每篇一句:
You must strive to find your own voice. Because the longer you wait to begin, the less likely you are to find it at all.
--你必须努力去寻找自己的声音,因为你越迟开始寻找,找到的可能性越小。
层次聚类算法:
层次聚类算法 (Hierarchical Clustering Method)又称为系统聚类法、分级聚类法。
层次聚类算法又分为两种形式:
-
凝聚层次聚类:
首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。
-
分裂层次聚类:
首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
凝聚层次聚类:
本文介绍的为第一种形式,即凝聚层次聚类:
思路:每个样本先自成一类,然后按距离准则逐步合并,减少类数。
-
算法描述:
1)N个初始模式样本自成一类,即建立N类:
G1(0),G2(0),...,Gn(0) (G_Group)
计算 各类之间(即各样本间)的距离(相似性、相关性),得一NN维距离矩阵。“0*”表示初始状态。
2)假设已求得距离矩阵D(n)(n为逐次聚类合并的次数),找出D(n)中的最小元素,将其对应的两类合并为一类。由此建立新的分类:
G1(n+1),G2(n+1),...
3)计算合并后新类别之间的距离,得D(n+1)。
4)跳至第二步,重复计算及合并。
- 结束条件:
取距离阈值T,当D(n)的最小分量超过给定值T时,算法停止。所得即为聚类结果。
或不设阈值T,一直将全部样本聚成一类为止,输出聚类的分级树。
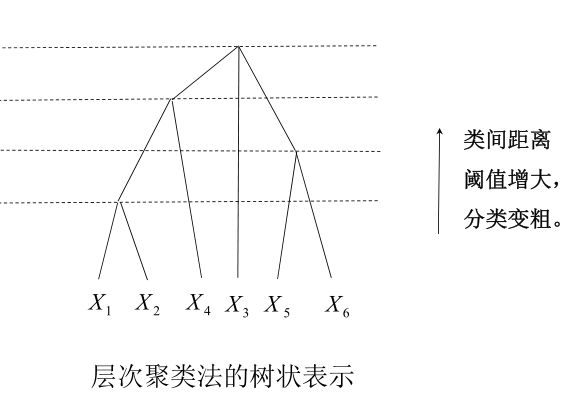 分类结果
分类结果 - 结束条件:
问题讨论:——类间距离计算准则
在算法描述第一步中提到要计算每个聚类之间的距离,在层次聚类算法中,计算聚类距离间距的计算方法主要有以下五种:
-
1)最短距离法: (常用)
如H、K是两个聚类,则两类间的最短距离定义为:
Dhk = min{D(Xh,Xk)} Xh∈H,Xk∈K
Dhk: H类中所有样本与K类中所有样本之间的最小距离。
D(Xh,Xk): H类中的某个样本Xh和K类中的某个样本Xk之间的欧式距离。
 类间距离
类间距离如果K类由I和J两类合并而成,则:
Dhi = min{D(Xh, Xi)} Xh∈H,Xi∈I
Dhj = min{D(Xh, Xj)} Xh∈H,Xj∈J得到递推公式:
Dhk = min{Dhi, Dhj}
 类间距离递推
类间距离递推
-
2) 最长距离法:
 最长距离法
最长距离法
-
3)中间距离法:
介于最长与最短的距离之间。如果 K 类由 I 类和 J 类合并而成,则 H 和 K 类之间的距离为:
 中间距离法
中间距离法
-
4)重心法:
将每类中包含的样本数考虑进去。若 I 类中有 n I 个样本, J 类中有 n J 个样本,则类与类之间的距离递推式为:
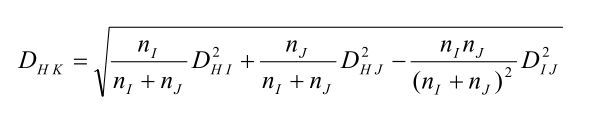 重心法
重心法
-
5)类平均距离法:
 类平均距离法
类平均距离法
定义类间距离的方法不同,分类结果会不太一致。实际问题中常用几种不同的方法,比较分类结果,从而选择一个比较切合实际的分类。
Python 实现:
- 解释说明见代码中注释
# coding=utf-8
from max_min_cluster import get_distance
def hierarchical_cluster(data, t):
# N个模式样本自成一类
result = [[aData] for aData in data]
step2(result, t)
return result
def step2(result, t):
# 记录类间最小距离
min_dis = min_distance(result[0], result[1]) # 初始为1,2类之间的距离
# 即将合并的类
index1 = 0
index2 = 1
# 遍历,寻找最小类间距离
for i in range(len(result)):
for j in range(i+1, len(result)):
dis_temp = min_distance(result[i], result[j])
if dis_temp < min_dis:
min_dis = dis_temp
# 记录即将合并的聚类位置下标
index1 = i
index2 = j
# 阈值判断
if min_dis <= t:
# 合并聚类index1, index2
result[index1].extend(result[index2])
result.pop(index2)
# 迭代计算,直至min_dis>t为止
step2(result, t)
def min_distance(list1, list2):
# 计算两个聚类之间的最小距离:
# 遍历两个聚类的所有元素,计算距离(方法较为笨拙,有待改进)
min_dis = get_distance(list1[0], list2[0])
for i in range(len(list1)):
for j in range(len(list2)):
dis_temp = get_distance(list1[i], list2[j]) # get_distance()函数见另一篇博文《聚类算法——最大最小距离算法》
if dis_temp < min_dis:
min_dis = dis_temp
return min_dis
# 测试hierarchical_cluster
# data = [[0, 3, 1, 2, 0], [1, 3, 0, 1, 0], [3, 3, 0, 0, 1], [1, 1, 0, 2, 0],[3, 2, 1, 2, 1], [4, 1, 1, 1, 0]]
# t = math.sqrt(5.5)
# result = hierarchical_cluster(data, t)
# for i in range(len(result)):
# print "----------第" + str(i+1) + "个聚类----------"
# print result[i]
# 结果为:
# ----------第1个聚类----------
# [[0, 3, 1, 2, 0], [1, 3, 0, 1, 0], [1, 1, 0, 2, 0]]
# ----------第2个聚类----------
# [[3, 3, 0, 0, 1]]
# ----------第3个聚类----------
# [[3, 2, 1, 2, 1], [4, 1, 1, 1, 0]]
**注: **
- 本次代码实现中采取的类间距离计算准则为最短距离法,但并未采取文中介绍的递推公式,而是采取的较为简单的遍历方式,数据量较大时,算法效率较低,读者有时间的话可以思考尝试所介绍的递推方式。
最后:
本文简单的介绍了 聚类算法——层次聚类算法 中 凝聚层次聚类 的相关内容,以及相应的代码实现,如果有错误的或者可以改进的地方,欢迎大家指出。
代码地址:聚类算法——层次聚类算法(码云)
原文地址:聚类算法——层次聚类算法,也是本人的CSDN账号,欢迎关注,博客会第一时间在CSDN更新。