2015-10-23
目录
1.创建索引 CREATE INDEX
2.修改索引 ALTER INDEX
3.删除索引 DROP INDEX
1.创建索引 CREATE INDEX
【语法】CREATE INDEX 官方文档
create_index::=
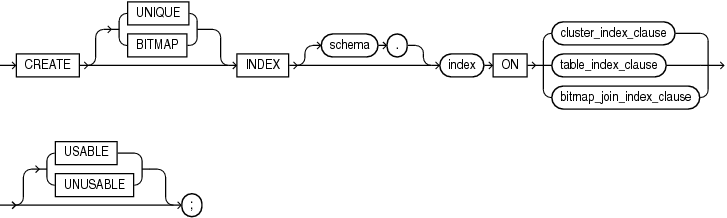


CREATE [ UNIQUE | BITMAP ] INDEX [ schema. ] index ON { cluster_index_clause | table_index_clause | bitmap_join_index_clause } [ USABLE | UNUSABLE ] ;
cluster_index_clause ::=
![]()
CLUSTER [ schema. ] cluster index_attributes
table_index_clause ::=

[ schema. ] table [ t_alias ] (index_expr [ ASC | DESC ] [, index_expr [ ASC | DESC ] ]...) [ index_properties ]
bitmap_join_index_clause ::=
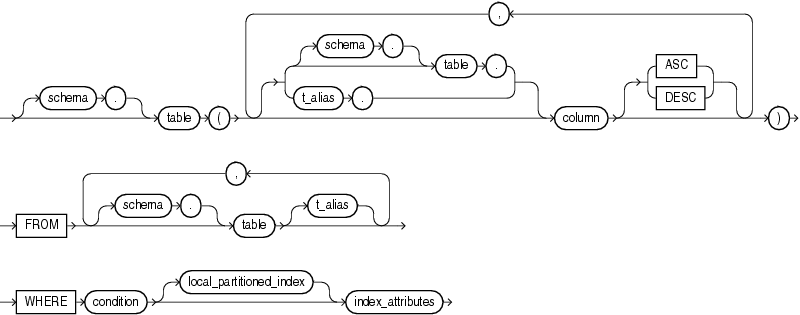
[ schema.]table ( [ [ schema. ]table. | t_alias. ]column [ ASC | DESC ] [, [ [ schema. ]table. | t_alias. ]column [ ASC | DESC ] ]... ) FROM [ schema. ]table [ t_alias ] [, [ schema. ]table [ t_alias ] ]... WHERE condition [ local_partitioned_index ] index_attributes
2.修改索引 ALTER INDEX
【语法】 ALTER INDEX 官方文档
3.删除索引 DROP INDEX
【语法】 DROP INDEX 官方文档
【例子】
索引是oracle的一个对象,是否使用索引由oracle的CBO优化器决定。 一、数据访问方式 1.全表扫描(full table scan) 如果读取表的数据总量超过5%~10%,通常会进行全表扫描,全表扫描采取多块读。 SQL> explain plan for select * from dual; SQL> select * from table(dbms_xplan.display); 2.行id扫描(rowid) 在向表中插入数据时,隐含会创建改行的rowid,rowid是数据行所存储的数据块地址。rowid查找数据采取单块读。 SQL> expalin plan for select * from dept where rowid = 'AAAAyGAADAAAA..'; SQL> select * from table(dbms_xplan.display); 3.索引扫描(index rowid) 索引扫描是通过索引找到数据行的rowid,然后通过rowid直接到表中查找数据。因为一个rowid对应一个数据行,所以这种方式也会采取单块读。 SQL> expalin plan for select * from emp; SQL> select * from table(dbms_xplan.display); 二、索引扫描类型 1.索引唯一扫描(index unique scan) 索引唯一扫描是通过唯一键、主键,返回一个数据行。 SQL> explain plan for select * from emp where empno=10; SQL> select * from table(dbms_xplan.dispaly); 2.索引范围扫描(index range scan) 在唯一键上使用range操作符(>、<、<>、>=、<=、between),在组合索引上只使用部分列查询出多行;对非唯一索引列查询。 SQL> explain plan for select * from emp where empno>18; SQL> select * from table(dbms_xplan.display); 3.索引全扫描(index full scan) 查询出的数据全部从索引得到。 SQL> explain plan for select empno,ename from emp; SQL> select * from table(dbms_xplan.display); 4.索引快速扫描(index fast full scan) 扫描所有数据块,不进行数据排序,可以多块读、并行读。 SQL> explain paln for select empno,ename from big.emp; 三、索引限制条件 1.不等运算 SQL> explain plan for select * from emp where empno<>10; SQL> select * from table(dbms_xplan.display); 2.NULL或IS NOT NULL SQL> select column_name from user_ind_columns where table_name='EMP'; SQL> create index idx_sal_emp on emp(sal); SQL> select column_name from user_ind_columns where table_name='EMP'; SQL> explain plan for select empno,ename,deptno from emp where sal is null; SQL> select * from table(dbms_xplan.display); 3.