LRU使用LinkedHashMap实现(主要分析LinkedHashMap的原理)
LC上有这么一道题让实现一个LRU,LRU如上描述就是一个有容量限制当容量满时会自动移除最后一次时间时间最晚的缓存结构。
想到Redis中的ZSET结构(主要是想到了昨天学的漏斗限流…),不过只能存储key不能存储value…
在Java中也有排序表的结构,可以使用一个TreeMap,key为一个HashMap,HashMap存储题目中的key和value,TreeMap的value为操作时间戳,每访问一次或者修改一次就更新。如果超出容量设定了就移除时间戳最靠前的那一个。
不过Java中有种更合适于干这事的结构,就是LinkedHashMap。
只使用LinkedHashMap实现代码就是这样的。
class LRUCache {
private LinkedHashMap<Integer,Integer> lhm;
public LRUCache(int capacity) {
this.lhm = new LinkedHashMap<Integer,Integer> (capacity,0.75f,true){
@Override
protected boolean removeEldestEntry(Map.Entry<Integer,Integer> eldest){
return size()>capacity;
}
};
}
public int get(int key) {
return lhm.getOrDefault(key,-1);
}
public void put(int key, int value) {
lhm.put(key,value);
}
}
不过面试如果遇到,面试官估计是想用双向链表+HashMap自己实现,当然硬核一点也阔以实现一个简易的HashMap(不过没必要,面试那么短的时间不可能写完的,除非能够全文默写滑稽)
class LRUCache_{
private static class Node{
Node pre,next;
int value,key;
Node(int val,int key){
value = val;
this.key = key;
}
}
private int capacity;
LRUCache_(int capacity){
this.capacity = capacity;
}
private Map<Integer,Node> map = new HashMap<>();
private Node head,tail;
public void put(int key,int val){
if(get(key)!=-1){
map.get(key).value = val;
}else {
Node node = new Node(val, key);
map.put(key, node);
addTail(node);
if (map.size() > capacity) {
removehead();
}
}
}
public int get(int key){
Node g = map.getOrDefault(key,null);
if(g==null)
return -1;
else{
setTail(g);
return g.value;
}
}
private void removehead(){
Node frist;
//1.解除head与它的next之间的链接
if((frist=head.next)!=null){
head.next = null;
frist.pre = null;
}
//2.解除与map的连接
map.remove(head.key);
head = frist;
}
private void addTail(Node newTail){
if(tail==null){
head=newTail;
}else {
tail.next = newTail;
newTail.pre = tail;
}
tail = newTail;
}
private void setTail(Node newTail) {
Node p = newTail.pre,t = newTail.next;
if(t==null){
return;
}
if(p==null){
t.pre = null;
head = t;
}else {
p.next = t;
t.pre = p;
}
tail.next = newTail;
newTail.pre = tail;
newTail.next = null;
tail = newTail;
}
}
LinkedHashMap
LinkedHashMap是HashMap的子类,不过它多了一个双向链表再将HashMap里的元素按照一定的顺序串起来。
先从签名下手,可以看出它是HashMap的子类,实现了Map接口
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
属性
再看属性。
双向链表头结点
transient LinkedHashMap.Entry<K,V> head;
双向链表尾节点
transient LinkedHashMap.Entry<K,V> tail;
链表的排序规则,true访问顺序,false插入顺序
final boolean accessOrder;
构造方法
然后是构造方法,一共有四个方法,一个空参,一个含初始容量大小,一个含初始容量和负载参数,一个含含初始容量和负载参数还有排序规则,最后就是传入一个Map转化为LinkedHashMap,由构造方法可见,排序规则默认为插入排序。
public LinkedHashMap() {
super();
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
Entry
