android 如何使用SAX解析XML
今天,简单讲讲android如何使用SAX解析XML 。
昨天,我看代码时,看到了解析xml文档的代码,是使用SAX解析XML。但是我却不会使用SAX,于是在网上查找资料,最终解决了问题。这里记录一下。
解析XML的方式有很多种,大家比较熟悉的可能就是DOM解析。
DOM(文件对象模型)解析:解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以根据DOM接口来操作这个树结构了。
优点:整个文档读入内存,方便操作:支持修改、删除和重现排列等多种功能。
缺点:将整个文档读入内存中,保留了过多的不需要的节点,浪费内存和空间。
使用场合:一旦读入文档,还需要多次对文档进行操作,并且在硬件资源充足的情况下(内存,CPU)。
为了解决DOM解析存在的问题,就出现了SAX解析。其特点为:
优点:不用实现调入整个文档,占用资源少。尤其在嵌入式环境中,如android,极力推荐使用SAX解析。
缺点:不像DOM解析一样将文档长期驻留在内存中,数据不是持久的。如果事件过后没有保存数据,数据就会丢失。
使用场合:机器有性能限制。
SAX(Simple API for XML)解析器是一种基于事件的解析器,事件驱动的流式解析方式是,从文件的开始顺序解析到文档的结束,不可暂停或倒退。它的核心是事件处理模式,主要是围绕着事件源以及事件处理器来工作的。当事件源产生事件后,调用事件处理器相应的处理方法,一个事件就可以得到处理。在事件源调用事件处理器中特定方法的时候,还要传递给事件处理器相应事件的状态信息,这样事件处理器才能够根据提供的事件信息来决定自己的行为。
SAX的工作原理:简单地说就是对文档进行顺序扫描,当扫描到文档(document)开始与结束、元素(element)开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
在SAX接口中,事件源是org.xml.sax包中的XMLReader,他通过parse()方法开始解析XML文档,并根据文档内容产生事件。而事件处理器则是org.xml.sax包中的ContentHandler、DTDHandler、ErrorHandler,以及EntityResolver这四个接口。他们分别处理事件源在解析过程中产生不同类的事件(其中DTDHandler为解析文档DTD时所用)。详细介绍如下表:
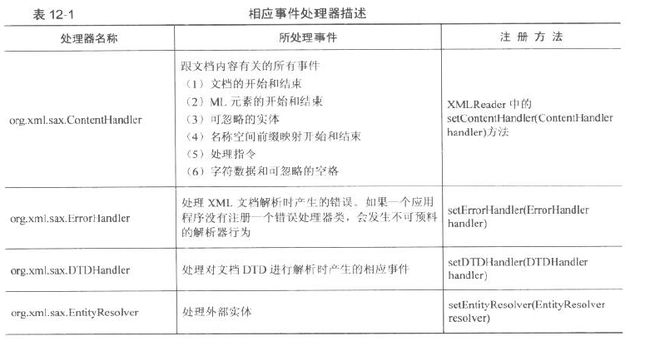
在上述四个接口中,最重要的就是ContentHandler这个接口,下面是对这个接口方法的说明:
//设置一个可以定位文档内容事件发生位置的定位器对象
public void setDocumentLocator(Locator locator)
//用于处理文档解析开始事件
public void startDocument()throws SAXException
//处理元素开始事件,从参数中可以获得元素所在名称空间的uri,元素名称,属性类表等信息
public void startElement(String namespacesURI , String localName , String qName , Attributes atts) throws SAXException
//处理元素结束事件,从参数中可以获得元素所在名称空间的uri,元素名称等信息
public void endElement(String namespacesURI , String localName , String qName) throws SAXException
//处理元素的字符内容,从参数中可以获得内容
public void characters(char[] ch , int start , int length) throws SAXException这里再介绍下XMLReader中的方法。
//注册处理XML文档解析事件ContentHandler
public void setContentHandler(ContentHandler handler)
//开始解析一个XML文档
public void parse(InputSorce input) throws SAXExceptionSAX实现实体解析的步骤:
在android中使用SAX是有迹可循的,完全可以按照下面的方法就可以轻松找到xml里的tag,然后得到想要的内容。具体实现步骤如下:
(一)第一步:新建一个工厂类SAXParserFactory,代码如下:
SAXParserFactory factory = SAXParserFactory.newInstance();
(二)第二步:让工厂类产生一个SAX的解析类SAXParser,代码如下:
SAXParser parser = factory.newSAXParser();
(三)第三步:从SAXPsrser中得到一个XMLReader实例,代码如下:
XMLReader reader = parser.getXMLReader();
(四)第四步:把自己写的handler注册到XMLReader中,一般最重要的就是ContentHandler,代码如下:
RSSHandler handler = new RSSHandler();
reader.setContentHandler(handler);
(五)第五步:将一个xml文档或者资源变成一个java可以处理的InputStream流后,解析正式开始,代码如下:
parser.parse(is);
上面几个步骤中,最重要、最关键的就是第四步,handler的实现。
接下来举一个简单的例子:
(1)首先我们拷贝一个beauties.xml文件到assets目录下,其内容如下:
范冰冰
28
杨幂
23
(2) 然后在layout下面新建一个布局文件saxtest.xml,其内容如下:
(3)在src目录下新建一个与xml里面的节点对应的一个类Beauty,内容如下:
package com.saxtest;
public class Beauty {
private String name;
private String age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAge() {
return age;
}
public void setAge(String age) {
this.age = age;
}
@Override
public String toString() {
return "美女资料 [年龄=" + age + ", 姓名=" + name + "]";
}
}
再写一个关键的类MySaxHandler,在这个类中我们将解析出来的字符串生成了Beauty对象,并加入到List中,代码已经详细注释,内容如下:
package com.saxtest;
import java.util.ArrayList;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class MySaxHandler extends DefaultHandler{
//声明一个装载Beauty类型的List
private ArrayList mList;
//声明一个Beauty类型的变量
private Beauty beauty;
//声明一个字符串变量
private String content;
/**
* MySaxHandler的构造方法
*
* @param list 装载返回结果的List对象
*/
public MySaxHandler(ArrayList list){
this.mList = list;
}
/**
* 当SAX解析器解析到XML文档开始时,会调用的方法
*/
@Override
public void startDocument() throws SAXException {
super.startDocument();
}
/**
* 当SAX解析器解析到XML文档结束时,会调用的方法
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
}
/**
* 当SAX解析器解析到某个属性值时,会调用的方法
* 其中参数ch记录了这个属性值的内容
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
super.characters(ch, start, length);