函数trunc、substr、to_date、to_char、instr等 SQL> explain plan for select empno,ename,deptno from emp where trunc(hiredate)='03-12月-81'; SQL> select * from table(dbms_xplan.display); #修改SQL防止函数对索引的影响 SQL> explain plan for select empno,enmae,deptno from emp where hiredate>'03-12月-81' and hiredate < to_date('03-12月-81')+0.999999); 3.比较不匹配数据类型 SQL> explain plan for select bank_name,address,city,state,zip from banks where zip=100043; SQL> select * from table(dbms_xplan.display); 选择性:选择性高指不同的值越多,使用索引返回的数据量越少。 集群因子:集群因子是通过一个索引扫描一张表,需要访问表的数据块数量。 #查询索引的二元高度 SQL> select blevel,index_name from user_indexes where index_name='EMP_DEPARTMENT_IX'; #收集表employees包含直方图的统计信息 SQL> exec dbms_stats.gather_table_stats('HR','EMPLOYEES',METHOD_OPT=>'FOR COLUMNS SIZE 10 job_id'); #对emp表建立索引 SQL> conn scott/oracle; SQL> create index emp_ename_idx on emp(ename); #查询索引信息 SQL> col index_name for a20; SQL> col index_type for a10; SQL> col table_name for a20; SQL> col tablespace_name for a20; SQL> select index_name,index_type,table_name,tablespace_name from user_indexes; #查询索引对应的表空间信息 SQL> select a.index_name,a.tablespace_name,b.file_name from dba_indexes a,dba_data_files b where a.index_name like 'EMP%' and a.tablespace_name = b.tablespace_name; #创建索引表空间 SQL> conn system/oracle; SQL> create tablespace index_tbs datafile '/u01/app/oracle/oradata/orcl/index_tbs1.dbf' size 100M autoextend on; #创建表多列索引 SQL> create index emp_ename_sal_idx on emp(ename,sal) tablespace index_tbs; #查看多列索引emp_ename_sal_idx信息 SQL> col index_name for a20; SQL> run select index_name,table_name,tablespace_name from user_indexes where index_name like 'EMP%'; #查询索引列信息 SQL> col column_name for a40; SQL> select index_name,table_name,column_name from user_ind_columns where index_name like 'EMP%'; #查询索引信息 SQL> col dropped for a10; SQL> rum select index_name,table_name,table_owner,dropped,tablespace_name from user_indexes; #创建位图索引,适合数据仓库 SQL> create bitmap index emp_job_bitmap_idx on emp(job); #查看位图索引 SQL> col index_name for a20; SQL> col index_type for a20; SQL> col table_name for a10; SQL> select index_name,index_type,table_name,status from user_indexes where index_name like 'EMP%'; #创建cluster表,hash索引适合数据仓库 SQL> create cluster credit_cluster(card_no varchar2(16),transdate date sort) hashkeys 10000 hash is ora_hash(card_no) size 2186; SQL> create table credit_orders(card_no varchar2(16),transdate date,amount number) cluster credit_cluster(card_no,transdate); #创建反向键索引 SQL> create index emp_sal_reverse_idx on emp(sal) reverse; #查看反向键索引 SQL> select index_name,index_type,table_name from user_indexes where index_name like 'EMP%'; #创建基于upper函数的函数索引 SQL> create index dept_dname_idx on dept(upper(dname)); SQL> select upper(dname) from dept where upper(dname) = 'NEW