like an audio or video streaming application, you should go for the Atmega2560 or Atmega2561. If you need a lot of IO pins for some digital inputs and outputs, you should go for the Atmega1280.
The first Arduino board I have made has a Mega2560 on it, so that’s what we’re going to be using. The pins can be easily set in a manner that suits the hardware project, and there are lots of examples and examples on the internet for lots of projects.
I2C, SPI
If you plan to use the Arduino to connect your hardware projects to a PC, you will need an extra cable. One that has the 2 signals to use with the Arduino (I2C or SPI) and another one to use with your PC (serial). This is what I will be using for this project, and I highly recommend it to anyone else who plans to do the same.
Here is an example of such a cable.
That’s it for today, stay tuned for the next part in which I will be adding code to control the LEDs and adding more control buttons.
这篇讲得头头是道的,我原来以为应该不会错吧,毕竟训练数据里有关Arduino的资料肯定不少。但是仔细一查,发现Atmega328的IO口数量没写对,Atmega2560/1280/2561的频率都写错了。不过毕竟GPT-2也没有上网查资料,这些还是值得原谅的。
但是写出“lots of examples and examples”这种赘余的文字就不应该了(我专门去谷歌搜了一下,并没有examples and examples这种写法)。这也是语言模型的一个通病了吧,之前用GPT-2的时候。跑出来的结果中出现通篇重复文字的概率不小(即相同的一个或几个单词无限循环输出)。GPT-3也有少量通篇重复的,我这里就不放出来了。
3. GPT-3也会虐狗
GPT-3讲述了一段推特爱情故事:
There’s nothing more adorable than a real life couple who gush over one another on social media and share the same love story. What’s even more adorable is when you know that they found each other through social media.
Take Brandon Flowers and his wife, Tana. The two met on Twitter and now, they’re celebrating their five year anniversary. If you follow either of their social media accounts, you may have noticed some cute posts from them about their relationship. We want to thank them for allowing us to have a look into their love story, because they’re too cute!
As fans of The Killers, we love hearing about their adventures.
They’re pretty cute!
T here’s nothing more adorable than a real life couple who gush over one another on social media and share the same love story. What’s even more adorable is when you know that they found each other through social media.
Take Brandon Flowers and his wife, Tana. The two met on Twitter and now, they’re celebrating their five year anniversary. If you follow either of their social media accounts, you may have noticed some cute posts from them about their relationship. We want to thank them for allowing us to have a look into their love story, because they’re too cute!
As fans of The Killers, we love hearing about their adventures.
They’re pretty cute!
I'd just like to say that my wife is everything. — Brandon Flowers (@flowerboy) August 5, 2017
Wedding Day. Not on social media. So I don't know what people think. I know my wife is everything. That's all I need. — Brandon Flowers (@flowerboy) August 5, 2017
On the last night of a tour, getting some wife-y kisses. And in case anyone was wondering. This is how we roll. pic.twitter.com/zSXlfUgKXd — Brandon Flowers (@flowerboy) August 7, 2017
Oh yeah. Still be on tour, still be making music. Not yet a father, but that's coming. Still have some things left to do. https://t.co/CJ1vOs8lYA — Brandon Flowers (@flowerboy) August 7, 2017
Yes. It's true. I am getting married. And I'm marrying my best friend. And my favorite person. https://t.co/uOe3DjtMtQ — Brandon Flowers (@flowerboy) August 5, 2017
The next night, he admitted that he has not yet become a father, but he is working on it.
Didn't say I was a father yet. Wasn't pregnant before. Wasn't even married. But I love my wife and my future kids. pic.twitter.com/uVEXZHScGz — Brandon Flowers (@flowerboy) August 6, 2017
Yep. Only day two and already love you so much more than I did yesterday. No, that's not enough. Still not enough. pic.twitter.com/cItd8b8HxY — Brandon Flowers (@flowerboy) August 8, 2017
You are a goddamn genius. No one can make me laugh like you. — Brandon Flowers (@flowerboy) August 8, 2017
The next day, Brandon shared the first picture of the newlyweds.