content = new String(ch, start, length);
}
/**
* 当SAX解析器解析到某个元素开始时,会调用的方法
* 其中localName记录的是元素属性名
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
if("beauty".equals(localName)){
beauty = new Beauty(); //新建Beauty对象
}
}
/**
* 当SAX解析器解析到某个元素结束时,会调用的方法
* 其中localName记录的是元素属性名
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
super.endElement(uri, localName, qName);
if("name".equals(localName)){
beauty.setName(content);
}else if("age".equals(localName)){
beauty.setAge(content);
}else if("beauty".equals(localName)){
mList.add(beauty); //将Beauty对象加入到List中
}
}
}
第三个源文件就是SaxTestActivity,这个Activity的布局文件saxtest.xml,之前已经给出过它的内容,现在我们贴出Activity源码的内容,代码都已经详细注释了:
package com.saxtest;
import java.io.InputStream;
import java.util.ArrayList;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
import android.app.Activity;
import android.content.res.AssetManager;
import android.os.Bundle;
import android.widget.TextView;
import com.example.saxtest.R;
public class SaxTestActivity extends Activity{
//声明装载Beauty对象的List
private ArrayList beautyList;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.saxtest);
//初始化beautyList链表
if(beautyList == null){
beautyList = new ArrayList();
}
doMyMission();
setupViews();
}
/**
* 使用SAX解析器解析XML文件的方法
*/
private void doMyMission(){
try {
//获取AssetManager管理器对象
AssetManager as = this.getAssets();
//通过AssetManager的open方法获取到beauties.xml文件的输入流
InputStream is = as.open("beauties.xml");
//通过获取到的InputStream来得到InputSource实例
InputSource is2 = new InputSource(is);
//使用工厂方法初始化SAXParserFactory变量spf
SAXParserFactory spf = SAXParserFactory.newInstance();
//通过SAXParserFactory得到SAXParser的实例
SAXParser sp = spf.newSAXParser();
//通过SAXParser得到XMLReader的实例
XMLReader xr = sp.getXMLReader();
//初始化自定义的类MySaxHandler的变量msh,将beautyList传递给它,以便装载数据
MySaxHandler msh = new MySaxHandler(beautyList);
//将对象msh传递给xr
xr.setContentHandler(msh);
//调用xr的parse方法解析输入流
xr.parse(is2);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 将解析结果输出到界面的方法
*/
private void setupViews(){
String result = "";
for (Beauty b : beautyList) {
result += b.toString();
}
TextView textView = (TextView) findViewById(R.id.textView);
textView.setText(result);
}
}
右键运行工程代码,结果截图如下:

简单讲讲,使用SAX解析XML 首先需要将xml字符转成InputSource输入流,然后通过下面代码获取一个XMLReader。
//使用工厂方法初始化SAXParserFactory变量spf
SAXParserFactory spf = SAXParserFactory.newInstance();
//通过SAXParserFactory得到SAXParser的实例
SAXParser sp = spf.newSAXParser();
//通过SAXParser得到XMLReader的实例
XMLReader xr = sp.getXMLReader();
然后通过xr.setContentHandler(msh);设置XMLReader解析时的监听Handler。最后调用XMLReader的parse方法解析输入流。
在MySaxHandler需要继承DefaultHandler,然后更加需要在回回调函数里做自己的逻辑。回调函数直接说了,这里在写一下:
ContentHandler接口的方法有以下几种:
void startDocument();//文档解析开始时执行
void endDocument();//文档解析结束时执行
void startElement(String uri, String localName, String qName, Attributes atts);//标签开始解析时执行
void endElement(String uri, String localName, String qName, Attributes atts);//标签解析结束时执行
void characters(char[] ch, int start, int length );//解析标签属性时执行
这样可以将解析的数组保存到自己的实体类里。具体可以看看举的例子。其实很简单。不过这里还介绍另一种函数解析XML 。
public static RESPONSESTATUS parseResponse(String xml){ RESPONSESTATUS response = null; SAXReader reader = new SAXReader(); try { Element root = reader.read(HttpUtils.str2Is(xml)).getRootElement(); if("ResponseStatus".equals(root.getName())){ response = new RESPONSESTATUS(); Iterator<Element> it = root.elementIterator(); while(it.hasNext()){ Element node = it.next(); if("requestURL".equals(node.getName())){ response.requestURL = node.getText(); }else if("statusCode".equals(node.getName())){ response.statusCode = node.getText(); } } } } catch (DocumentException e) { e.printStackTrace(); } return response; }
这里其实可能和dom解析一样,都是直接使用XMLReader直接read整个xml数据,然后逐层变量每个节点,和json解析类似。这样就不需要设置监听。
android 如何使用SAX解析XML 就讲完了。
就这么简单。