YORK'; #通过user_indexes查看函数索引信息 SQL> col index_type for a30; SQL> select idnex_name,index_type,table_name from user_indexes where index_name like 'DEPT%'; #通过user_idx_columns查看函数索引信息 SQL> select index_name,table_name,column_name from user_ind_columns; #监控索引emp_ename_bitmapt_idx SQL> alter index emp_ename_bitmap_idx monitoring usage; SQL> select empno,ename,sal from emp where ename like 'S%'; SQL> alter index emp_ename_bitmap_idx nomonitoring usage; SQL> select index_name,table_name,monitoring,used from v$object_usage; SQL> select index_name,start_monitoring,end_monitoring from v$object_usage where index_name = 'EMP_ENAME_BITMAP_IDX'; #重建索引 SQL> alter index emp_ename_bitmap_idx rebuild; #重建索引并迁移表空间 SQL> alter index dept_dname_idx rebuild tablespace index_tbs1; SQL> select index_name,table_name,tablespace_name,status from user_indexes; #重建索引并修改存储参数 SQL> alter index emp_ename_bitmap_idx rebuild pctfree 30 storage (next 100k); #联机重建索引 SQL> alter index dept_dname_idx rebuild online; #查询当前索引参数设置 SQL> col index_name for a20; SQL> select index_name,pct_free,pct_increase,initial_extent,next_extent from user_indexes; #通过rebuild修改索引参数 SQL> alter index emp_job_bitmap_idx rebuild pctfree 30 storage (next 100k); #查看修改后索引参数 SQL> select index_name,pct_free,pct_increase,initial_extent,next_extent from user_indexes where index_name = 'emp_job_bitmap_idx'; #增加索引磁盘空间 SQL> alter index emp_job_bitmap_idx allocate extent; #查询索引区段信息 SQL> select segment_name,segment_type,tablespace_name,extents from user_segment where segment_type = 'INDEX' and segment_name like 'EMP%'; #合并索引碎片 SQL> alter index emp_job_bitmap_idx coalesce; #删除索引 SQL> drop index dept_dname_idx;
参考资料
[1] 林树泽.Oracle 11g R2 DBA操作指南[M].北京:清华大学出版社,2013
[2] Oracle中的索引详解
[3] oracle索引,索引的建立、修改、删除
[4] ORACLE索引介绍和使用
[5] Oracle 索引 详解
[6] oracle 索引
[7] Oracle 索引的分类,分析与比较....(转载)
[8] Oracle索引 详解
[9] Oracle 索引基本原理
[10] 浅谈Oracle索引
[11] oracle-索引原理
[12] oracle 的索引
[13] Oracle索引整理的详细描述
[14] oracle索引类型
[15] Oracle索引类型-参考
[16] Oracle 索引的分类
[17] [Oracle]深入研究B-树索引
[18] B树索引学习总结
[19] B树索引和位图索引
[20] Oracle B树索引概念的理解
[21] Oracle B树索引分析(B-Tree Index)
[22] 深入研究B树索引(一)
[23] ORACLE中的位图索引详解
[24] oracle位图索引
[25] Oracle 索引(位图索引)
[26] Oracle - 怎样使用B树索引和位图索引
[27] Oracle索引(B*tree与Bitmap)的学习总结
[28] Oracle基本索引的使用
[29] oracle 反向键索引的原理和用途(减少索引热点块)!
[30] Oracle中的反向索引
[31] oracle函数索引小结
[32] 深入探讨Oracle函数索引
[33] Oracle 实现基于函数的索引
[34] Oracle监控索引使用
[35] Oracle索引监控(monitor index)
[36] Oracle 索引监控与外键索引
[37] ORACLE重建索引详解
[38] oracle 重建索引方法 分析
[39] oracle重建索引
[40] Oracle 表的移动和索引的重建
[41] Oracle表与索引的分析及索引重建
[42] Oracle性能分析9:重建索引
[43] Oracle维护索引
[44] ORACLE索引的日常维护
[45] Oracle 索引的维护
[46] Oracle的分区表和Local索引创建与维护
[47] 从实例看oracle的索引监控与无效索引维护