impala的 join查询的优化实践
查询语句
CREATE TABLE result as SELECT t1.crossing_id AS cid,t1.plate_no AS pn1,t2.plate_no AS pn2,t1.pt_timestamp ASptts1,t2.pt_timestamp AS ptts2 FROM (select * FROM datakudu) AS t1 INNER JOIN (select * from datakudu) AS t2 ON t1.crossing_id =t2.crossing_id and t1.plate_no <> t2.plate_no AND abs(t1.pt_timestamp - t2.pt_timestamp) < 60
环境介绍:
服务器内存32G , cpu8个
3个节点的kudu集群,node1,node2,node3。这3个节点都部署了impalad,Statestored,catalogd只部署在node1之上。
表datakudu是一张存储于kudu之上的表,总共有2700W的记录数。
在没有任何优化的情况下执行上述查询需要花24小时以上的时间(这个性能显然不行,没有跑完就取消查询了)
优化1:查询语句STRAIGHT_JOIN关键字
CREATE TABLE result as SELECT STRAIGHT_JOIN t1.crossing_id AS cid,t1.plate_no AS pn1,t2.plate_no AS pn2,t1.pt_timestamp ASptts1,t2.pt_timestamp AS ptts2 FROM (select * FROM datakudu) AS t1 INNER JOIN (select * from datakudu) AS t2 ON t1.crossing_id =t2.crossing_id and t1.plate_no <> t2.plate_no AND abs(t1.pt_timestamp - t2.pt_timestamp) < 60
这次的查询时间缩短到了23小时37分钟,提升还是很明显的。
优化2: 查询之前先执行COMPUTE STATS语句来统计一下表信息,据说这样对性能提高明显。
首先执行 COMPUTE STATS hikdatakudu4
再执行
CREATE TABLE result as SELECT STRAIGHT_JOIN t1.crossing_id AS cid,t1.plate_no AS pn1,t2.plate_no AS pn2,t1.pt_timestamp ASptts1,t2.pt_timestamp AS ptts2 FROM (select * FROM datakudu) AS t1 INNER JOIN (select * from datakudu) AS t2 ON t1.crossing_id =t2.crossing_id and t1.plate_no <> t2.plate_no AND abs(t1.pt_timestamp - t2.pt_timestamp) < 60
耗时9小时
优化3:给impala分配足够的cores资源
对3个节点都需要做如下操作
1、 创建/etc/impala/conf/fair-scheduler.xml 文件,编辑如下:
50000 mb, 8 vcores
*
200000 mb, 0 vcores
user1,user2 dev,ops,admin
1000000 mb, 0 vcores
ops,admin
fair-scheduler.xml文件跟yarn中的作用一样,default是默认的队列,如果提交查询没有特殊指定队列的话都会进入default中。这里我将节点的所有8个cores都分配给了default。对于impala,如果配置了fair-scheduler.xml,那么就必须要配置llama-site.xml才能生效。配置如下
2、 创建/etc/impala/conf/ llama-site.xml 文件,编辑如下:
llama.am.throttling.maximum.placed.reservations.root.default
10
llama.am.throttling.maximum.queued.reservations.root.default
50
impala.admission-control.pool-default-query-options.root.default
mem_limit=128m,query_timeout_s=20,max_io_buffers=10
impala.admission-control.pool-queue-timeout-ms.root.default
30000
llama.am.throttling.maximum.placed.reservations.root.development
50
llama.am.throttling.maximum.queued.reservations.root.development
100
impala.admission-control.pool-default-queryoptions.root.development
mem_limit=256m,query_timeout_s=30,max_io_buffers=10
impala.admission-control.pool-queue-timeout-ms.root.development
15000
llama.am.throttling.maximum.placed.reservations.root.production
100
llama.am.throttling.maximum.queued.reservations.root.production
200
impala.admission-control.pool-default-queryoptions.root.production
mem_limit=386m,query_timeout_s=30,max_io_buffers=10
impala.admission-control.pool-queue-timeout-ms.root.production
30000
3、 修改/etc/default/impala 指定llama-site.xml,fair-scheduler.xml的路径
编辑/etc/default/impala 如下图所示
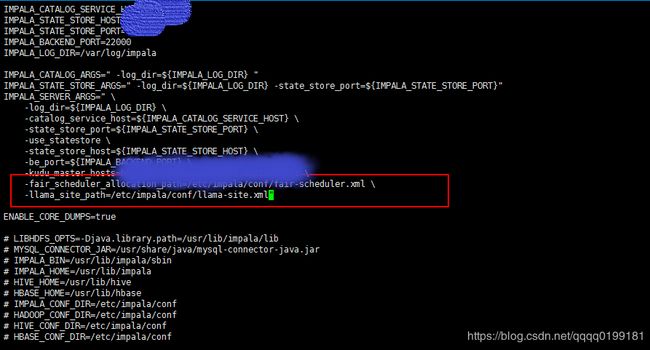
4、 重启impalad服务
service impala-server restart
5、 验证配置是否修改成功
访问http://ip:25000/varz
页面修改如下:

这次再执行sql用时优化到5小时