Tana and I on our wedding day. pic.twitter.com/6R5xT0P5zT — Brandon Flowers (@flowerboy) August 7, 2017
I can't wait to see you two together at our wedding. — Brandon Flowers (@flowerboy) August 7, 2017
I love my wife and I'm going to spend the rest of my life loving her. https://t.co/2h7LXqHxjC — Brandon Flowers (@flowerboy) August 7, 2017
Brandon gave a shout out to his brother and the rest of the band for not spoiling their special day.
This is how much I love my wife. I would've wanted to come here tonight. But I didn't. https://t.co/ox7XY3sPGO — Brandon Flowers (@flowerboy) August 8, 2017
Just a normal day. A normal day with my wife. She is my favorite person in the world. We have no plans. pic.twitter.com/vNNkIOCcUQ — Brandon Flowers (@flowerboy) August 8, 2017
Curious to see the rest of their love story?
Happy 5 years to the love of my life, my best friend and my favorite person. I still feel like I'm the luckiest"..............
这篇文章一开头就把同样的文字重复了两遍,不知道是不是因为训练语料没洗干净,也有相同的情况。后面的推文也没有按照时间顺序排,出现了8月7日-8月5日-8月6日这样的奇怪顺序。"Wasn't pregnant before. Wasn't even married."这两句也很奇怪。怎么会讨论一个大男人怀不怀孕呢,而且不是已经结婚了吗?
综上,预训练模型其实还有很大的空间。这次OpenAI用了那么多数据和参数量,训练出来的模型仍然不完美。希望能有天才的研究者从另一个角度找到更好的答案吧。
编辑于 06-07
作者:pymars
链接:https://www.zhihu.com/question/398114261/answer/1261498248
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
评价就是:
1、这下彻底玩儿不起了,以前的bert虽然很大,一般人训练不起,但用别人预训练好的模型来应用于自身任务还是可以的,而gpt-3的大模型基本上是用都用不起了。
2、openAI一致在gpt的架构上一条道走到黑,还能每次都出一些新东西,也是很佩服
3、论文第4页的这个图充分说明了量变引起的质变

4、不知道多少人关注到论文29页的这个部分:

翻译一下大概是这样:

我想上面的例子一定程度上说明:GPT-3初步具备了“理解”的能力,之前的各种大模型虽然在各种任务上效果好,但更多的还是偏向“记忆”,而如何让模型具备理解的能力一直是很多前沿NLP研究者在思考的问题。在这之前,多数的想法还是从算法和模型层面去思考可能性,如果上面截图不是特例,GPT-3真的初步具备这种理解能力,我想对于NLP的发展而言,这可能就是一个里程碑式的拐点,就像imagenet数据集对图像处理领域的意义一样。
编辑于 06-03
作者:我的土歪客
链接:https://www.zhihu.com/question/398114261/answer/1294202280
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
两年下来,GPT已经不仅仅只是个模型了。我想试着从心态、技术和商业三个角度谈谈它的影响。
这是一个极度容易让人“心态爆炸”的模型
CloseAI(不好意思打错了,我是说OpenAI)不久前“释出”(之所以打引号是因为目前我们只能看不能用)了GPT-3模型。在language model竞赛中,它也就“又大了一点点”吧:1750亿参数、31位作者、72页论文,训练下来大约花了1200万刀[1]。(望向脚边机箱里的2080Ti:“要认清自己的能力,不要总还想着在NLP上搞个大新闻,EPIC Games每周限免他不香吗?”
Epic Games Store | Official Sitewww.epicgames.com
这是一个对“大力出奇迹”有着坚定信心的技术实践
调侃完毕,我们来简单梳理下GPT贯穿始终的目的和其从1到3一路走来的发展脉络:
总体上看,GPT的目的一直非常明确,就是想证明“大力出奇迹”的猜想。即在大的数据集上做无监督训练,是不是当数据大到一定程度时,就不需要在具体且繁多的下游任务上做监督、微调之类的事情了?