从功能表现上来说,与HashMap的区别,使用双向链表将HashMap的元素串起来来保证一种顺序。
那么接着来看看这个链表结构是如何的吧。
Entry本身是HashMap链表结构的子类,需要知道的是无论是红黑树结构还是链表结构,都会维护一个链表,而且有意思的是HashMap中的TreeNode是继承了LinkedHashMap中的Entry
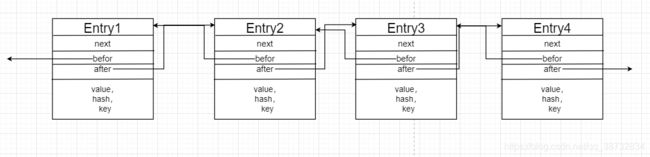
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
查找
接着看一下查部分吧,调用的HashMap中的查找功能,HashMap中使用的查询先是将Hash值映射为桶的下标,然后分为四种情况,
1.索引到的桶是空的
2.索引到的桶的头结点就是目标值,
3.桶中的为链表,则顺序查找,直到要么找到要么完全遍历。
4.桶中的为树,采用三种方式,(1).hash值不相等,用hash值确定查找的方向(2)如果本身可比较,则用利用比较确定方向 (3)深搜。
如果找不到则返回null。
如果找到了,则判断是否用访问顺序作为排序标准,如果是,则改变节点的位置。
afterNodeAccess方法是HashMap中的方法,写于HashMap中主要是方便插入时能够将新插入的节点放入合适的顺序,不过HashMap中本身是个空方法,LinkedHashMap重写了它。
将这些方法置于HashMap中主要是为了LinkedHashMap留下后路,方便的在诸如插入等方法中,将插入的节点调整到末尾,最为最后插入的节点。这种设计模式就有点像Spring中的AOP,增强方法,不过这里是绑定死的。
那么为啥HashMap不在get中插入这个方法呢,因为插入方法,无论是访问模式还是插入模式,都需要将该节点移到最后,而查找只有在访问模式下才需要,并且模式的选择是在LHM中的,不应该将此扩大到HashMap中。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
接着让我们继续来看看afterNodeAccess的具体实现。
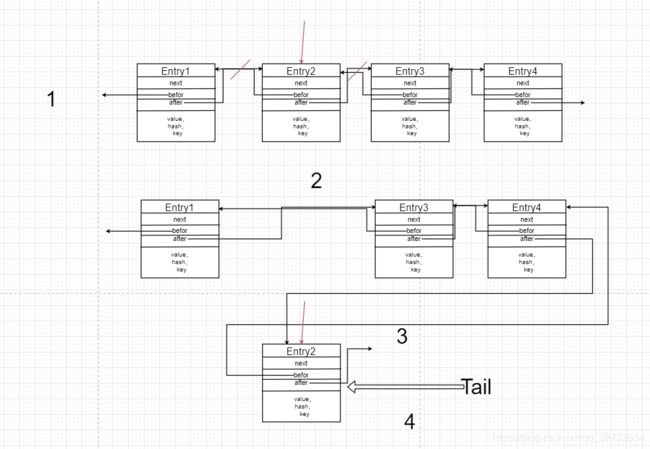
首先思考一下如果需要将一个节点(node)移动到尾部,需要进行哪些工作,1.断开原来与node之间的连接 2.并建立node前置与后置的双向连接 3.原tail的after指向node,将node的befor指向tail。4.然后再将tail设为node。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
如果node没有befor说明,
node只可能为头结点。
这时将head置为它的after节点。
if (b == null)
head = a;
else
建立b->a的连接
b.after = a;
if (a != null)
如果a不是空的,双向连接完成
a.before = b;
else
如果没有after,则将当前的临时尾结点设为e的befor。
last = b;
如果没有当前尾结点,则说明可能是第一个插入的元素
if (last == null)
head = p;
else {
如果不是第一个插入的元素,
则将e的前置设为当前尾节点,
并将当前尾结点的后置设为e。
p.before = last;
last.after = p;
}
尾结点引用指向e。
tail = p;
++modCount;
}
}
不过1和2代码的联立的。
增
put方法是直接调用HashMap里的实现,不过重写了newNode和newTreeNode方法,创建的都是Entry(TreeNode本身就是Entry的子类),而不是HashMap中原生的Node,HashMap的put方法的逻辑大概是,
1.定位桶
2.0 桶是否为空,是直接插入。
2.1.不为空,如果是链表,遍历链表如果未找到与之相等的key,则插入到尾部,满足树化条件(桶数量大于64,该桶元素数量大于8)就树化。如果找到与之相等的key,记录下该node
2.2.不为空,如果是树,定位节点可能在的位置查找,如果找到记录下该节点,未找到在底部插入,再重新平衡树。
3.0如果找到与之key相同的情况,更新该节点的值,返回原值
3.1.未找到,返回null。
而LinkeHashMap
就是在3.0时,因为有更改操作,必然需要更新尾节点为当前节点使用afterNodeAccess()方法。
在3.1时,会使用afterNodeInsertion方法,判断是否已经满足删除头结点的条件。
其中removeEldestEntry(first)函数需要自己重写,删除节点的条件,比如此题的的条件就是超出了容量。
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
evict条件若为false则为创建模式,比如反序列化的时候。
其他时候都是true。
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
删
这里删除节点主题逻辑与HashMap一致。
1.定位桶,如该桶不为空
2.查找逻辑与查找部分类似就不赘述了
3.如果目标节点存在于map中,则删除它。
3.1.如果是树结构,则先在链表中查找(树本身是链表结构的子类),移除该节点,如果达到反树化要求(小于6)就无需后续操作,未达到则还需移除树上的连接,使用该节点的右结点的最左节点替代(如果只有单个节点就更简单了,直接替代),然后平衡树。
3.2.如果是链表结构,则遍历移除
4.返回被删除键的所属节点
在LinkedHashMap中,会在第4步“插入”(用插入不太对,因为本来就在那),afterNodeRemoval方法将该节点解链。
这个方法不用多解释一看就懂。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}