结合Apache Kafka生态系统,谈谈2018年机器学习5大趋势

云栖君导读:让我们来研究下Uber和Netflix上的KSQL,ONNX,AutoML和机器学习平台,看看它们之间是如何相互关联的。
在2018慕尼黑OOP会议上,我展示了使用Apache Kafka生态系统和深度学习框架(如TensorFlow,DeepLearning4J)构建可扩展关键型(mission- critical)任务微服务的最新版本。本文中,我想分享出最新的幻灯片并讨论最新趋势。
本博文的主要内容与我在Confluent Blog中写的关于Apache Kafka生态系统和机器学习文章一样,但这里我更关注深度学习/神经网络。我还讨论了Apache Kafka生态系统中的一些创新以及机器学习最近几个月的趋势:Uber和Netflix上的KSQL,ONNX,AutoML和机器学习平台。下面,让我们来看看这些有趣的平台以及它们之间是如何相互关联的。
KSQL:Apache Kafka上的流式SQL语言
根据这篇文章(https://www.confluent.io/blog/ksql-open-source-streaming-sql?spm=a2c4e.11153959.blogcont507388.15.33b53218bbuEnD )可知:
“KSQL是Apache Kafka上的流式SQL引擎,KSQL降低了流处理领域的门槛,为Kafka中的数据处理提供了一个简单且完全交互的SQL接口,并且不再需要用诸如Java或Python编程语言编写代码!KSQL是一个开放源码(Apache 2.0 licensed),具有分布式,可扩展,可靠和实时等特性。它支持大量的流处理操作,包括聚合,连接,窗口化,会话等等。”
你可以编写类似SQL查询的语句来部署可伸缩的关键型流处理app(利用Kafka Streams底层技术)——这绝对是Kafka开源生态系统中的一大亮点。
KSQL和机器学习
KSQL是在Kafka Streams基础之上构建的,因此允许构建可扩展的关键型服务,它还包括神经网络在内的机器学习模型可通过构建用户自定义函数(UDF)轻松的嵌入。这些天我正在准备一个例子:将一个神经网络(更确切地说是一个自动编码器)用于传感器分析对异常进行检测,例如:实时检测病人健康检查中的健康临界值,以便向医生发送警报。
现在我们来谈谈机器学习生态系统中一些比较有意思的新发展。
ONNX:代表深度学习模式的开放版本
根据ONNX官网可知:
“ONNX代表着深度学习模式的开放版本,采用ONNX,AI开发人员可以更轻松地在各种最先进的工具之间对模型进行迁移,并选择最适合他们的组合。”
这听起来与PMML(预测模型标记语言,更多细节请参阅本文)和PFA(便携式格式分析)类似,这两个标准用于定义和共享机器学习模型。然而,ONNX在几个方面有所不同:
1.ONNX专注于深度学习。
2.ONNX有几家巨型科技公司(AWS,微软,Facebook)和硬件厂商(AMD,NVidia,Intel,Qualcomm)在使用。
3.ONNX已经支持许多较为领先的开源框架(TensorFlow,Pytorch,MXNet)。
4.ONNX已经是GA版本1.0,并且可以在生产环境中使用(2017年12月由亚马逊,微软和Facebook声明)。对于不同的框架来说是一个很好的入门指南。
ONNX和Apache Kafka生态系统
不幸的是,ONNX还不支持Java。 因此,目前还不支持将它嵌入到Kafka Streams Java API本地——只能通过一种解决方法:执行REST调用或嵌入JNI绑定。但我相信这只是时间问题,因为Java平台对许多企业部署关键任务应用程序来说非常重要。
现在,你可以使用Kafka的Java API或其他Kafka客户端。Confluent Blog为多种编程语言提供了官方客户端,如Python或Go,这两种编程语言都适用于机器学习应用程序。
自动机器学习(AKA AutoML)
如此处所述:
“自动机器学习(AutoML)是一个炙手可热的新领域,旨在使您轻松选择不同的机器学习算法,其参数设置和预处理方法提高了在大数据中检测复杂模式的能力。”
使用AutoML,你不需要学习任何关于机器学习的知识就可以构建分析模型。 AutoML使用决策树、聚类、神经网络等不同的实现方式来构建和比较不同模型,AutoML支持即开即用。你只需要上传或连接历史数据集,然后单击几个按钮即可启动该过程——不一定对于每种用例来说都是完美的,但是你可以很轻松的改进许多现有的流程,而无需使用罕见且昂贵的数据科学家。
DataRobot和Google AutoML是这个领域众多知名云产品中的两个。H2O AutoML被集成到其开源的机器学习框架中,同时它们也提供了一个非常好的基于UI的商业产品,称为无人驾驶汽车AI。我强烈建议在任何一个AutoML工具上花费30分钟的时间来研究下,来看看现在的人工智能工具如何发展,这真的很吸引人。
AutoML和Apache Kafka生态系统
大多数AutoML工具都提供了模型的部署。你可以访问分析模型,即通过一个REST接口,而不是像Kafka可扩展的事件驱动架构这样的的完美解决方案。 有一个好消息就是:许多AutoML解决方案还允许导出其生成的模型,以便将它们部署到你的应用程序中。例如,在H2O开源框架中的AutoML只是众多选择之一。您只需在你选择的编程语言(R,Python,Scala,Web UI)中使用另外一个操作:

这和构建线性回归方法、决策树或神经网络比较类似。其结果是生成的Java代码,你可以很轻松地将其嵌入到Kafka Streams微服务或任何其他的Kafka应用程序中去。借助AutoML,你无需对机器学习有特别深入的了解,同样也可以构建和部署高度可扩展的机器学习。
ML平台:Uber的Michelangelo平台; Netflix的Meson平台
科技巨头通常比“传统企业”早几年,他们早在几年前就已经建立了你今天或明天想要建造的东西。同样,ML平台也不例外。编写一个来训练分析模型的机器学习源代码只是真实世界ML基础设施中非常小的一部分。你需要考虑整个开发过程,下图显示了ML系统中隐藏的技术结构:
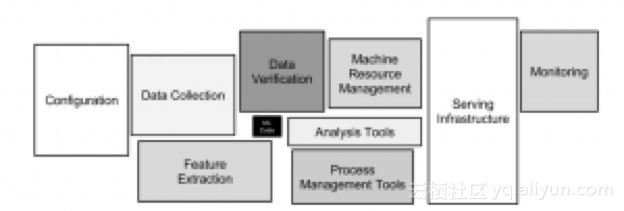
你可能会用不同的技术来构建几个分析模型,并非所有内容都将在你的Spark、Flink聚类或单个云基础架构中构建。你可以在公共云中的一些大而昂贵的GPU上运行TensorFlow来构建强大的神经网络。又或者你可以使用H2O构建立一些小的,但非常有效率和高性能的决策树,它能在几微秒内做出推断。 ML有许多应用用例。
这就是为什么许多科技巨头已经建立了自己的ML平台,如Uber的Michelangelo或Netflix的Meson。这些ML平台允许他们构建和监控强大的可扩展分析模型,同时也能够灵活地为每个用例选择正确的ML技术。
应用于ML平台的Apache Kafka生态系统
Apache Kafka能够取得如此成功的原因之一就是它被很多科技巨头广泛使用。几乎所有伟大的硅谷公司,如LinkedIn,Netflix,Uber和eBay都在谈论他们将Kafka作为其关键任务应用的中枢神经系统。许多人专注于分布式信息流平台,但是我们也看到越来越多的附加组件被采用,如Kafka Connect,Kafka Streams,REST Proxy,Schema Registry以及KSQL。
再看看上面的图片,想一想:Kafka不适合ML平台吗?它可以进行训练,监控,部署,推理,配置,A / B测试等。这也许就是Uber,Netflix和其他许多公司已经将Kafka作为ML基础设施核心组件的原因。

这一次,你不会被迫只使用一种特定的技术。Kafka最棒的设计理念之一就是:你可以一次又一次地从它的分布式提交日志中重新处理数据,这就意味着可以使用一种技术构建不同的模型作为Kafka接收器(比如Apache Flink或Spark),或者连接不同的技术,如:用于本地测试的scikit-learn,运行在Google Cloud GPU上实现强大的深度学习的TensorFlow,用于AutoML的H2O节点的部署安装,以及其它的部署在Docker容器或Kubernetes中Kafka Streams ML的一些应用程序。所有这些ML应用程序都会按照自己的步调并行地使用数据,不过他们经常性的必须这么做。
这个例子很好的说明了如何使用Kafka和Kafka Streams来自动训练以及对可扩展ML微服务的部署。它没有必要再添加另一个大数据集群,这就是在你的ML应用程序上使用Kafka Streams或KSQL代替其他流处理框架的主要区别之一。
Apache Kafka和深度学习:OOP会议上的幻灯片
在对Apache Kafka生态系统和机器学习/深度学习的新趋势的所有讨论的同时,也展示了作者在OOP 2018会议上的演讲中展示幻灯片,幻灯片请点击此处观看(https://dzone.com/articles/5-machine-learning-trends-2018-combined-with-apach?spm=a2c4e.11153959.blogcont507388.34.493e3218ggyLiJ )。
我还使用了Apache Kafka,Kafka Streams以及不同的开源ML框架(如H2O,TensorFlow和DeepLearning4j(DL4J))构建了一些示例。GitHub项目显示了将分析模型部署到高度可扩展的容错任务关键型Kafka微服务上是一件很容易的事。我们也很快将会推出一个KSQL演示。
本文由阿里云云栖社区组织翻译。
文章原标题《5 Machine Learning Trends for 2018 Combined With Apache Kafka Ecosystem》,译者:Mags,审校:袁虎。
原文地址:https://dzone.com/articles/how-to-create-java-nlp-apps-using-google-nlp-api?spm=a2c4e.11153959.blogcont507388.38.493e3218QYkyMB
作者信息:

end
758.6G每秒:阿里云成功防御国内最大规模Memcached DDoS反射攻击
5种最流行的AI编程语言
阿里巴巴开始招实习生了
阿里巴巴Android开发手册正式发布
更多精彩