具体来看:
- 2018年6月 GPT-1:大量数据(约5GB文本)上无监督训练,然后针对具体任务在小的有监督数据集上做微调;关键词:“scalable, task-agnostic system”;8个GPU上训练一个月;预训练模型(1.1亿参数)可下载;
Improving Language Understanding with Unsupervised Learningopenai.com
- 2019年2月 GPT-2:大量数据(约40GB文本)上无监督训练,然后针对具体任务在小的有监督数据集上做微调,尝试在一些任务上不微调(即使结果离SOTA还远);关键词“without task-specific training”;据说在256个Google Cloud TPU v3上训练,256刀每小时,训练时长未知[2];预训练模型(15亿参数)最终公开可下载;
https://openai.com/blog/better-language-models/openai.com
- 2020年5月 GPT-3:大量数据(499B tokens)上无监督训练,不微调就超越SOTA;关键词“zero-shot, one-shot, few-shot”;训练据说话费1200万刀;1750亿参数,将会开放付费API。
72页论文我既没精力也没心力读下来,因此推荐这篇总结博文:
GPT-3, a Giant Step for Deep Learning and NLPanotherdatum.com
简单来讲,GPT-3一定程度上证明了大力真的可以出奇迹,无需fine-tuning就能在下游任务中“大显神威”。GPT-3的关注点在zero-shot、one-shot和few-shot学习,它证明了一个足够大的模型在训练时可以获得更宽泛的NLP“技能”和模式识别的能力,这些能力使它在推断时可以迅速地适应或识别出下游任务。

说点感性上的感受:词嵌入、语义等的核心我认为是context,context可以翻译成“上下文”,这个翻译用来理解word2vec或language modeling等都非常直观。当然context也可以翻译为“语境”,语境是一个更宏大的词,是一种对更宽泛环境的理解能力。对于人来说,能感知并理解语境需要强大的能力,往往基于广泛的阅读,但人的阅读能力总是有极限的。GPT想证明的事情,像是人类对基于广泛阅读的语境理解能力的极限探索。
比起技术的成熟,它在商业上还是个“萌新”
还好GPT-3也不是样样都行,至少它在商业上还是个“萌新”,这多多少少给我们早已“爆炸”的心态带来了些许安慰。
先看OpenAI几个商业上的时间点:
- 2015年10月 创立;非盈利
- 2018年2月 Musk退出董事会
- 2019年3月 成立OpenAI LP[3],他们自己所谓的“a hybrid of a for-profit and nonprofit”,这不重要,重要的是他们开始需要为投资人的钱负责了
- 2019年7月 微软投资10亿刀[4]
拿这个时间线对照GPT时间线,或许有助于我们从另一个方向理解GPT的一些选择:
比如GPT-2刚官宣时的争议。众所周知,GPT-2的完整模型一开始是没有被公开的,官方博客的解释是:
Due to our concerns about malicious applications of the technology, we are not releasing the trained model. [5]
因为怕这个强大的模型被滥用,官方决定公布一个较小的模型。(CloseAI的外号就是这么来的。)
我们看下GPT-2推出的时间,2019年2月。OpenAI 一个月后就改变架构、成立以盈利为目的OpenAI LP,5个月后获得微软投资。
我们有理由相信GPT-2公布时、甚至训练时OpenAI非盈利的组织架构就已经快玩儿不转了。不公布模型,一方面是作为非营利组织心系天下、有社会责任感的“最后的倔强”;另一方面也为下一步作为需要盈利的公司给投资人有个交代、争取商业合作、获得融资等提供了想象空间。(毕竟,因为如果直接开源,GPT-2的商业价值就极其有限了。)
到了GPT-3的时代,OpenAI选择将其作为一个付费API(或者说一种服务)来让大家使用,这是OpenAI LP获得微软投资后的一步重要商业化实践。背靠微软这棵大树,用Azure云计算技术训练模型,基于Azure提供API服务,甚至连注册API的线上问卷也用的是Microsoft Forms。
个人认为商业化是非常好的事情,对AI真正落地会产生积极影响。如果把金钱看作全球普遍接受的、有统一标准的评价方法,那GPT-3在NLP任务上斩获无数SOTA后,下一关,就是看它在盈利上是否同样可以获得SOTA了。
BTW,目前这个API服务还未上线,感兴趣的朋友可以通过填写这个线上问卷加入OpenAI API Waitlist。
OpenAI API Waitlistforms.office.com
参考
- ^https://venturebeat.com/2020/06/01/ai-machine-learning-openai-gpt-3-size-isnt-everything/
- ^https://www.theregister.com/2019/02/14/open_ai_language_bot/
- ^https://openai.com/blog/openai-lp/
- ^https://openai.com/blog/microsoft/
- ^https://openai.com/blog/better-language-models/
编辑于 06-22
作者:饭饭
链接:https://www.zhihu.com/question/398114261/answer/1364185395
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GPT-3我还没申请到试用。最近PR一把火了。其实GPT-2已经算是Few-shot learner了,GPT-3把这个再次扩展到极致。效果方面我不多做赘述,但我想说说这里面,设计Few-shot learner,或者Meta Learner的路线之争,也就是
Recurrence Based Meta Learning 和 Gradient Based Meta Learning的路线之争
Gradient Based Meta Learning,以MAML[1]为代表, 指的是,针对不同的任务,它的Adaption过程,是通过少量样本的梯度迭代, 实现对新任务的适配
Recurrence Based Meta Learning, 以SNAIL[2] 为代表, 它针对不同的任务,不需要梯度迭代,只需要Forward, 或者将样本Encoding进去就能学习。
也许有的朋友说,我没看到 GPT-3做了什么Meta Learning的事情啊?它就是个Language Model啊?
不了解的朋友可以先看下Recurrence based Meta Learning的鼻祖。它就是一个LSTM,把 就这么一个个Encode进去,它就是一个Meta Learner了
神奇不?
过去一段时间,MAML一直牢牢占据Meta Learning的主流,因为Recurrence based一直效果不好
如果GPT-3和BERT刚好代表Recurrence based和Gradient based两种方法
那GPT-3证明了,只要模型够大,Recurrence based meta learning也是可以的!
最后,我广告下这篇文章,在18年开始我就很看好recurrence based meta learning
饭饭:我们离真正的通用人工智能(AGI)到底还缺少了什么?还差多久?zhuanlan.zhihu.com
[1]Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks."arXiv preprint arXiv:1703.03400(2017).
[2] Mishra, Nikhil, et al. "A simple neural attentive meta-learner."arXiv preprint arXiv:1707.03141(2017).
发布于 1 小时前
作者:某霁
链接:https://www.zhihu.com/question/398114261/answer/1257553154
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
小白幻想中,以下为胡扯。
所有人都喜欢 / 希望deep learning学会真正的“知识”,希望deep learning可解释。
然而,deep learning一直希望看齐的人脑不也是一团混沌?人脑可解释了吗?人脑无数神经元一团乱麻,只能非常heuristic地解释一下(其实deep learning也可以非常heuristic地解释),这就算是可解释了吗?人脑也没有像deep learning学者一直希望的那样,具有某种特殊的结构来“学习知识”,人脑就不能学习知识了吗?
会不会其实高参数量、高算力的暴力流就是最贴近人脑的,也是最合适的出路?有没有可能,我们不是应该“设计一个可解释的模型”,而是训练一个“可以解释自己的模型”?(毕竟人脑也是这样的东西)
Update:感觉上述没说清楚,贴一下我在评论区的解释:
大家对待deep learning的态度和对待大脑的态度很不一样;大家都在研究大脑,尊重大脑能够work并研究它如何work;但对于deep learning,大家或者希望人为地“设计”一个易于解释的模型,或者希望对已有模型进行分析、解释其中参数的含义、解释其推理的逻辑,否则就不愿意信任模型,认为模型“其实就是记住了pattern,什么都没学到”。我觉得这是很不公平的,deep learning model类似大脑、有非常大的参数量和冗余连接关系,很有可能就是不可解释的,或者无法像大家期待的那样、像解释传统方法一样解释。
编辑于 06-02